 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLEAD: Latent Realignment for Human Motion Diffusion
Oct 18, 2024


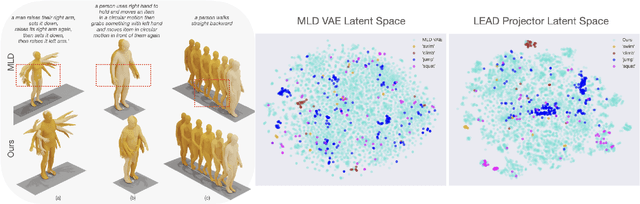
Our goal is to generate realistic human motion from natural language. Modern methods often face a trade-off between model expressiveness and text-to-motion alignment. Some align text and motion latent spaces but sacrifice expressiveness; others rely on diffusion models producing impressive motions, but lacking semantic meaning in their latent space. This may compromise realism, diversity, and applicability. Here, we address this by combining latent diffusion with a realignment mechanism, producing a novel, semantically structured space that encodes the semantics of language. Leveraging this capability, we introduce the task of textual motion inversion to capture novel motion concepts from a few examples. For motion synthesis, we evaluate LEAD on HumanML3D and KIT-ML and show comparable performance to the state-of-the-art in terms of realism, diversity, and text-motion consistency. Our qualitative analysis and user study reveal that our synthesized motions are sharper, more human-like and comply better with the text compared to modern methods. For motion textual inversion, our method demonstrates improved capacity in capturing out-of-distribution characteristics in comparison to traditional VAEs.
A Hierarchy-Aware Pose Representation for Deep Character Animation
Nov 27, 2021

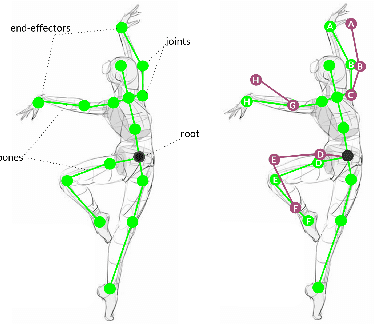

Data-driven character animation techniques rely on the existence of a properly established model of motion, capable of describing its rich context. However, commonly used motion representations often fail to accurately encode the full articulation of motion, or present artifacts. In this work, we address the fundamental problem of finding a robust pose representation for motion modeling, suitable for deep character animation, one that can better constrain poses and faithfully capture nuances correlated with skeletal characteristics. Our representation is based on dual quaternions, the mathematical abstractions with well-defined operations, which simultaneously encode rotational and positional orientation, enabling a hierarchy-aware encoding, centered around the root. We demonstrate that our representation overcomes common motion artifacts, and assess its performance compared to other popular representations. We conduct an ablation study to evaluate the impact of various losses that can be incorporated during learning. Leveraging the fact that our representation implicitly encodes skeletal motion attributes, we train a network on a dataset comprising of skeletons with different proportions, without the need to retarget them first to a universal skeleton, which causes subtle motion elements to be missed. We show that smooth and natural poses can be achieved, paving the way for fascinating applications.
Rhythm is a Dancer: Music-Driven Motion Synthesis with Global Structure
Nov 23, 2021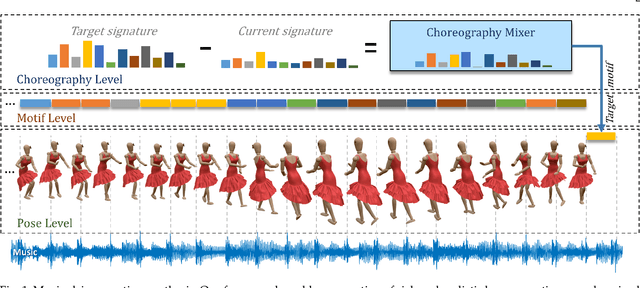
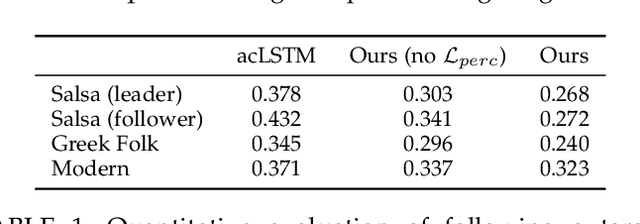
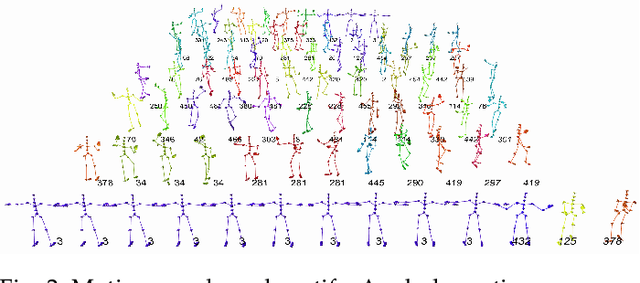
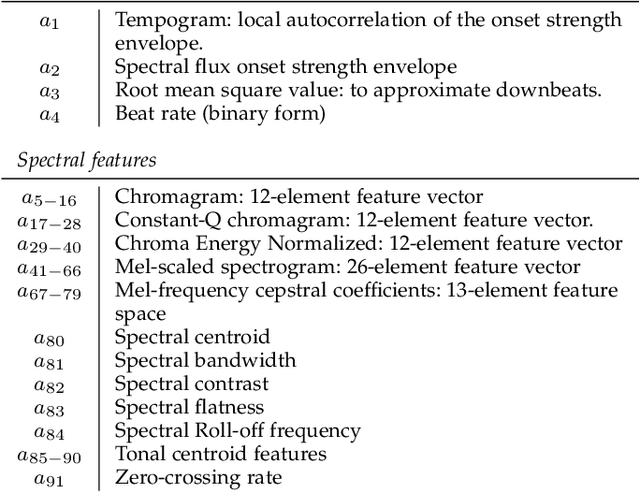
Synthesizing human motion with a global structure, such as a choreography, is a challenging task. Existing methods tend to concentrate on local smooth pose transitions and neglect the global context or the theme of the motion. In this work, we present a music-driven motion synthesis framework that generates long-term sequences of human motions which are synchronized with the input beats, and jointly form a global structure that respects a specific dance genre. In addition, our framework enables generation of diverse motions that are controlled by the content of the music, and not only by the beat. Our music-driven dance synthesis framework is a hierarchical system that consists of three levels: pose, motif, and choreography. The pose level consists of an LSTM component that generates temporally coherent sequences of poses. The motif level guides sets of consecutive poses to form a movement that belongs to a specific distribution using a novel motion perceptual-loss. And the choreography level selects the order of the performed movements and drives the system to follow the global structure of a dance genre. Our results demonstrate the effectiveness of our music-driven framework to generate natural and consistent movements on various dance types, having control over the content of the synthesized motions, and respecting the overall structure of the dance.