 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlow Models for Unbounded and Geometry-Aware Distributional Reinforcement Learning
May 07, 2025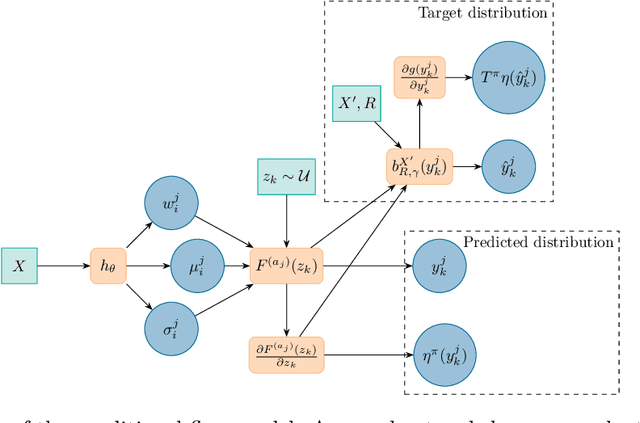
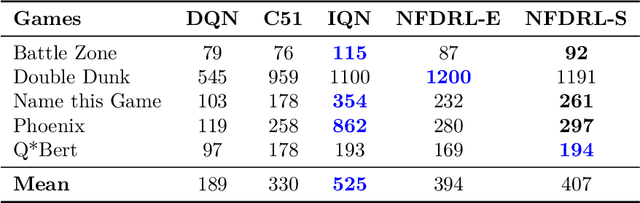

We introduce a new architecture for Distributional Reinforcement Learning (DistRL) that models return distributions using normalizing flows. This approach enables flexible, unbounded support for return distributions, in contrast to categorical approaches like C51 that rely on fixed or bounded representations. It also offers richer modeling capacity to capture multi-modality, skewness, and tail behavior than quantile based approaches. Our method is significantly more parameter-efficient than categorical approaches. Standard metrics used to train existing models like KL divergence or Wasserstein distance either are scale insensitive or have biased sample gradients, especially when return supports do not overlap. To address this, we propose a novel surrogate for the Cram\`er distance, that is geometry-aware and computable directly from the return distribution's PDF, avoiding the costly CDF computation. We test our model on the ATARI-5 sub-benchmark and show that our approach outperforms PDF based models while remaining competitive with quantile based methods.
LEAD: Latent Realignment for Human Motion Diffusion
Oct 18, 2024


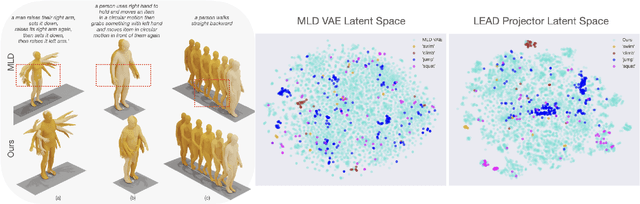
Our goal is to generate realistic human motion from natural language. Modern methods often face a trade-off between model expressiveness and text-to-motion alignment. Some align text and motion latent spaces but sacrifice expressiveness; others rely on diffusion models producing impressive motions, but lacking semantic meaning in their latent space. This may compromise realism, diversity, and applicability. Here, we address this by combining latent diffusion with a realignment mechanism, producing a novel, semantically structured space that encodes the semantics of language. Leveraging this capability, we introduce the task of textual motion inversion to capture novel motion concepts from a few examples. For motion synthesis, we evaluate LEAD on HumanML3D and KIT-ML and show comparable performance to the state-of-the-art in terms of realism, diversity, and text-motion consistency. Our qualitative analysis and user study reveal that our synthesized motions are sharper, more human-like and comply better with the text compared to modern methods. For motion textual inversion, our method demonstrates improved capacity in capturing out-of-distribution characteristics in comparison to traditional VAEs.
Analysis of Classifier-Free Guidance Weight Schedulers
Apr 19, 2024Classifier-Free Guidance (CFG) enhances the quality and condition adherence of text-to-image diffusion models. It operates by combining the conditional and unconditional predictions using a fixed weight. However, recent works vary the weights throughout the diffusion process, reporting superior results but without providing any rationale or analysis. By conducting comprehensive experiments, this paper provides insights into CFG weight schedulers. Our findings suggest that simple, monotonically increasing weight schedulers consistently lead to improved performances, requiring merely a single line of code. In addition, more complex parametrized schedulers can be optimized for further improvement, but do not generalize across different models and tasks.
See360: Novel Panoramic View Interpolation
Jan 07, 2024


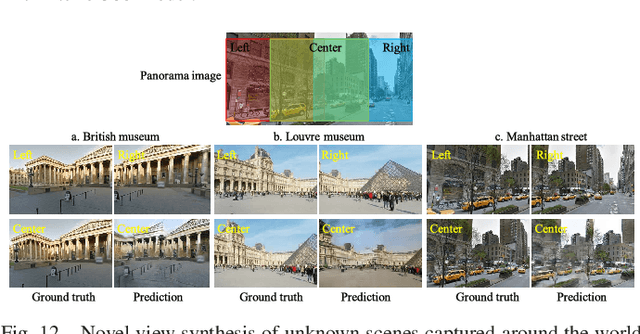
We present See360, which is a versatile and efficient framework for 360 panoramic view interpolation using latent space viewpoint estimation. Most of the existing view rendering approaches only focus on indoor or synthetic 3D environments and render new views of small objects. In contrast, we suggest to tackle camera-centered view synthesis as a 2D affine transformation without using point clouds or depth maps, which enables an effective 360? panoramic scene exploration. Given a pair of reference images, the See360 model learns to render novel views by a proposed novel Multi-Scale Affine Transformer (MSAT), enabling the coarse-to-fine feature rendering. We also propose a Conditional Latent space AutoEncoder (C-LAE) to achieve view interpolation at any arbitrary angle. To show the versatility of our method, we introduce four training datasets, namely UrbanCity360, Archinterior360, HungHom360 and Lab360, which are collected from indoor and outdoor environments for both real and synthetic rendering. Experimental results show that the proposed method is generic enough to achieve real-time rendering of arbitrary views for all four datasets. In addition, our See360 model can be applied to view synthesis in the wild: with only a short extra training time (approximately 10 mins), and is able to render unknown real-world scenes. The superior performance of See360 opens up a promising direction for camera-centered view rendering and 360 panoramic view interpolation.
* 12 pages, 10 figures
Reward Function Design for Crowd Simulation via Reinforcement Learning
Sep 22, 2023



Crowd simulation is important for video-games design, since it enables to populate virtual worlds with autonomous avatars that navigate in a human-like manner. Reinforcement learning has shown great potential in simulating virtual crowds, but the design of the reward function is critical to achieving effective and efficient results. In this work, we explore the design of reward functions for reinforcement learning-based crowd simulation. We provide theoretical insights on the validity of certain reward functions according to their analytical properties, and evaluate them empirically using a range of scenarios, using the energy efficiency as the metric. Our experiments show that directly minimizing the energy usage is a viable strategy as long as it is paired with an appropriately scaled guiding potential, and enable us to study the impact of the different reward components on the behavior of the simulated crowd. Our findings can inform the development of new crowd simulation techniques, and contribute to the wider study of human-like navigation.
UGAE: A Novel Approach to Non-exponential Discounting
Feb 11, 2023



The discounting mechanism in Reinforcement Learning determines the relative importance of future and present rewards. While exponential discounting is widely used in practice, non-exponential discounting methods that align with human behavior are often desirable for creating human-like agents. However, non-exponential discounting methods cannot be directly applied in modern on-policy actor-critic algorithms. To address this issue, we propose Universal Generalized Advantage Estimation (UGAE), which allows for the computation of GAE advantage values with arbitrary discounting. Additionally, we introduce Beta-weighted discounting, a continuous interpolation between exponential and hyperbolic discounting, to increase flexibility in choosing a discounting method. To showcase the utility of UGAE, we provide an analysis of the properties of various discounting methods. We also show experimentally that agents with non-exponential discounting trained via UGAE outperform variants trained with Monte Carlo advantage estimation. Through analysis of various discounting methods and experiments, we demonstrate the superior performance of UGAE with Beta-weighted discounting over the Monte Carlo baseline on standard RL benchmarks. UGAE is simple and easily integrated into any advantage-based algorithm as a replacement for the standard recursive GAE.
Understanding reinforcement learned crowds
Sep 19, 2022
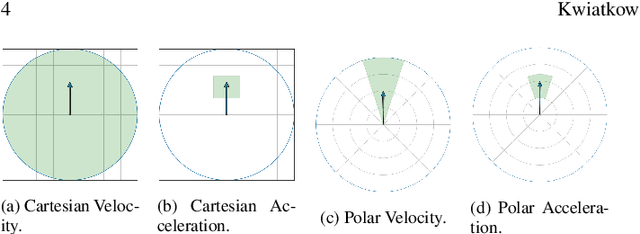
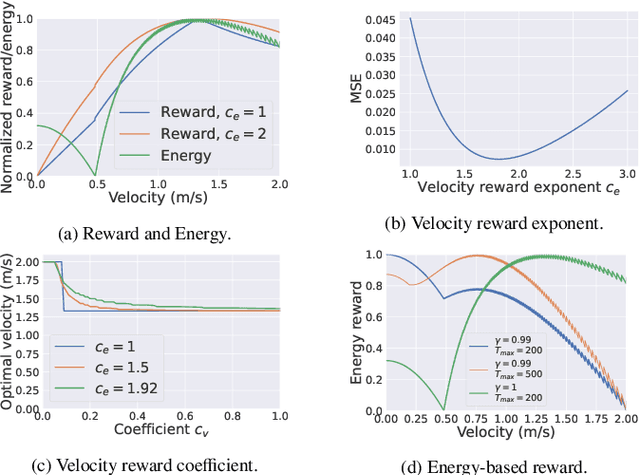
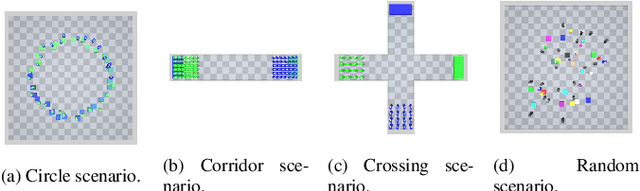
Simulating trajectories of virtual crowds is a commonly encountered task in Computer Graphics. Several recent works have applied Reinforcement Learning methods to animate virtual agents, however they often make different design choices when it comes to the fundamental simulation setup. Each of these choices comes with a reasonable justification for its use, so it is not obvious what is their real impact, and how they affect the results. In this work, we analyze some of these arbitrary choices in terms of their impact on the learning performance, as well as the quality of the resulting simulation measured in terms of the energy efficiency. We perform a theoretical analysis of the properties of the reward function design, and empirically evaluate the impact of using certain observation and action spaces on a variety of scenarios, with the reward function and energy usage as metrics. We show that directly using the neighboring agents' information as observation generally outperforms the more widely used raycasting. Similarly, using nonholonomic controls with egocentric observations tends to produce more efficient behaviors than holonomic controls with absolute observations. Each of these choices has a significant, and potentially nontrivial impact on the results, and so researchers should be mindful about choosing and reporting them in their work.
A Survey on Reinforcement Learning Methods in Character Animation
Mar 07, 2022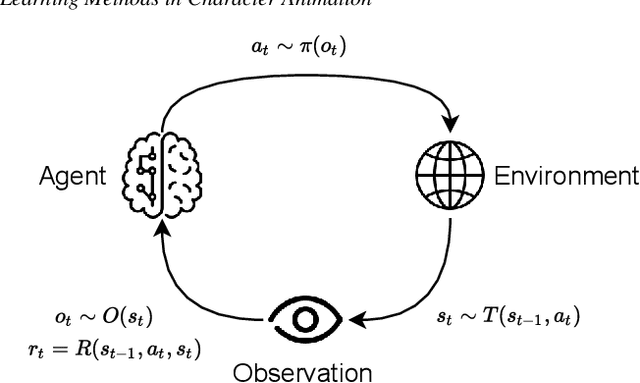
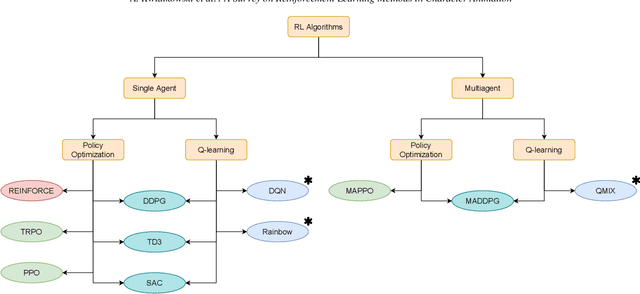
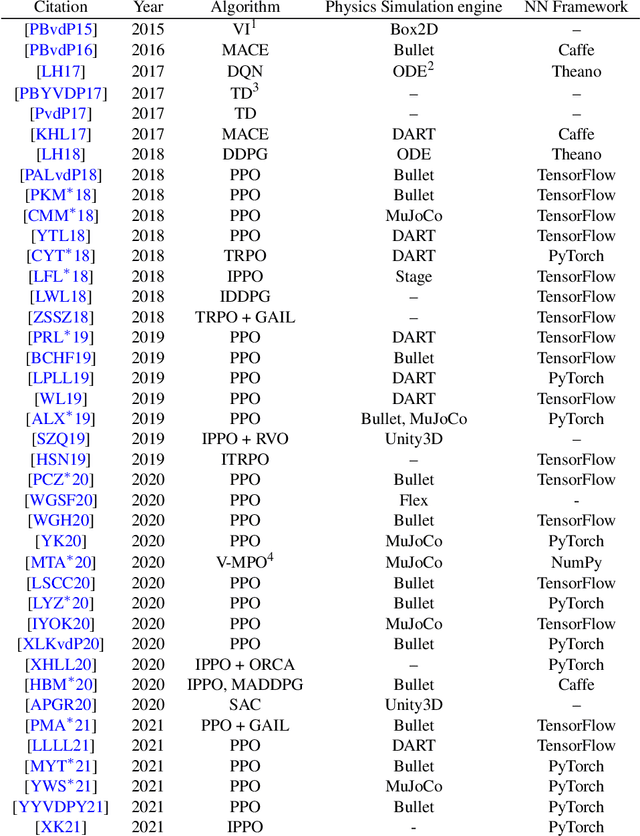
Reinforcement Learning is an area of Machine Learning focused on how agents can be trained to make sequential decisions, and achieve a particular goal within an arbitrary environment. While learning, they repeatedly take actions based on their observation of the environment, and receive appropriate rewards which define the objective. This experience is then used to progressively improve the policy controlling the agent's behavior, typically represented by a neural network. This trained module can then be reused for similar problems, which makes this approach promising for the animation of autonomous, yet reactive characters in simulators, video games or virtual reality environments. This paper surveys the modern Deep Reinforcement Learning methods and discusses their possible applications in Character Animation, from skeletal control of a single, physically-based character to navigation controllers for individual agents and virtual crowds. It also describes the practical side of training DRL systems, comparing the different frameworks available to build such agents.
Multiple Style Transfer via Variational AutoEncoder
Oct 13, 2021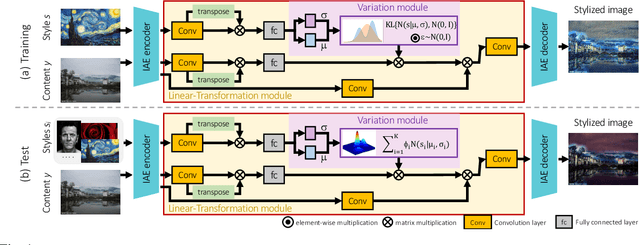



Modern works on style transfer focus on transferring style from a single image. Recently, some approaches study multiple style transfer; these, however, are either too slow or fail to mix multiple styles. We propose ST-VAE, a Variational AutoEncoder for latent space-based style transfer. It performs multiple style transfer by projecting nonlinear styles to a linear latent space, enabling to merge styles via linear interpolation before transferring the new style to the content image. To evaluate ST-VAE, we experiment on COCO for single and multiple style transfer. We also present a case study revealing that ST-VAE outperforms other methods while being faster, flexible, and setting a new path for multiple style transfer.
AIM 2020 Challenge on Real Image Super-Resolution: Methods and Results
Sep 25, 2020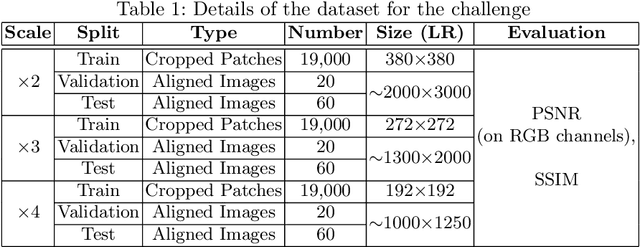
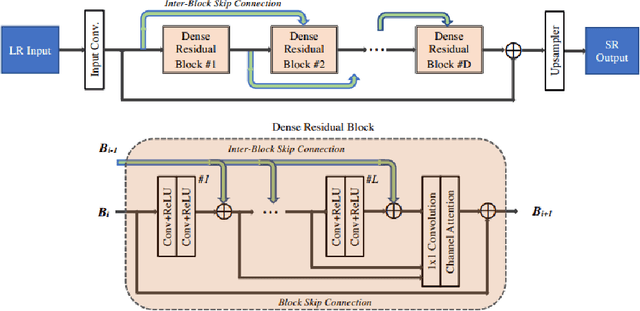
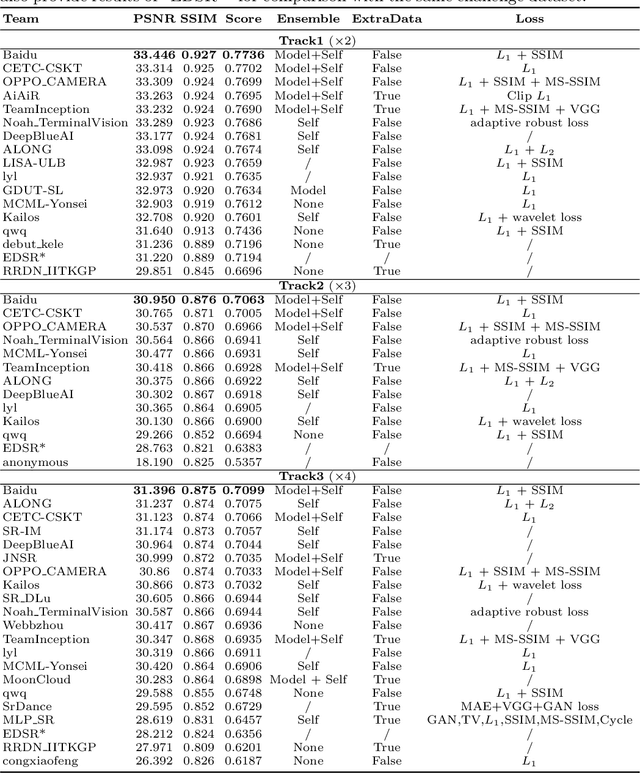
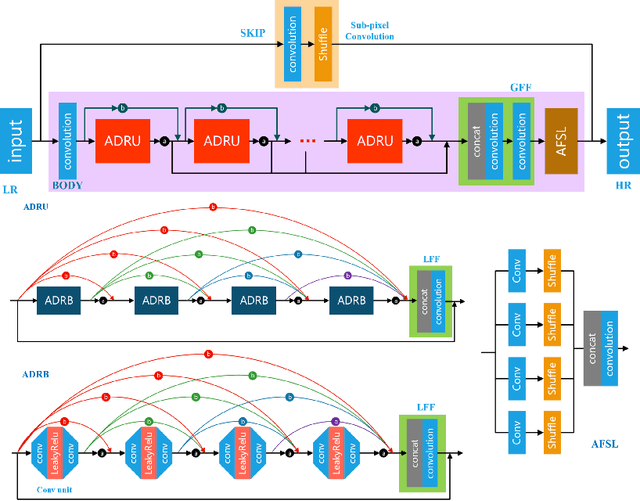
This paper introduces the real image Super-Resolution (SR) challenge that was part of the Advances in Image Manipulation (AIM) workshop, held in conjunction with ECCV 2020. This challenge involves three tracks to super-resolve an input image for $\times$2, $\times$3 and $\times$4 scaling factors, respectively. The goal is to attract more attention to realistic image degradation for the SR task, which is much more complicated and challenging, and contributes to real-world image super-resolution applications. 452 participants were registered for three tracks in total, and 24 teams submitted their results. They gauge the state-of-the-art approaches for real image SR in terms of PSNR and SSIM.