 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding reinforcement learned crowds
Paper and Code

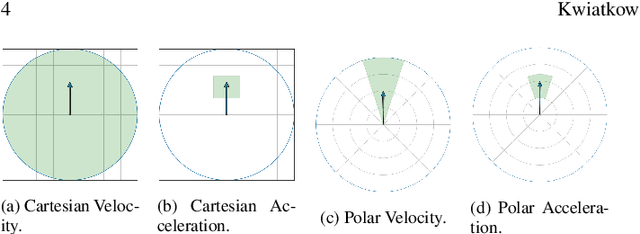
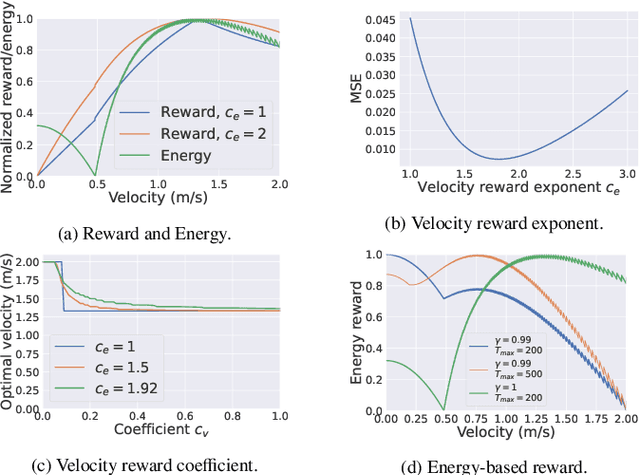
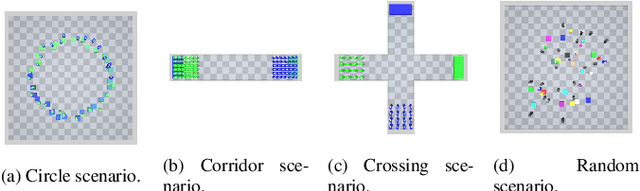
Simulating trajectories of virtual crowds is a commonly encountered task in Computer Graphics. Several recent works have applied Reinforcement Learning methods to animate virtual agents, however they often make different design choices when it comes to the fundamental simulation setup. Each of these choices comes with a reasonable justification for its use, so it is not obvious what is their real impact, and how they affect the results. In this work, we analyze some of these arbitrary choices in terms of their impact on the learning performance, as well as the quality of the resulting simulation measured in terms of the energy efficiency. We perform a theoretical analysis of the properties of the reward function design, and empirically evaluate the impact of using certain observation and action spaces on a variety of scenarios, with the reward function and energy usage as metrics. We show that directly using the neighboring agents' information as observation generally outperforms the more widely used raycasting. Similarly, using nonholonomic controls with egocentric observations tends to produce more efficient behaviors than holonomic controls with absolute observations. Each of these choices has a significant, and potentially nontrivial impact on the results, and so researchers should be mindful about choosing and reporting them in their work.