 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMIRO: MultI-Reward cOnditioned pretraining improves T2I quality and efficiency
Oct 29, 2025Current text-to-image generative models are trained on large uncurated datasets to enable diverse generation capabilities. However, this does not align well with user preferences. Recently, reward models have been specifically designed to perform post-hoc selection of generated images and align them to a reward, typically user preference. This discarding of informative data together with the optimizing for a single reward tend to harm diversity, semantic fidelity and efficiency. Instead of this post-processing, we propose to condition the model on multiple reward models during training to let the model learn user preferences directly. We show that this not only dramatically improves the visual quality of the generated images but it also significantly speeds up the training. Our proposed method, called MIRO, achieves state-of-the-art performances on the GenEval compositional benchmark and user-preference scores (PickAScore, ImageReward, HPSv2).
Pulp Motion: Framing-aware multimodal camera and human motion generation
Oct 06, 2025Treating human motion and camera trajectory generation separately overlooks a core principle of cinematography: the tight interplay between actor performance and camera work in the screen space. In this paper, we are the first to cast this task as a text-conditioned joint generation, aiming to maintain consistent on-screen framing while producing two heterogeneous, yet intrinsically linked, modalities: human motion and camera trajectories. We propose a simple, model-agnostic framework that enforces multimodal coherence via an auxiliary modality: the on-screen framing induced by projecting human joints onto the camera. This on-screen framing provides a natural and effective bridge between modalities, promoting consistency and leading to more precise joint distribution. We first design a joint autoencoder that learns a shared latent space, together with a lightweight linear transform from the human and camera latents to a framing latent. We then introduce auxiliary sampling, which exploits this linear transform to steer generation toward a coherent framing modality. To support this task, we also introduce the PulpMotion dataset, a human-motion and camera-trajectory dataset with rich captions, and high-quality human motions. Extensive experiments across DiT- and MAR-based architectures show the generality and effectiveness of our method in generating on-frame coherent human-camera motions, while also achieving gains on textual alignment for both modalities. Our qualitative results yield more cinematographically meaningful framings setting the new state of the art for this task. Code, models and data are available in our \href{https://www.lix.polytechnique.fr/vista/projects/2025_pulpmotion_courant/}{project page}.
Training-Free Synthetic Data Generation with Dual IP-Adapter Guidance
Sep 26, 2025

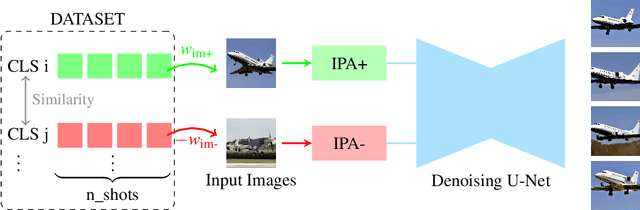

Few-shot image classification remains challenging due to the limited availability of labeled examples. Recent approaches have explored generating synthetic training data using text-to-image diffusion models, but often require extensive model fine-tuning or external information sources. We present a novel training-free approach, called DIPSY, that leverages IP-Adapter for image-to-image translation to generate highly discriminative synthetic images using only the available few-shot examples. DIPSY introduces three key innovations: (1) an extended classifier-free guidance scheme that enables independent control over positive and negative image conditioning; (2) a class similarity-based sampling strategy that identifies effective contrastive examples; and (3) a simple yet effective pipeline that requires no model fine-tuning or external captioning and filtering. Experiments across ten benchmark datasets demonstrate that our approach achieves state-of-the-art or comparable performance, while eliminating the need for generative model adaptation or reliance on external tools for caption generation and image filtering. Our results highlight the effectiveness of leveraging dual image prompting with positive-negative guidance for generating class-discriminative features, particularly for fine-grained classification tasks.
FakeParts: a New Family of AI-Generated DeepFakes
Aug 28, 2025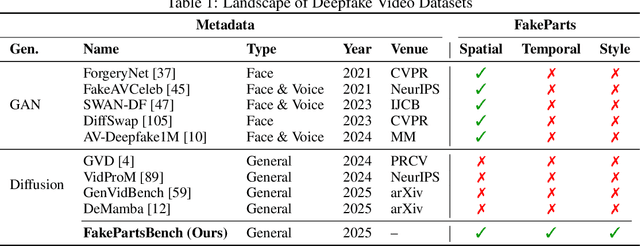
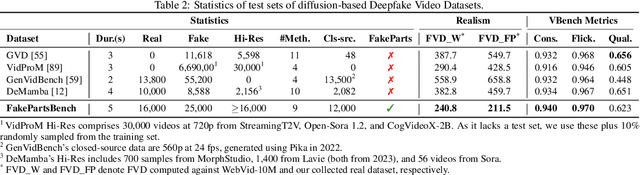
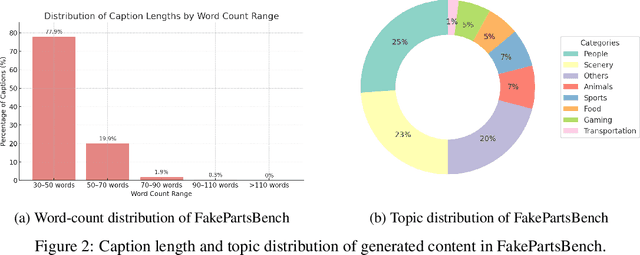
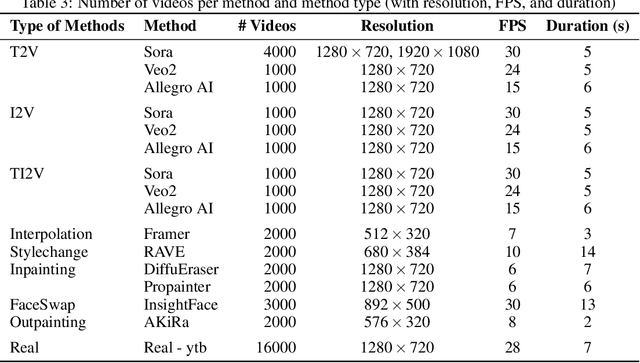
We introduce FakeParts, a new class of deepfakes characterized by subtle, localized manipulations to specific spatial regions or temporal segments of otherwise authentic videos. Unlike fully synthetic content, these partial manipulations, ranging from altered facial expressions to object substitutions and background modifications, blend seamlessly with real elements, making them particularly deceptive and difficult to detect. To address the critical gap in detection capabilities, we present FakePartsBench, the first large-scale benchmark dataset specifically designed to capture the full spectrum of partial deepfakes. Comprising over 25K videos with pixel-level and frame-level manipulation annotations, our dataset enables comprehensive evaluation of detection methods. Our user studies demonstrate that FakeParts reduces human detection accuracy by over 30% compared to traditional deepfakes, with similar performance degradation observed in state-of-the-art detection models. This work identifies an urgent vulnerability in current deepfake detection approaches and provides the necessary resources to develop more robust methods for partial video manipulations.
Studying Image Diffusion Features for Zero-Shot Video Object Segmentation
Apr 07, 2025



This paper investigates the use of large-scale diffusion models for Zero-Shot Video Object Segmentation (ZS-VOS) without fine-tuning on video data or training on any image segmentation data. While diffusion models have demonstrated strong visual representations across various tasks, their direct application to ZS-VOS remains underexplored. Our goal is to find the optimal feature extraction process for ZS-VOS by identifying the most suitable time step and layer from which to extract features. We further analyze the affinity of these features and observe a strong correlation with point correspondences. Through extensive experiments on DAVIS-17 and MOSE, we find that diffusion models trained on ImageNet outperform those trained on larger, more diverse datasets for ZS-VOS. Additionally, we highlight the importance of point correspondences in achieving high segmentation accuracy, and we yield state-of-the-art results in ZS-VOS. Finally, our approach performs on par with models trained on expensive image segmentation datasets.
Di$\mathtt{[M]}$O: Distilling Masked Diffusion Models into One-step Generator
Mar 19, 2025![Figure 1 for Di$\mathtt{[M]}$O: Distilling Masked Diffusion Models into One-step Generator](/_next/image?url=https%3A%2F%2Ffigures.semanticscholar.org%2F6c219ad77dbeec39e8440063d2e7b0d4c97cbd9a%2F6-Table1-1.png&w=640&q=75)
![Figure 2 for Di$\mathtt{[M]}$O: Distilling Masked Diffusion Models into One-step Generator](/_next/image?url=https%3A%2F%2Ffigures.semanticscholar.org%2F6c219ad77dbeec39e8440063d2e7b0d4c97cbd9a%2F3-Figure2-1.png&w=640&q=75)
![Figure 3 for Di$\mathtt{[M]}$O: Distilling Masked Diffusion Models into One-step Generator](/_next/image?url=https%3A%2F%2Ffigures.semanticscholar.org%2F6c219ad77dbeec39e8440063d2e7b0d4c97cbd9a%2F8-Table2-1.png&w=640&q=75)
![Figure 4 for Di$\mathtt{[M]}$O: Distilling Masked Diffusion Models into One-step Generator](/_next/image?url=https%3A%2F%2Ffigures.semanticscholar.org%2F6c219ad77dbeec39e8440063d2e7b0d4c97cbd9a%2F5-Figure3-1.png&w=640&q=75)
Masked Diffusion Models (MDMs) have emerged as a powerful generative modeling technique. Despite their remarkable results, they typically suffer from slow inference with several steps. In this paper, we propose Di$\mathtt{[M]}$O, a novel approach that distills masked diffusion models into a one-step generator. Di$\mathtt{[M]}$O addresses two key challenges: (1) the intractability of using intermediate-step information for one-step generation, which we solve through token-level distribution matching that optimizes model output logits by an 'on-policy framework' with the help of an auxiliary model; and (2) the lack of entropy in the initial distribution, which we address through a token initialization strategy that injects randomness while maintaining similarity to teacher training distribution. We show Di$\mathtt{[M]}$O's effectiveness on both class-conditional and text-conditional image generation, impressively achieving performance competitive to multi-step teacher outputs while drastically reducing inference time. To our knowledge, we are the first to successfully achieve one-step distillation of masked diffusion models and the first to apply discrete distillation to text-to-image generation, opening new paths for efficient generative modeling.
AKiRa: Augmentation Kit on Rays for optical video generation
Dec 18, 2024Recent advances in text-conditioned video diffusion have greatly improved video quality. However, these methods offer limited or sometimes no control to users on camera aspects, including dynamic camera motion, zoom, distorted lens and focus shifts. These motion and optical aspects are crucial for adding controllability and cinematic elements to generation frameworks, ultimately resulting in visual content that draws focus, enhances mood, and guides emotions according to filmmakers' controls. In this paper, we aim to close the gap between controllable video generation and camera optics. To achieve this, we propose AKiRa (Augmentation Kit on Rays), a novel augmentation framework that builds and trains a camera adapter with a complex camera model over an existing video generation backbone. It enables fine-tuned control over camera motion as well as complex optical parameters (focal length, distortion, aperture) to achieve cinematic effects such as zoom, fisheye effect, and bokeh. Extensive experiments demonstrate AKiRa's effectiveness in combining and composing camera optics while outperforming all state-of-the-art methods. This work sets a new landmark in controlled and optically enhanced video generation, paving the way for future optical video generation methods.
Around the World in 80 Timesteps: A Generative Approach to Global Visual Geolocation
Dec 09, 2024


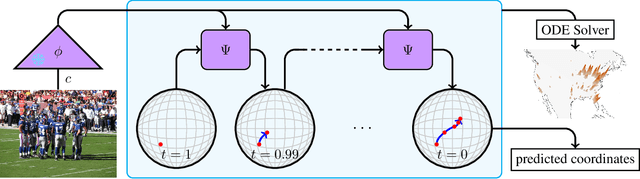
Global visual geolocation predicts where an image was captured on Earth. Since images vary in how precisely they can be localized, this task inherently involves a significant degree of ambiguity. However, existing approaches are deterministic and overlook this aspect. In this paper, we aim to close the gap between traditional geolocalization and modern generative methods. We propose the first generative geolocation approach based on diffusion and Riemannian flow matching, where the denoising process operates directly on the Earth's surface. Our model achieves state-of-the-art performance on three visual geolocation benchmarks: OpenStreetView-5M, YFCC-100M, and iNat21. In addition, we introduce the task of probabilistic visual geolocation, where the model predicts a probability distribution over all possible locations instead of a single point. We introduce new metrics and baselines for this task, demonstrating the advantages of our diffusion-based approach. Codes and models will be made available.
LEAD: Latent Realignment for Human Motion Diffusion
Oct 18, 2024


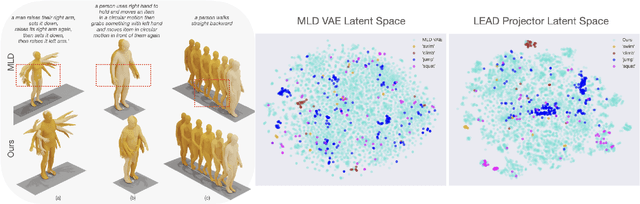
Our goal is to generate realistic human motion from natural language. Modern methods often face a trade-off between model expressiveness and text-to-motion alignment. Some align text and motion latent spaces but sacrifice expressiveness; others rely on diffusion models producing impressive motions, but lacking semantic meaning in their latent space. This may compromise realism, diversity, and applicability. Here, we address this by combining latent diffusion with a realignment mechanism, producing a novel, semantically structured space that encodes the semantics of language. Leveraging this capability, we introduce the task of textual motion inversion to capture novel motion concepts from a few examples. For motion synthesis, we evaluate LEAD on HumanML3D and KIT-ML and show comparable performance to the state-of-the-art in terms of realism, diversity, and text-motion consistency. Our qualitative analysis and user study reveal that our synthesized motions are sharper, more human-like and comply better with the text compared to modern methods. For motion textual inversion, our method demonstrates improved capacity in capturing out-of-distribution characteristics in comparison to traditional VAEs.
Bridging Text and Image for Artist Style Transfer via Contrastive Learning
Oct 12, 2024



Image style transfer has attracted widespread attention in the past few years. Despite its remarkable results, it requires additional style images available as references, making it less flexible and inconvenient. Using text is the most natural way to describe the style. More importantly, text can describe implicit abstract styles, like styles of specific artists or art movements. In this paper, we propose a Contrastive Learning for Artistic Style Transfer (CLAST) that leverages advanced image-text encoders to control arbitrary style transfer. We introduce a supervised contrastive training strategy to effectively extract style descriptions from the image-text model (i.e., CLIP), which aligns stylization with the text description. To this end, we also propose a novel and efficient adaLN based state space models that explore style-content fusion. Finally, we achieve a text-driven image style transfer. Extensive experiments demonstrate that our approach outperforms the state-of-the-art methods in artistic style transfer. More importantly, it does not require online fine-tuning and can render a 512x512 image in 0.03s.