 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePulp Motion: Framing-aware multimodal camera and human motion generation
Oct 06, 2025Treating human motion and camera trajectory generation separately overlooks a core principle of cinematography: the tight interplay between actor performance and camera work in the screen space. In this paper, we are the first to cast this task as a text-conditioned joint generation, aiming to maintain consistent on-screen framing while producing two heterogeneous, yet intrinsically linked, modalities: human motion and camera trajectories. We propose a simple, model-agnostic framework that enforces multimodal coherence via an auxiliary modality: the on-screen framing induced by projecting human joints onto the camera. This on-screen framing provides a natural and effective bridge between modalities, promoting consistency and leading to more precise joint distribution. We first design a joint autoencoder that learns a shared latent space, together with a lightweight linear transform from the human and camera latents to a framing latent. We then introduce auxiliary sampling, which exploits this linear transform to steer generation toward a coherent framing modality. To support this task, we also introduce the PulpMotion dataset, a human-motion and camera-trajectory dataset with rich captions, and high-quality human motions. Extensive experiments across DiT- and MAR-based architectures show the generality and effectiveness of our method in generating on-frame coherent human-camera motions, while also achieving gains on textual alignment for both modalities. Our qualitative results yield more cinematographically meaningful framings setting the new state of the art for this task. Code, models and data are available in our \href{https://www.lix.polytechnique.fr/vista/projects/2025_pulpmotion_courant/}{project page}.
AKiRa: Augmentation Kit on Rays for optical video generation
Dec 18, 2024Recent advances in text-conditioned video diffusion have greatly improved video quality. However, these methods offer limited or sometimes no control to users on camera aspects, including dynamic camera motion, zoom, distorted lens and focus shifts. These motion and optical aspects are crucial for adding controllability and cinematic elements to generation frameworks, ultimately resulting in visual content that draws focus, enhances mood, and guides emotions according to filmmakers' controls. In this paper, we aim to close the gap between controllable video generation and camera optics. To achieve this, we propose AKiRa (Augmentation Kit on Rays), a novel augmentation framework that builds and trains a camera adapter with a complex camera model over an existing video generation backbone. It enables fine-tuned control over camera motion as well as complex optical parameters (focal length, distortion, aperture) to achieve cinematic effects such as zoom, fisheye effect, and bokeh. Extensive experiments demonstrate AKiRa's effectiveness in combining and composing camera optics while outperforming all state-of-the-art methods. This work sets a new landmark in controlled and optically enhanced video generation, paving the way for future optical video generation methods.
E.T. the Exceptional Trajectories: Text-to-camera-trajectory generation with character awareness
Jul 01, 2024



Stories and emotions in movies emerge through the effect of well-thought-out directing decisions, in particular camera placement and movement over time. Crafting compelling camera trajectories remains a complex iterative process, even for skilful artists. To tackle this, in this paper, we propose a dataset called the Exceptional Trajectories (E.T.) with camera trajectories along with character information and textual captions encompassing descriptions of both camera and character. To our knowledge, this is the first dataset of its kind. To show the potential applications of the E.T. dataset, we propose a diffusion-based approach, named DIRECTOR, which generates complex camera trajectories from textual captions that describe the relation and synchronisation between the camera and characters. To ensure robust and accurate evaluations, we train on the E.T. dataset CLaTr, a Contrastive Language-Trajectory embedding for evaluation metrics. We posit that our proposed dataset and method significantly advance the democratization of cinematography, making it more accessible to common users.
FunnyNet-W: Multimodal Learning of Funny Moments in Videos in the Wild
Jan 08, 2024Automatically understanding funny moments (i.e., the moments that make people laugh) when watching comedy is challenging, as they relate to various features, such as body language, dialogues and culture. In this paper, we propose FunnyNet-W, a model that relies on cross- and self-attention for visual, audio and text data to predict funny moments in videos. Unlike most methods that rely on ground truth data in the form of subtitles, in this work we exploit modalities that come naturally with videos: (a) video frames as they contain visual information indispensable for scene understanding, (b) audio as it contains higher-level cues associated with funny moments, such as intonation, pitch and pauses and (c) text automatically extracted with a speech-to-text model as it can provide rich information when processed by a Large Language Model. To acquire labels for training, we propose an unsupervised approach that spots and labels funny audio moments. We provide experiments on five datasets: the sitcoms TBBT, MHD, MUStARD, Friends, and the TED talk UR-Funny. Extensive experiments and analysis show that FunnyNet-W successfully exploits visual, auditory and textual cues to identify funny moments, while our findings reveal FunnyNet-W's ability to predict funny moments in the wild. FunnyNet-W sets the new state of the art for funny moment detection with multimodal cues on all datasets with and without using ground truth information.
BluNF: Blueprint Neural Field
Sep 07, 2023Neural Radiance Fields (NeRFs) have revolutionized scene novel view synthesis, offering visually realistic, precise, and robust implicit reconstructions. While recent approaches enable NeRF editing, such as object removal, 3D shape modification, or material property manipulation, the manual annotation prior to such edits makes the process tedious. Additionally, traditional 2D interaction tools lack an accurate sense of 3D space, preventing precise manipulation and editing of scenes. In this paper, we introduce a novel approach, called Blueprint Neural Field (BluNF), to address these editing issues. BluNF provides a robust and user-friendly 2D blueprint, enabling intuitive scene editing. By leveraging implicit neural representation, BluNF constructs a blueprint of a scene using prior semantic and depth information. The generated blueprint allows effortless editing and manipulation of NeRF representations. We demonstrate BluNF's editability through an intuitive click-and-change mechanism, enabling 3D manipulations, such as masking, appearance modification, and object removal. Our approach significantly contributes to visual content creation, paving the way for further research in this area.
JAWS: Just A Wild Shot for Cinematic Transfer in Neural Radiance Fields
Mar 27, 2023



This paper presents JAWS, an optimization-driven approach that achieves the robust transfer of visual cinematic features from a reference in-the-wild video clip to a newly generated clip. To this end, we rely on an implicit-neural-representation (INR) in a way to compute a clip that shares the same cinematic features as the reference clip. We propose a general formulation of a camera optimization problem in an INR that computes extrinsic and intrinsic camera parameters as well as timing. By leveraging the differentiability of neural representations, we can back-propagate our designed cinematic losses measured on proxy estimators through a NeRF network to the proposed cinematic parameters directly. We also introduce specific enhancements such as guidance maps to improve the overall quality and efficiency. Results display the capacity of our system to replicate well known camera sequences from movies, adapting the framing, camera parameters and timing of the generated video clip to maximize the similarity with the reference clip.
Machine Learning for Brain Disorders: Transformers and Visual Transformers
Mar 21, 2023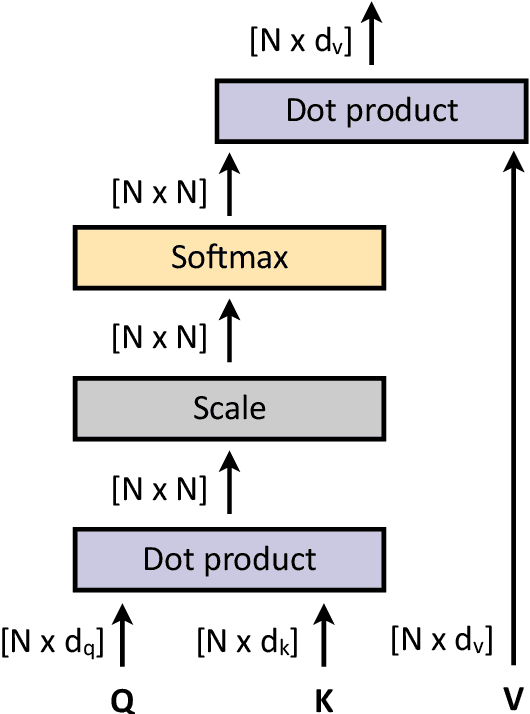
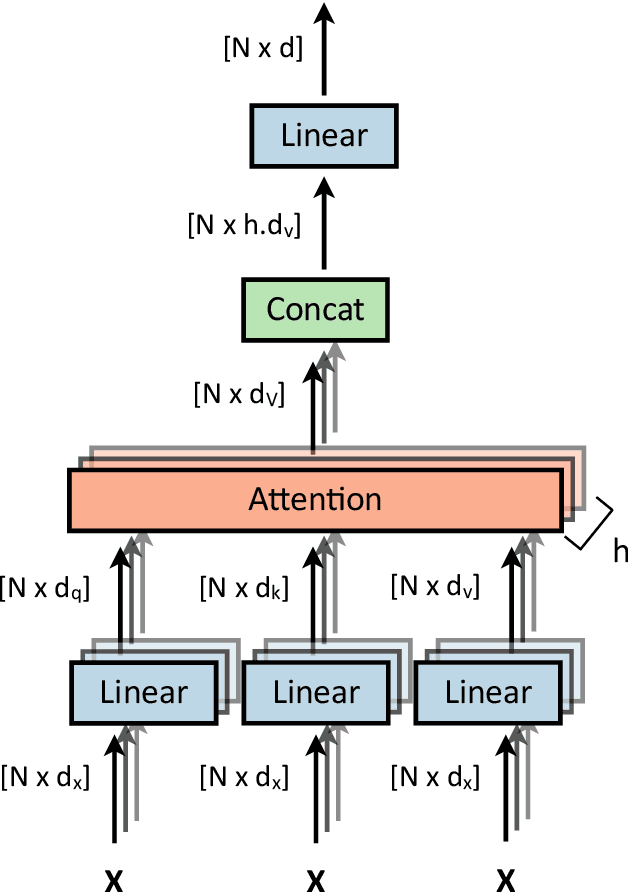
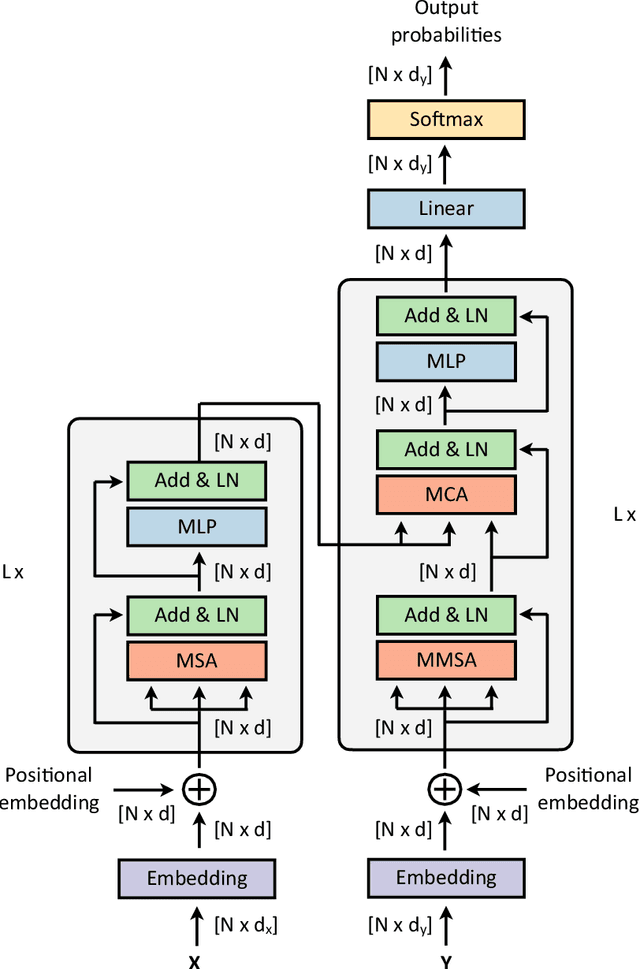
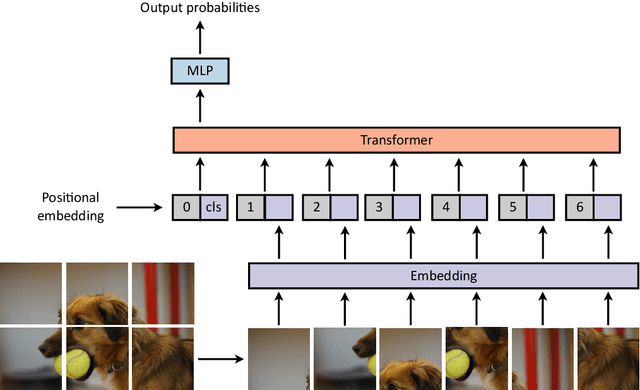
Transformers were initially introduced for natural language processing (NLP) tasks, but fast they were adopted by most deep learning fields, including computer vision. They measure the relationships between pairs of input tokens (words in the case of text strings, parts of images for visual Transformers), termed attention. The cost is exponential with the number of tokens. For image classification, the most common Transformer Architecture uses only the Transformer Encoder in order to transform the various input tokens. However, there are also numerous other applications in which the decoder part of the traditional Transformer Architecture is also used. Here, we first introduce the Attention mechanism (Section 1), and then the Basic Transformer Block including the Vision Transformer (Section 2). Next, we discuss some improvements of visual Transformers to account for small datasets or less computation(Section 3). Finally, we introduce Visual Transformers applied to tasks other than image classification, such as detection, segmentation, generation and training without labels (Section 4) and other domains, such as video or multimodality using text or audio data (Section 5).