 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLEAD: Latent Realignment for Human Motion Diffusion
Paper and Code
Oct 18, 2024


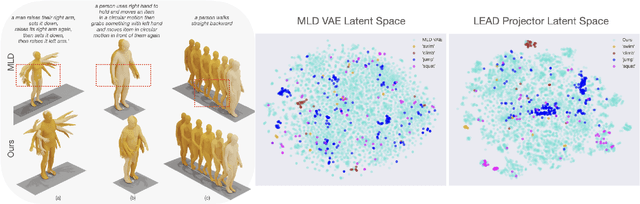
Our goal is to generate realistic human motion from natural language. Modern methods often face a trade-off between model expressiveness and text-to-motion alignment. Some align text and motion latent spaces but sacrifice expressiveness; others rely on diffusion models producing impressive motions, but lacking semantic meaning in their latent space. This may compromise realism, diversity, and applicability. Here, we address this by combining latent diffusion with a realignment mechanism, producing a novel, semantically structured space that encodes the semantics of language. Leveraging this capability, we introduce the task of textual motion inversion to capture novel motion concepts from a few examples. For motion synthesis, we evaluate LEAD on HumanML3D and KIT-ML and show comparable performance to the state-of-the-art in terms of realism, diversity, and text-motion consistency. Our qualitative analysis and user study reveal that our synthesized motions are sharper, more human-like and comply better with the text compared to modern methods. For motion textual inversion, our method demonstrates improved capacity in capturing out-of-distribution characteristics in comparison to traditional VAEs.