 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGroupRAG: Cognitively Inspired Group-Aware Retrieval and Reasoning via Knowledge-Driven Problem Structuring
Mar 26, 2026The performance of language models is commonly limited by insufficient knowledge and constrained reasoning. Prior approaches such as Retrieval-Augmented Generation (RAG) and Chain-of-Thought (CoT) address these issues by incorporating external knowledge or enforcing linear reasoning chains, but often degrade in real-world settings. Inspired by cognitive science, which characterizes human problem solving as search over structured problem spaces rather than single inference chains, we argue that inadequate awareness of problem structure is a key overlooked limitation. We propose GroupRAG, a cognitively inspired, group-aware retrieval and reasoning framework based on knowledge-driven keypoint grouping. GroupRAG identifies latent structural groups within a problem and performs retrieval and reasoning from multiple conceptual starting points, enabling fine-grained interaction between the two processes. Experiments on MedQA show that GroupRAG outperforms representative RAG- and CoT-based baselines. These results suggest that explicitly modeling problem structure, as inspired by human cognition, is a promising direction for robust retrieval-augmented reasoning.
FreeAskWorld: An Interactive and Closed-Loop Simulator for Human-Centric Embodied AI
Nov 17, 2025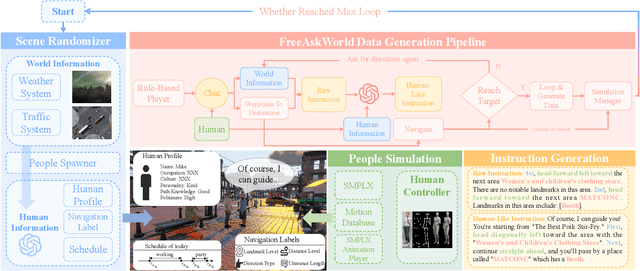
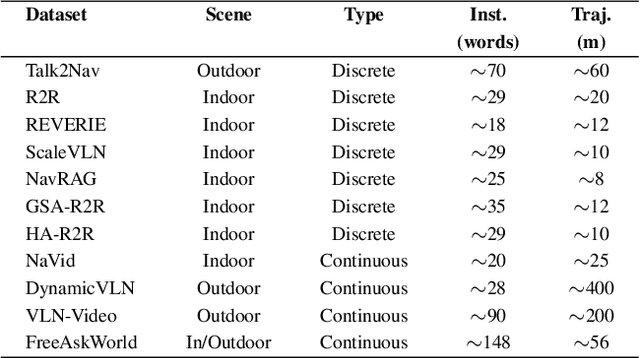
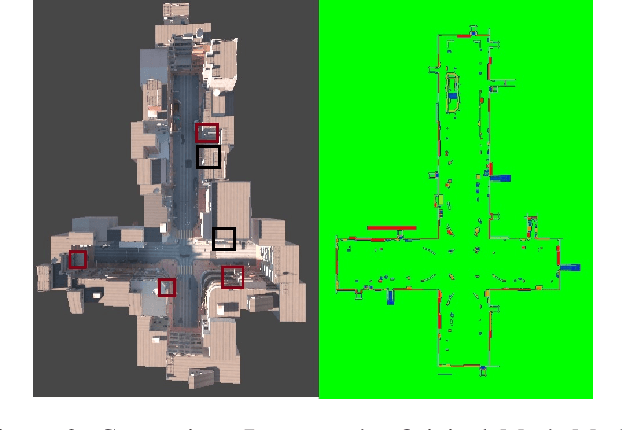
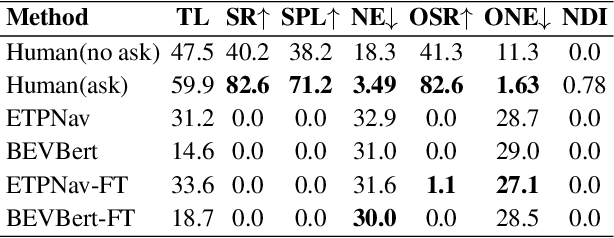
As embodied intelligence emerges as a core frontier in artificial intelligence research, simulation platforms must evolve beyond low-level physical interactions to capture complex, human-centered social behaviors. We introduce FreeAskWorld, an interactive simulation framework that integrates large language models (LLMs) for high-level behavior planning and semantically grounded interaction, informed by theories of intention and social cognition. Our framework supports scalable, realistic human-agent simulations and includes a modular data generation pipeline tailored for diverse embodied tasks.To validate the framework, we extend the classic Vision-and-Language Navigation (VLN) task into a interaction enriched Direction Inquiry setting, wherein agents can actively seek and interpret navigational guidance. We present and publicly release FreeAskWorld, a large-scale benchmark dataset comprising reconstructed environments, six diverse task types, 16 core object categories, 63,429 annotated sample frames, and more than 17 hours of interaction data to support training and evaluation of embodied AI systems. We benchmark VLN models, and human participants under both open-loop and closed-loop settings. Experimental results demonstrate that models fine-tuned on FreeAskWorld outperform their original counterparts, achieving enhanced semantic understanding and interaction competency. These findings underscore the efficacy of socially grounded simulation frameworks in advancing embodied AI systems toward sophisticated high-level planning and more naturalistic human-agent interaction. Importantly, our work underscores that interaction itself serves as an additional information modality.
* 9 pages, 4 figures
CoIRL-AD: Collaborative-Competitive Imitation-Reinforcement Learning in Latent World Models for Autonomous Driving
Oct 14, 2025End-to-end autonomous driving models trained solely with imitation learning (IL) often suffer from poor generalization. In contrast, reinforcement learning (RL) promotes exploration through reward maximization but faces challenges such as sample inefficiency and unstable convergence. A natural solution is to combine IL and RL. Moving beyond the conventional two-stage paradigm (IL pretraining followed by RL fine-tuning), we propose CoIRL-AD, a competitive dual-policy framework that enables IL and RL agents to interact during training. CoIRL-AD introduces a competition-based mechanism that facilitates knowledge exchange while preventing gradient conflicts. Experiments on the nuScenes dataset show an 18% reduction in collision rate compared to baselines, along with stronger generalization and improved performance on long-tail scenarios. Code is available at: https://github.com/SEU-zxj/CoIRL-AD.
Bench2FreeAD: A Benchmark for Vision-based End-to-end Navigation in Unstructured Robotic Environments
Mar 15, 2025Most current end-to-end (E2E) autonomous driving algorithms are built on standard vehicles in structured transportation scenarios, lacking exploration of robot navigation for unstructured scenarios such as auxiliary roads, campus roads, and indoor settings. This paper investigates E2E robot navigation in unstructured road environments. First, we introduce two data collection pipelines - one for real-world robot data and another for synthetic data generated using the Isaac Sim simulator, which together produce an unstructured robotics navigation dataset -- FreeWorld Dataset. Second, we fine-tuned an efficient E2E autonomous driving model -- VAD -- using our datasets to validate the performance and adaptability of E2E autonomous driving models in these environments. Results demonstrate that fine-tuning through our datasets significantly enhances the navigation potential of E2E autonomous driving models in unstructured robotic environments. Thus, this paper presents the first dataset targeting E2E robot navigation tasks in unstructured scenarios, and provides a benchmark based on vision-based E2E autonomous driving algorithms to facilitate the development of E2E navigation technology for logistics and service robots. The project is available on Github.
A Comprehensive LLM-powered Framework for Driving Intelligence Evaluation
Mar 07, 2025


Evaluation methods for autonomous driving are crucial for algorithm optimization. However, due to the complexity of driving intelligence, there is currently no comprehensive evaluation method for the level of autonomous driving intelligence. In this paper, we propose an evaluation framework for driving behavior intelligence in complex traffic environments, aiming to fill this gap. We constructed a natural language evaluation dataset of human professional drivers and passengers through naturalistic driving experiments and post-driving behavior evaluation interviews. Based on this dataset, we developed an LLM-powered driving evaluation framework. The effectiveness of this framework was validated through simulated experiments in the CARLA urban traffic simulator and further corroborated by human assessment. Our research provides valuable insights for evaluating and designing more intelligent, human-like autonomous driving agents. The implementation details of the framework and detailed information about the dataset can be found at Github.
* 8 pages, 3 figures
Driving Style Alignment for LLM-powered Driver Agent
Mar 17, 2024

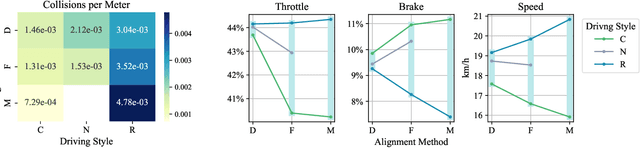
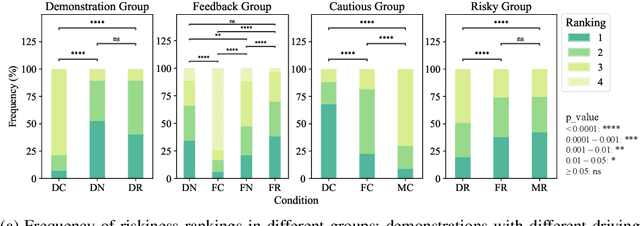
Recently, LLM-powered driver agents have demonstrated considerable potential in the field of autonomous driving, showcasing human-like reasoning and decision-making abilities.However, current research on aligning driver agent behaviors with human driving styles remains limited, partly due to the scarcity of high-quality natural language data from human driving behaviors.To address this research gap, we propose a multi-alignment framework designed to align driver agents with human driving styles through demonstrations and feedback. Notably, we construct a natural language dataset of human driver behaviors through naturalistic driving experiments and post-driving interviews, offering high-quality human demonstrations for LLM alignment. The framework's effectiveness is validated through simulation experiments in the CARLA urban traffic simulator and further corroborated by human evaluations. Our research offers valuable insights into designing driving agents with diverse driving styles.The implementation of the framework and details of the dataset can be found at the link.
Large Language Models Powered Context-aware Motion Prediction
Mar 17, 2024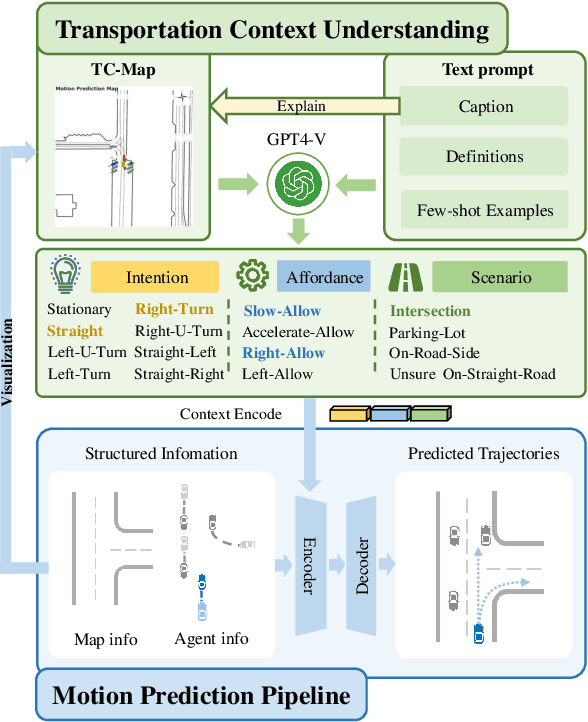
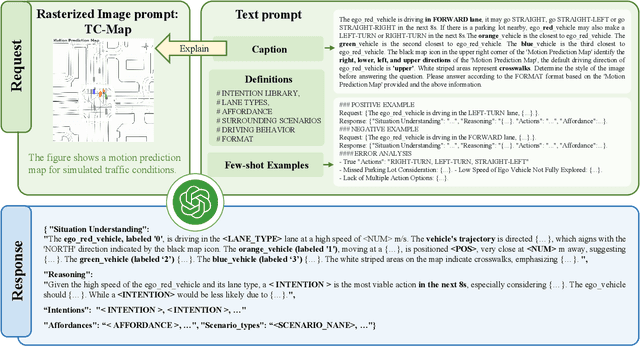
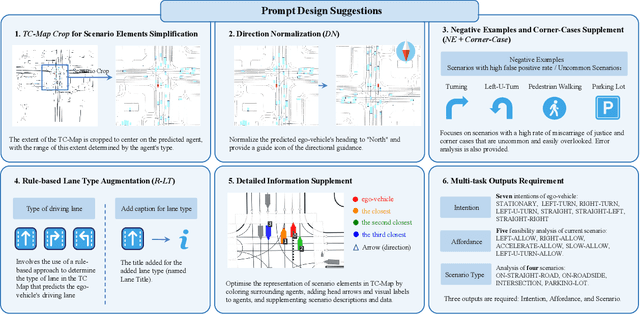
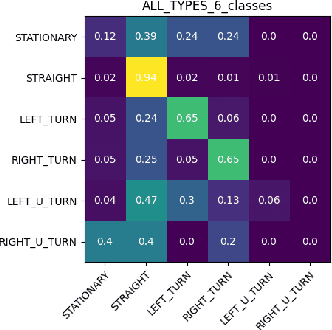
Motion prediction is among the most fundamental tasks in autonomous driving. Traditional methods of motion forecasting primarily encode vector information of maps and historical trajectory data of traffic participants, lacking a comprehensive understanding of overall traffic semantics, which in turn affects the performance of prediction tasks. In this paper, we utilized Large Language Models (LLMs) to enhance the global traffic context understanding for motion prediction tasks. We first conducted systematic prompt engineering, visualizing complex traffic environments and historical trajectory information of traffic participants into image prompts -- Transportation Context Map (TC-Map), accompanied by corresponding text prompts. Through this approach, we obtained rich traffic context information from the LLM. By integrating this information into the motion prediction model, we demonstrate that such context can enhance the accuracy of motion predictions. Furthermore, considering the cost associated with LLMs, we propose a cost-effective deployment strategy: enhancing the accuracy of motion prediction tasks at scale with 0.7\% LLM-augmented datasets. Our research offers valuable insights into enhancing the understanding of traffic scenes of LLMs and the motion prediction performance of autonomous driving.
More Than Routing: Joint GPS and Route Modeling for Refine Trajectory Representation Learning
Feb 25, 2024



Trajectory representation learning plays a pivotal role in supporting various downstream tasks. Traditional methods in order to filter the noise in GPS trajectories tend to focus on routing-based methods used to simplify the trajectories. However, this approach ignores the motion details contained in the GPS data, limiting the representation capability of trajectory representation learning. To fill this gap, we propose a novel representation learning framework that Joint GPS and Route Modelling based on self-supervised technology, namely JGRM. We consider GPS trajectory and route as the two modes of a single movement observation and fuse information through inter-modal information interaction. Specifically, we develop two encoders, each tailored to capture representations of route and GPS trajectories respectively. The representations from the two modalities are fed into a shared transformer for inter-modal information interaction. Eventually, we design three self-supervised tasks to train the model. We validate the effectiveness of the proposed method on two real datasets based on extensive experiments. The experimental results demonstrate that JGRM outperforms existing methods in both road segment representation and trajectory representation tasks. Our source code is available at Anonymous Github.
Enable Natural Tactile Interaction for Robot Dog based on Large-format Distributed Flexible Pressure Sensors
Mar 14, 2023



Touch is an important channel for human-robot interaction, while it is challenging for robots to recognize human touch accurately and make appropriate responses. In this paper, we design and implement a set of large-format distributed flexible pressure sensors on a robot dog to enable natural human-robot tactile interaction. Through a heuristic study, we sorted out 81 tactile gestures commonly used when humans interact with real dogs and 44 dog reactions. A gesture classification algorithm based on ResNet is proposed to recognize these 81 human gestures, and the classification accuracy reaches 98.7%. In addition, an action prediction algorithm based on Transformer is proposed to predict dog actions from human gestures, reaching a 1-gram BLEU score of 0.87. Finally, we compare the tactile interaction with the voice interaction during a freedom human-robot-dog interactive playing study. The results show that tactile interaction plays a more significant role in alleviating user anxiety, stimulating user excitement and improving the acceptability of robot dogs.
* 7 pages, 5 figures
"I am the follower, also the boss": Exploring Different Levels of Autonomy and Machine Forms of Guiding Robots for the Visually Impaired
Feb 07, 2023



Guiding robots, in the form of canes or cars, have recently been explored to assist blind and low vision (BLV) people. Such robots can provide full or partial autonomy when guiding. However, the pros and cons of different forms and autonomy for guiding robots remain unknown. We sought to fill this gap. We designed autonomy-switchable guiding robotic cane and car. We conducted a controlled lab-study (N=12) and a field study (N=9) on BLV. Results showed that full autonomy received better walking performance and subjective ratings in the controlled study, whereas participants used more partial autonomy in the natural environment as demanding more control. Besides, the car robot has demonstrated abilities to provide a higher sense of safety and navigation efficiency compared with the cane robot. Our findings offered empirical evidence about how the BLV community perceived different machine forms and autonomy, which can inform the design of assistive robots.