 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Open-Vocabulary 3D Scene Graphs for Long-term Language-Guided Mobile Manipulation
Oct 17, 2024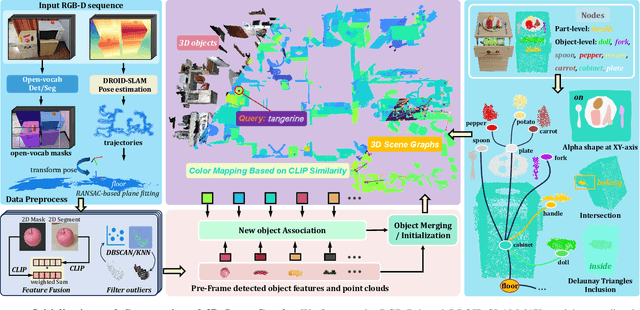
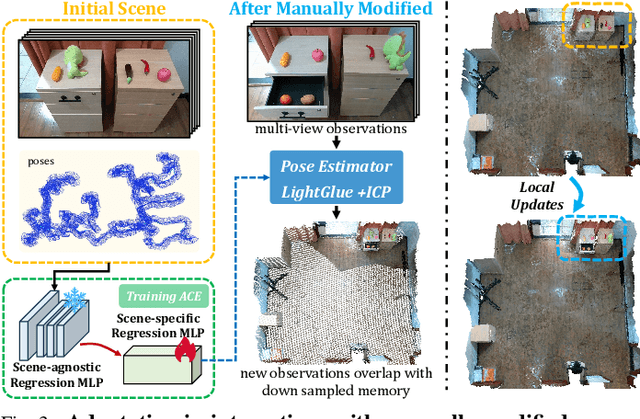
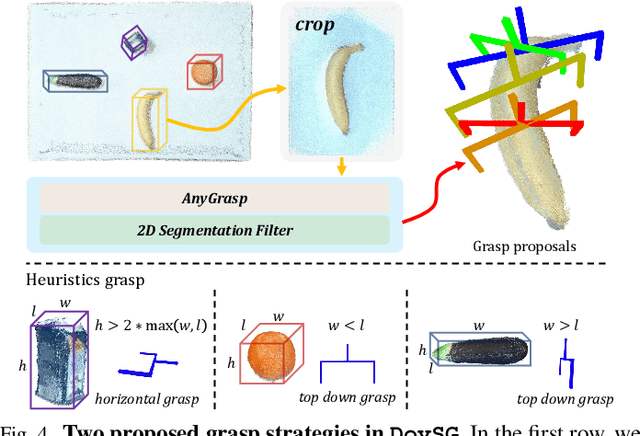

Enabling mobile robots to perform long-term tasks in dynamic real-world environments is a formidable challenge, especially when the environment changes frequently due to human-robot interactions or the robot's own actions. Traditional methods typically assume static scenes, which limits their applicability in the continuously changing real world. To overcome these limitations, we present DovSG, a novel mobile manipulation framework that leverages dynamic open-vocabulary 3D scene graphs and a language-guided task planning module for long-term task execution. DovSG takes RGB-D sequences as input and utilizes vision-language models (VLMs) for object detection to obtain high-level object semantic features. Based on the segmented objects, a structured 3D scene graph is generated for low-level spatial relationships. Furthermore, an efficient mechanism for locally updating the scene graph, allows the robot to adjust parts of the graph dynamically during interactions without the need for full scene reconstruction. This mechanism is particularly valuable in dynamic environments, enabling the robot to continually adapt to scene changes and effectively support the execution of long-term tasks. We validated our system in real-world environments with varying degrees of manual modifications, demonstrating its effectiveness and superior performance in long-term tasks. Our project page is available at: https://BJHYZJ.github.io/DoviSG.
Large Language Models Powered Context-aware Motion Prediction
Mar 17, 2024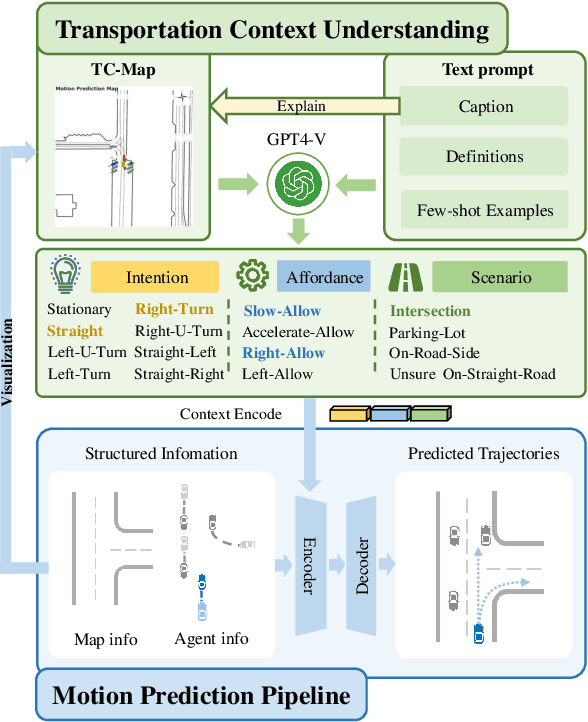
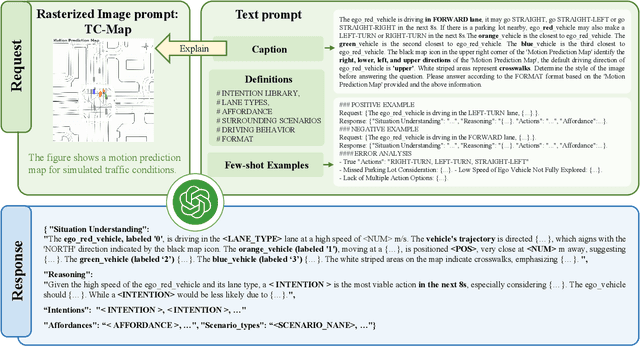
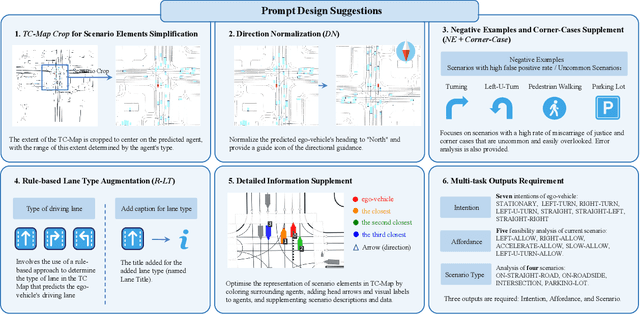
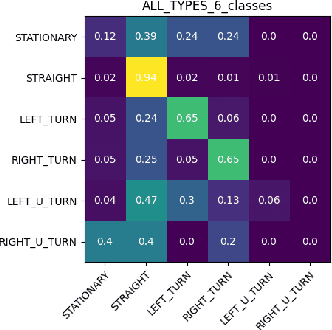
Motion prediction is among the most fundamental tasks in autonomous driving. Traditional methods of motion forecasting primarily encode vector information of maps and historical trajectory data of traffic participants, lacking a comprehensive understanding of overall traffic semantics, which in turn affects the performance of prediction tasks. In this paper, we utilized Large Language Models (LLMs) to enhance the global traffic context understanding for motion prediction tasks. We first conducted systematic prompt engineering, visualizing complex traffic environments and historical trajectory information of traffic participants into image prompts -- Transportation Context Map (TC-Map), accompanied by corresponding text prompts. Through this approach, we obtained rich traffic context information from the LLM. By integrating this information into the motion prediction model, we demonstrate that such context can enhance the accuracy of motion predictions. Furthermore, considering the cost associated with LLMs, we propose a cost-effective deployment strategy: enhancing the accuracy of motion prediction tasks at scale with 0.7\% LLM-augmented datasets. Our research offers valuable insights into enhancing the understanding of traffic scenes of LLMs and the motion prediction performance of autonomous driving.