 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoIRL-AD: Collaborative-Competitive Imitation-Reinforcement Learning in Latent World Models for Autonomous Driving
Oct 14, 2025End-to-end autonomous driving models trained solely with imitation learning (IL) often suffer from poor generalization. In contrast, reinforcement learning (RL) promotes exploration through reward maximization but faces challenges such as sample inefficiency and unstable convergence. A natural solution is to combine IL and RL. Moving beyond the conventional two-stage paradigm (IL pretraining followed by RL fine-tuning), we propose CoIRL-AD, a competitive dual-policy framework that enables IL and RL agents to interact during training. CoIRL-AD introduces a competition-based mechanism that facilitates knowledge exchange while preventing gradient conflicts. Experiments on the nuScenes dataset show an 18% reduction in collision rate compared to baselines, along with stronger generalization and improved performance on long-tail scenarios. Code is available at: https://github.com/SEU-zxj/CoIRL-AD.
ChordPrompt: Orchestrating Cross-Modal Prompt Synergy for Multi-Domain Incremental Learning in CLIP
Jun 24, 2025Continual learning (CL) empowers pre-trained vision-language models to adapt effectively to novel or previously underrepresented data distributions without comprehensive retraining, enhancing their adaptability and efficiency. While vision-language models like CLIP show great promise, they struggle to maintain performance across domains in incremental learning scenarios. Existing prompt learning methods face two main limitations: 1) they primarily focus on class-incremental learning scenarios, lacking specific strategies for multi-domain task incremental learning; 2) most current approaches employ single-modal prompts, neglecting the potential benefits of cross-modal information exchange. To address these challenges, we propose the \ChordPrompt framework, which facilitates a harmonious interplay between visual and textual prompts. \ChordPrompt introduces cross-modal prompts to leverage interactions between visual and textual information. Our approach also employs domain-adaptive text prompts to select appropriate prompts for continual adaptation across multiple domains. Comprehensive experiments on multi-domain incremental learning benchmarks demonstrate that \ChordPrompt outperforms state-of-the-art methods in zero-shot generalization and downstream task performance.
PhyBlock: A Progressive Benchmark for Physical Understanding and Planning via 3D Block Assembly
Jun 10, 2025While vision-language models (VLMs) have demonstrated promising capabilities in reasoning and planning for embodied agents, their ability to comprehend physical phenomena, particularly within structured 3D environments, remains severely limited. To close this gap, we introduce PhyBlock, a progressive benchmark designed to assess VLMs on physical understanding and planning through robotic 3D block assembly tasks. PhyBlock integrates a novel four-level cognitive hierarchy assembly task alongside targeted Visual Question Answering (VQA) samples, collectively aimed at evaluating progressive spatial reasoning and fundamental physical comprehension, including object properties, spatial relationships, and holistic scene understanding. PhyBlock includes 2600 block tasks (400 assembly tasks, 2200 VQA tasks) and evaluates models across three key dimensions: partial completion, failure diagnosis, and planning robustness. We benchmark 21 state-of-the-art VLMs, highlighting their strengths and limitations in physically grounded, multi-step planning. Our empirical findings indicate that the performance of VLMs exhibits pronounced limitations in high-level planning and reasoning capabilities, leading to a notable decline in performance for the growing complexity of the tasks. Error analysis reveals persistent difficulties in spatial orientation and dependency reasoning. Surprisingly, chain-of-thought prompting offers minimal improvements, suggesting spatial tasks heavily rely on intuitive model comprehension. We position PhyBlock as a unified testbed to advance embodied reasoning, bridging vision-language understanding and real-world physical problem-solving.
Task-agnostic Decision Transformer for Multi-type Agent Control with Federated Split Training
May 22, 2024



With the rapid advancements in artificial intelligence, the development of knowledgeable and personalized agents has become increasingly prevalent. However, the inherent variability in state variables and action spaces among personalized agents poses significant aggregation challenges for traditional federated learning algorithms. To tackle these challenges, we introduce the Federated Split Decision Transformer (FSDT), an innovative framework designed explicitly for AI agent decision tasks. The FSDT framework excels at navigating the intricacies of personalized agents by harnessing distributed data for training while preserving data privacy. It employs a two-stage training process, with local embedding and prediction models on client agents and a global transformer decoder model on the server. Our comprehensive evaluation using the benchmark D4RL dataset highlights the superior performance of our algorithm in federated split learning for personalized agents, coupled with significant reductions in communication and computational overhead compared to traditional centralized training approaches. The FSDT framework demonstrates strong potential for enabling efficient and privacy-preserving collaborative learning in applications such as autonomous driving decision systems. Our findings underscore the efficacy of the FSDT framework in effectively leveraging distributed offline reinforcement learning data to enable powerful multi-type agent decision systems.
Large Language Models Powered Context-aware Motion Prediction
Mar 17, 2024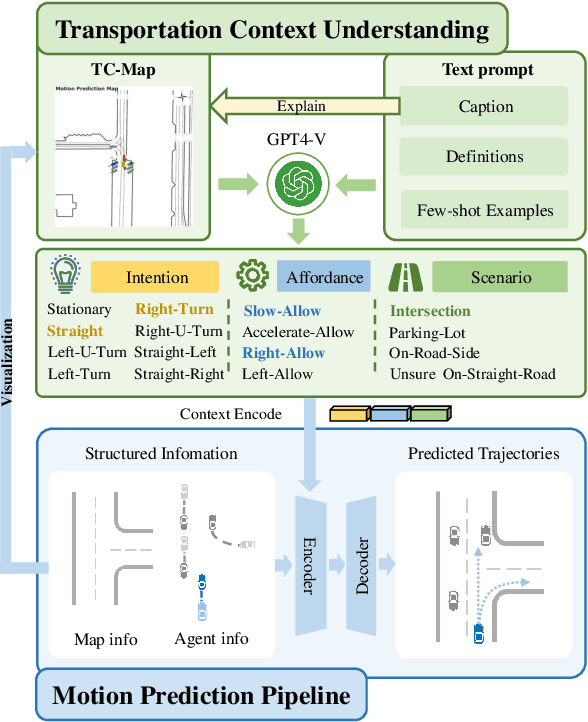
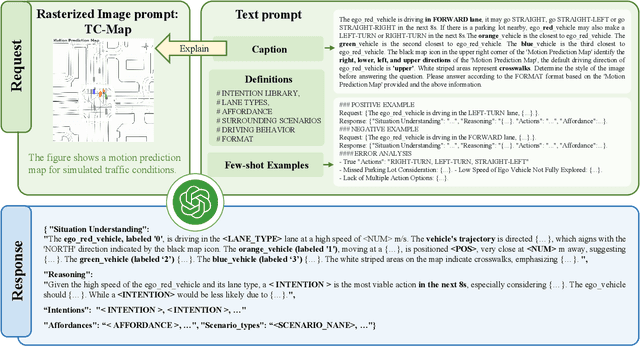
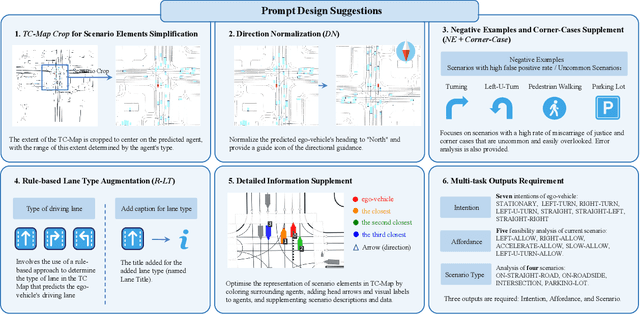
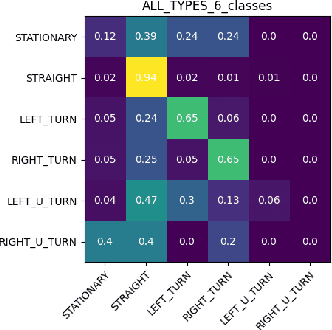
Motion prediction is among the most fundamental tasks in autonomous driving. Traditional methods of motion forecasting primarily encode vector information of maps and historical trajectory data of traffic participants, lacking a comprehensive understanding of overall traffic semantics, which in turn affects the performance of prediction tasks. In this paper, we utilized Large Language Models (LLMs) to enhance the global traffic context understanding for motion prediction tasks. We first conducted systematic prompt engineering, visualizing complex traffic environments and historical trajectory information of traffic participants into image prompts -- Transportation Context Map (TC-Map), accompanied by corresponding text prompts. Through this approach, we obtained rich traffic context information from the LLM. By integrating this information into the motion prediction model, we demonstrate that such context can enhance the accuracy of motion predictions. Furthermore, considering the cost associated with LLMs, we propose a cost-effective deployment strategy: enhancing the accuracy of motion prediction tasks at scale with 0.7\% LLM-augmented datasets. Our research offers valuable insights into enhancing the understanding of traffic scenes of LLMs and the motion prediction performance of autonomous driving.
P2DT: Mitigating Forgetting in task-incremental Learning with progressive prompt Decision Transformer
Jan 22, 2024



Catastrophic forgetting poses a substantial challenge for managing intelligent agents controlled by a large model, causing performance degradation when these agents face new tasks. In our work, we propose a novel solution - the Progressive Prompt Decision Transformer (P2DT). This method enhances a transformer-based model by dynamically appending decision tokens during new task training, thus fostering task-specific policies. Our approach mitigates forgetting in continual and offline reinforcement learning scenarios. Moreover, P2DT leverages trajectories collected via traditional reinforcement learning from all tasks and generates new task-specific tokens during training, thereby retaining knowledge from previous studies. Preliminary results demonstrate that our model effectively alleviates catastrophic forgetting and scales well with increasing task environments.
INCPrompt: Task-Aware incremental Prompting for Rehearsal-Free Class-incremental Learning
Jan 22, 2024



This paper introduces INCPrompt, an innovative continual learning solution that effectively addresses catastrophic forgetting. INCPrompt's key innovation lies in its use of adaptive key-learner and task-aware prompts that capture task-relevant information. This unique combination encapsulates general knowledge across tasks and encodes task-specific knowledge. Our comprehensive evaluation across multiple continual learning benchmarks demonstrates INCPrompt's superiority over existing algorithms, showing its effectiveness in mitigating catastrophic forgetting while maintaining high performance. These results highlight the significant impact of task-aware incremental prompting on continual learning performance.