 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Open-Vocabulary 3D Scene Graphs for Long-term Language-Guided Mobile Manipulation
Oct 17, 2024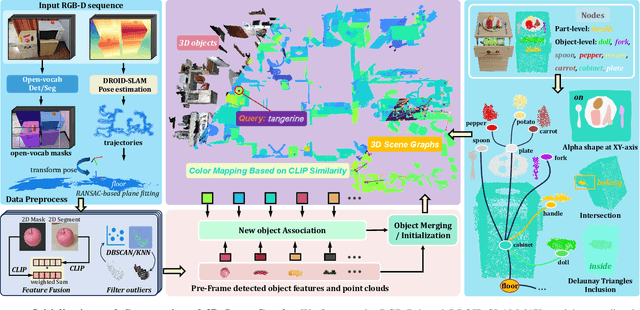
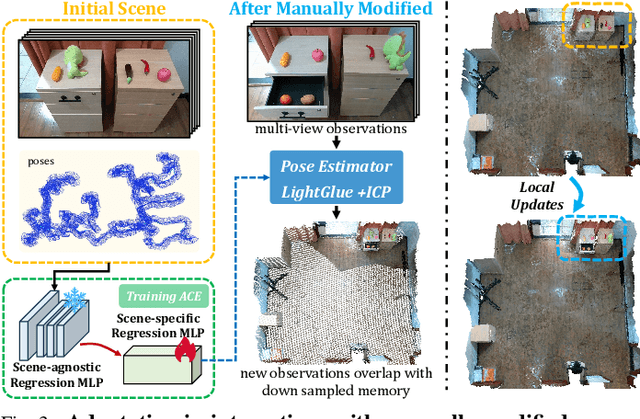
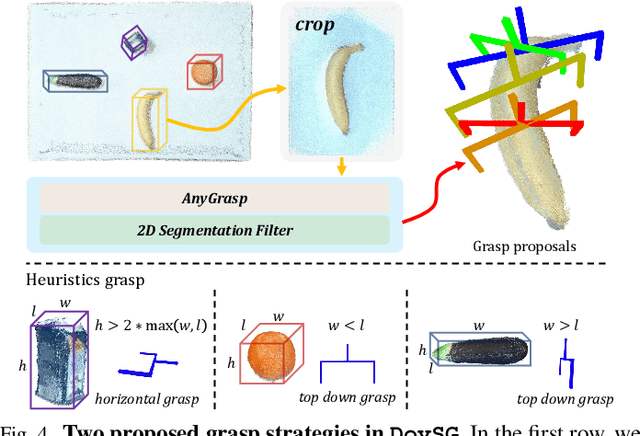

Enabling mobile robots to perform long-term tasks in dynamic real-world environments is a formidable challenge, especially when the environment changes frequently due to human-robot interactions or the robot's own actions. Traditional methods typically assume static scenes, which limits their applicability in the continuously changing real world. To overcome these limitations, we present DovSG, a novel mobile manipulation framework that leverages dynamic open-vocabulary 3D scene graphs and a language-guided task planning module for long-term task execution. DovSG takes RGB-D sequences as input and utilizes vision-language models (VLMs) for object detection to obtain high-level object semantic features. Based on the segmented objects, a structured 3D scene graph is generated for low-level spatial relationships. Furthermore, an efficient mechanism for locally updating the scene graph, allows the robot to adjust parts of the graph dynamically during interactions without the need for full scene reconstruction. This mechanism is particularly valuable in dynamic environments, enabling the robot to continually adapt to scene changes and effectively support the execution of long-term tasks. We validated our system in real-world environments with varying degrees of manual modifications, demonstrating its effectiveness and superior performance in long-term tasks. Our project page is available at: https://BJHYZJ.github.io/DoviSG.
Hyperbolic Fine-tuning for Large Language Models
Oct 05, 2024



Large language models (LLMs) have demonstrated remarkable performance on various tasks. However, it remains an open question whether the default Euclidean space is the most suitable choice for embedding tokens in LLMs. In this study, we first investigate the non-Euclidean characteristics of LLMs. Our findings reveal that token frequency follows a power-law distribution, with high-frequency tokens clustering near the origin and low-frequency tokens positioned farther away. Additionally, token embeddings exhibit a high degree of hyperbolicity, indicating a latent tree-like structure in the embedding space. Building on the observation, we propose to efficiently fine-tune LLMs in hyperbolic space to better exploit the underlying complex structures. However, we found that this fine-tuning in hyperbolic space cannot be achieved with naive application of exponential and logarithmic maps, when the embedding and weight matrices both reside in Euclidean space. To address this technique issue, we introduce a new method called hyperbolic low-rank efficient fine-tuning, HypLoRA, that performs low-rank adaptation directly on the hyperbolic manifold, avoiding the cancellation effect caused by the exponential and logarithmic maps, thus preserving the hyperbolic modeling capabilities. Through extensive experiments, we demonstrate that HypLoRA significantly enhances the performance of LLMs on reasoning tasks, particularly for complex reasoning problems. In particular, HypLoRA improves the performance in the complex AQuA dataset by up to 13.0%, showcasing its effectiveness in handling complex reasoning challenges
DA-Net: A Disentangled and Adaptive Network for Multi-Source Cross-Lingual Transfer Learning
Mar 07, 2024Multi-Source cross-lingual transfer learning deals with the transfer of task knowledge from multiple labelled source languages to an unlabeled target language under the language shift. Existing methods typically focus on weighting the predictions produced by language-specific classifiers of different sources that follow a shared encoder. However, all source languages share the same encoder, which is updated by all these languages. The extracted representations inevitably contain different source languages' information, which may disturb the learning of the language-specific classifiers. Additionally, due to the language gap, language-specific classifiers trained with source labels are unable to make accurate predictions for the target language. Both facts impair the model's performance. To address these challenges, we propose a Disentangled and Adaptive Network (DA-Net). Firstly, we devise a feedback-guided collaborative disentanglement method that seeks to purify input representations of classifiers, thereby mitigating mutual interference from multiple sources. Secondly, we propose a class-aware parallel adaptation method that aligns class-level distributions for each source-target language pair, thereby alleviating the language pairs' language gap. Experimental results on three different tasks involving 38 languages validate the effectiveness of our approach.
ProKD: An Unsupervised Prototypical Knowledge Distillation Network for Zero-Resource Cross-Lingual Named Entity Recognition
Jan 21, 2023For named entity recognition (NER) in zero-resource languages, utilizing knowledge distillation methods to transfer language-independent knowledge from the rich-resource source languages to zero-resource languages is an effective means. Typically, these approaches adopt a teacher-student architecture, where the teacher network is trained in the source language, and the student network seeks to learn knowledge from the teacher network and is expected to perform well in the target language. Despite the impressive performance achieved by these methods, we argue that they have two limitations. Firstly, the teacher network fails to effectively learn language-independent knowledge shared across languages due to the differences in the feature distribution between the source and target languages. Secondly, the student network acquires all of its knowledge from the teacher network and ignores the learning of target language-specific knowledge. Undesirably, these limitations would hinder the model's performance in the target language. This paper proposes an unsupervised prototype knowledge distillation network (ProKD) to address these issues. Specifically, ProKD presents a contrastive learning-based prototype alignment method to achieve class feature alignment by adjusting the distance among prototypes in the source and target languages, boosting the teacher network's capacity to acquire language-independent knowledge. In addition, ProKD introduces a prototypical self-training method to learn the intrinsic structure of the language by retraining the student network on the target data using samples' distance information from prototypes, thereby enhancing the student network's ability to acquire language-specific knowledge. Extensive experiments on three benchmark cross-lingual NER datasets demonstrate the effectiveness of our approach.
A Segmentation-Oriented Inter-Class Transfer Method: Application to Retinal Vessel Segmentation
Jun 20, 2019


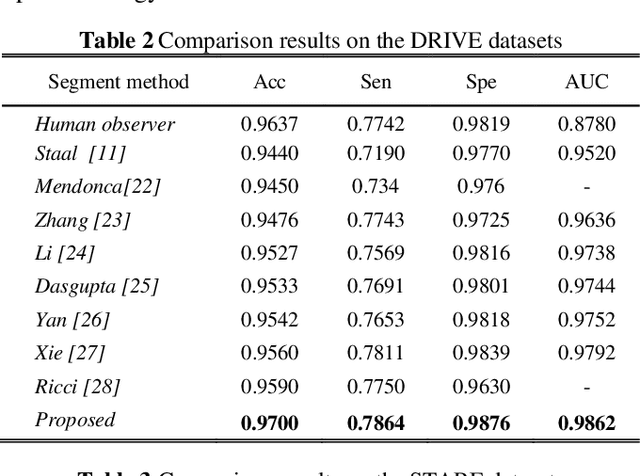
Retinal vessel segmentation, as a principal nonintrusive diagnose method for ophthalmology diseases or diabetics, suffers from data scarcity due to requiring pixel-wise labels. In this paper, we proposed a convenient patch-based two-stage transfer method. First, based on the information bottleneck theory, we insert one dimensionality-reduced layer for task-specific feature space. Next, the semi-supervised clustering is conducted to select instances, from different sources databases, possessing similarities in the feature space. Surprisingly, we empirically demonstrate that images from different classes possessing similarities contribute to better performance than some same-class instances. The proposed framework achieved an accuracy of 97%, 96.8%, and 96.77% on DRIVE, STARE, and HRF respectively, outperforming current methods and independent human observers (DRIVE (96.37%) and STARE (93.39%)).