 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePseudo-Label Calibration Semi-supervised Multi-Modal Entity Alignment
Mar 02, 2024Multi-modal entity alignment (MMEA) aims to identify equivalent entities between two multi-modal knowledge graphs for integration. Unfortunately, prior arts have attempted to improve the interaction and fusion of multi-modal information, which have overlooked the influence of modal-specific noise and the usage of labeled and unlabeled data in semi-supervised settings. In this work, we introduce a Pseudo-label Calibration Multi-modal Entity Alignment (PCMEA) in a semi-supervised way. Specifically, in order to generate holistic entity representations, we first devise various embedding modules and attention mechanisms to extract visual, structural, relational, and attribute features. Different from the prior direct fusion methods, we next propose to exploit mutual information maximization to filter the modal-specific noise and to augment modal-invariant commonality. Then, we combine pseudo-label calibration with momentum-based contrastive learning to make full use of the labeled and unlabeled data, which improves the quality of pseudo-label and pulls aligned entities closer. Finally, extensive experiments on two MMEA datasets demonstrate the effectiveness of our PCMEA, which yields state-of-the-art performance.
The Application of Driver Models in the Safety Assessment of Autonomous Vehicles: A Survey
Mar 26, 2023



Driver models play a vital role in developing and verifying autonomous vehicles (AVs). Previously, they are mainly applied in traffic flow simulation to model realistic driver behavior. With the development of AVs, driver models attract much attention again due to their potential contributions to AV certification. The simulation-based testing method is considered an effective measure to accelerate AV testing due to its safe and efficient characteristics. Nonetheless, realistic driver models are prerequisites for valid simulation results. Additionally, an AV is assumed to be at least as safe as a careful and competent driver. Therefore, driver models are inevitable for AV safety assessment. However, no comparison or discussion of driver models is available regarding their utility to AVs in the last five years despite their necessities in the release of AVs. This motivates us to present a comprehensive survey of driver models in the paper and compare their applicability. Requirements for driver models in terms of their application to AV safety assessment are discussed. A summary of driver models for simulation-based testing and AV certification is provided. Evaluation metrics are defined to compare their strength and weakness. Finally, an architecture for a careful and competent driver model is proposed. Challenges and future work are elaborated. This study gives related researchers especially regulators an overview and helps them to define appropriate driver models for AVs.
"I am the follower, also the boss": Exploring Different Levels of Autonomy and Machine Forms of Guiding Robots for the Visually Impaired
Feb 07, 2023



Guiding robots, in the form of canes or cars, have recently been explored to assist blind and low vision (BLV) people. Such robots can provide full or partial autonomy when guiding. However, the pros and cons of different forms and autonomy for guiding robots remain unknown. We sought to fill this gap. We designed autonomy-switchable guiding robotic cane and car. We conducted a controlled lab-study (N=12) and a field study (N=9) on BLV. Results showed that full autonomy received better walking performance and subjective ratings in the controlled study, whereas participants used more partial autonomy in the natural environment as demanding more control. Besides, the car robot has demonstrated abilities to provide a higher sense of safety and navigation efficiency compared with the cane robot. Our findings offered empirical evidence about how the BLV community perceived different machine forms and autonomy, which can inform the design of assistive robots.
Can Quadruped Navigation Robots be Used as Guide Dogs?
Oct 18, 2022
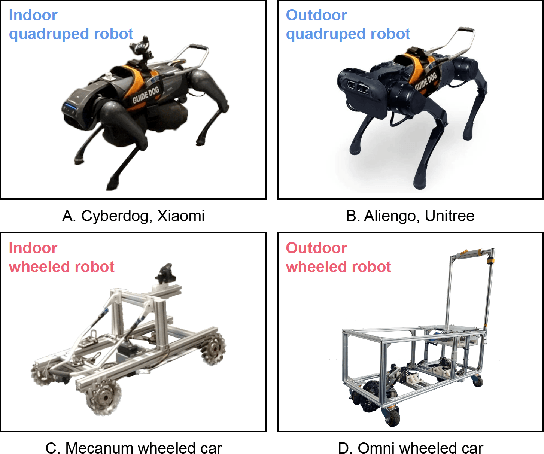
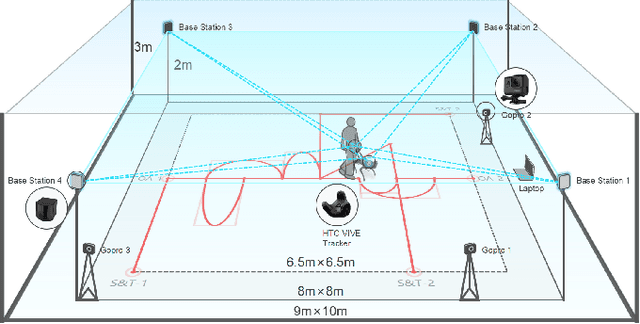
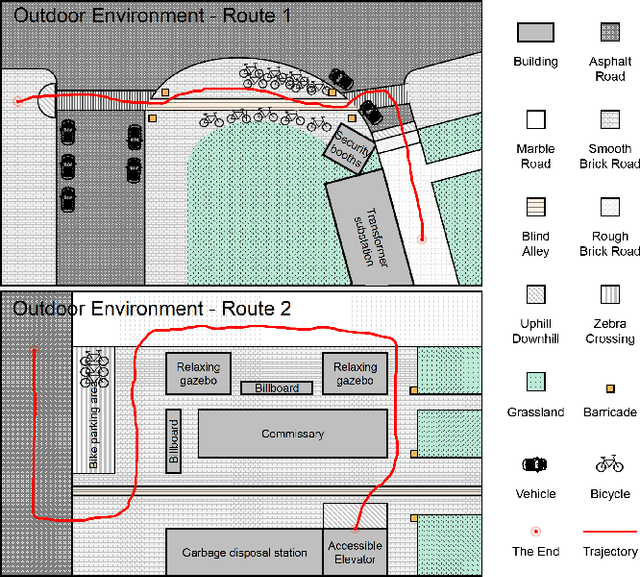
Bionic robots are generally considered to have strong flexibility, adaptability, and stability. Their bionic forms are more likely to interact emotionally with people, which means obvious advantages as socially assistive robots. However, it has not been widely concerned and verified in the blind and low-vision community. In this paper, we explored the guiding performance and experience of bionic quadruped robots compared to wheeled robots. We invited the visually impaired participants to complete a) the indoor straight & turn task and obstacle avoidance task in a laboratory environment; b) the outdoor real and complex environment. With the transition from indoor to outdoor, we found that the workload of the bionic quadruped robots changed to insignificant. Moreover, obvious temporal demand indoors changed to significant mental demand outdoors. Also, there was no significant advantage of quadruped robots in usability, trust, or satisfaction, which was amplified outdoors. We concluded that walking noise and the gait of quadruped robots would limit the guiding effect to a certain extent, and the empathetic effect of its zoomorphic form for visually impaired people could not be fully reflected. This paper provides evidence for the empirical research of bionic quadruped robots in the field of guiding VI people, pointing out their shortcomings in guiding performance and experience, and has good instructive value for the design of bionic guided robots in the future.
Agile Amulet: Real-Time Salient Object Detection with Contextual Attention
Feb 20, 2018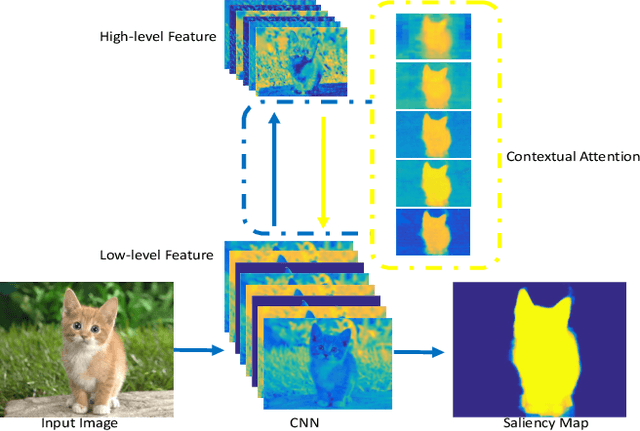
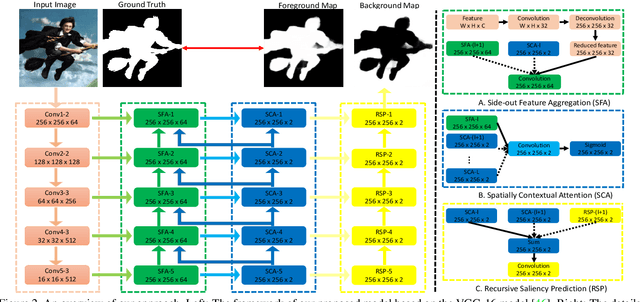
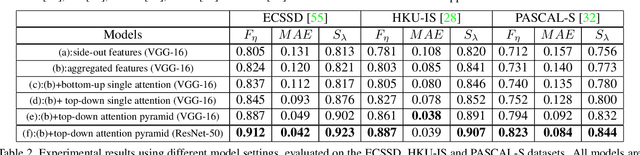

This paper proposes an Agile Aggregating Multi-Level feaTure framework (Agile Amulet) for salient object detection. The Agile Amulet builds on previous works to predict saliency maps using multi-level convolutional features. Compared to previous works, Agile Amulet employs some key innovations to improve training and testing speed while also increase prediction accuracy. More specifically, we first introduce a contextual attention module that can rapidly highlight most salient objects or regions with contextual pyramids. Thus, it effectively guides the learning of low-layer convolutional features and tells the backbone network where to look. The contextual attention module is a fully convolutional mechanism that simultaneously learns complementary features and predicts saliency scores at each pixel. In addition, we propose a novel method to aggregate multi-level deep convolutional features. As a result, we are able to use the integrated side-output features of pre-trained convolutional networks alone, which significantly reduces the model parameters leading to a model size of 67 MB, about half of Amulet. Compared to other deep learning based saliency methods, Agile Amulet is of much lighter-weight, runs faster (30 fps in real-time) and achieves higher performance on seven public benchmarks in terms of both quantitative and qualitative evaluation.