 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgile Amulet: Real-Time Salient Object Detection with Contextual Attention
Paper and Code
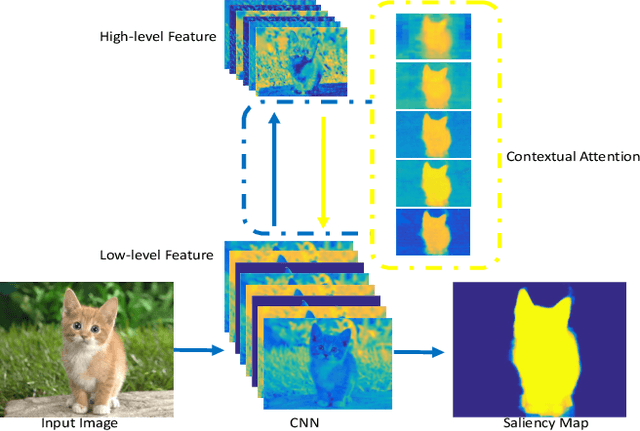
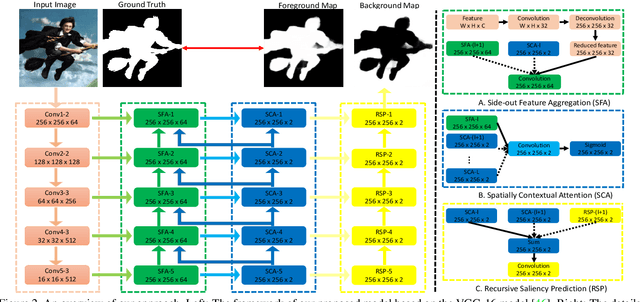
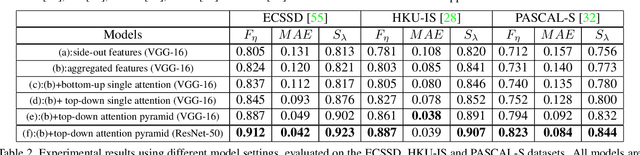

This paper proposes an Agile Aggregating Multi-Level feaTure framework (Agile Amulet) for salient object detection. The Agile Amulet builds on previous works to predict saliency maps using multi-level convolutional features. Compared to previous works, Agile Amulet employs some key innovations to improve training and testing speed while also increase prediction accuracy. More specifically, we first introduce a contextual attention module that can rapidly highlight most salient objects or regions with contextual pyramids. Thus, it effectively guides the learning of low-layer convolutional features and tells the backbone network where to look. The contextual attention module is a fully convolutional mechanism that simultaneously learns complementary features and predicts saliency scores at each pixel. In addition, we propose a novel method to aggregate multi-level deep convolutional features. As a result, we are able to use the integrated side-output features of pre-trained convolutional networks alone, which significantly reduces the model parameters leading to a model size of 67 MB, about half of Amulet. Compared to other deep learning based saliency methods, Agile Amulet is of much lighter-weight, runs faster (30 fps in real-time) and achieves higher performance on seven public benchmarks in terms of both quantitative and qualitative evaluation.