 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond End-to-End Video Models: An LLM-Based Multi-Agent System for Educational Video Generation
Feb 12, 2026Although recent end-to-end video generation models demonstrate impressive performance in visually oriented content creation, they remain limited in scenarios that require strict logical rigor and precise knowledge representation, such as instructional and educational media. To address this problem, we propose LAVES, a hierarchical LLM-based multi-agent system for generating high-quality instructional videos from educational problems. The LAVES formulates educational video generation as a multi-objective task that simultaneously demands correct step-by-step reasoning, pedagogically coherent narration, semantically faithful visual demonstrations, and precise audio--visual alignment. To address the limitations of prior approaches--including low procedural fidelity, high production cost, and limited controllability--LAVES decomposes the generation workflow into specialized agents coordinated by a central Orchestrating Agent with explicit quality gates and iterative critique mechanisms. Specifically, the Orchestrating Agent supervises a Solution Agent for rigorous problem solving, an Illustration Agent that produces executable visualization codes, and a Narration Agent for learner-oriented instructional scripts. In addition, all outputs from the working agents are subject to semantic critique, rule-based constraints, and tool-based compilation checks. Rather than directly synthesizing pixels, the system constructs a structured executable video script that is deterministically compiled into synchronized visuals and narration using template-driven assembly rules, enabling fully automated end-to-end production without manual editing. In large-scale deployments, LAVES achieves a throughput exceeding one million videos per day, delivering over a 95% reduction in cost compared to current industry-standard approaches while maintaining a high acceptance rate.
Video-MSR: Benchmarking Multi-hop Spatial Reasoning Capabilities of MLLMs
Jan 14, 2026Spatial reasoning has emerged as a critical capability for Multimodal Large Language Models (MLLMs), drawing increasing attention and rapid advancement. However, existing benchmarks primarily focus on single-step perception-to-judgment tasks, leaving scenarios requiring complex visual-spatial logical chains significantly underexplored. To bridge this gap, we introduce Video-MSR, the first benchmark specifically designed to evaluate Multi-hop Spatial Reasoning (MSR) in dynamic video scenarios. Video-MSR systematically probes MSR capabilities through four distinct tasks: Constrained Localization, Chain-based Reference Retrieval, Route Planning, and Counterfactual Physical Deduction. Our benchmark comprises 3,052 high-quality video instances with 4,993 question-answer pairs, constructed via a scalable, visually-grounded pipeline combining advanced model generation with rigorous human verification. Through a comprehensive evaluation of 20 state-of-the-art MLLMs, we uncover significant limitations, revealing that while models demonstrate proficiency in surface-level perception, they exhibit distinct performance drops in MSR tasks, frequently suffering from spatial disorientation and hallucination during multi-step deductions. To mitigate these shortcomings and empower models with stronger MSR capabilities, we further curate MSR-9K, a specialized instruction-tuning dataset, and fine-tune Qwen-VL, achieving a +7.82% absolute improvement on Video-MSR. Our results underscore the efficacy of multi-hop spatial instruction data and establish Video-MSR as a vital foundation for future research. The code and data will be available at https://github.com/ruiz-nju/Video-MSR.
Decide Then Retrieve: A Training-Free Framework with Uncertainty-Guided Triggering and Dual-Path Retrieval
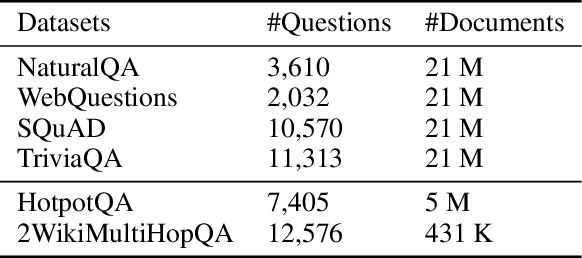
Jan 07, 2026Retrieval-augmented generation (RAG) enhances large language models (LLMs) by incorporating external knowledge, but existing approaches indiscriminately trigger retrieval and rely on single-path evidence construction, often introducing noise and limiting performance gains. In this work, we propose Decide Then Retrieve (DTR), a training-free framework that adaptively determines when retrieval is necessary and how external information should be selected. DTR leverages generation uncertainty to guide retrieval triggering and introduces a dual-path retrieval mechanism with adaptive information selection to better handle sparse and ambiguous queries. Extensive experiments across five open-domain QA benchmarks, multiple model scales, and different retrievers demonstrate that DTR consistently improves EM and F1 over standard RAG and strong retrieval-enhanced baselines, while reducing unnecessary retrievals. The code and data used in this paper are available at https://github.com/ChenWangHKU/DTR.
BBox DocVQA: A Large Scale Bounding Box Grounded Dataset for Enhancing Reasoning in Document Visual Question Answer
Nov 19, 2025Document Visual Question Answering (DocVQA) is a fundamental task for multimodal document understanding and a key testbed for vision language reasoning. However, most existing DocVQA datasets are limited to the page level and lack fine grained spatial grounding, constraining the interpretability and reasoning capability of Vision Language Models (VLMs). To address this gap, we introduce BBox DocVQA a large scale, bounding box grounded dataset designed to enhance spatial reasoning and evidence localization in visual documents. We further present an automated construction pipeline, Segment Judge and Generate, which integrates a segment model for region segmentation, a VLM for semantic judgment, and another advanced VLM for question answer generation, followed by human verification for quality assurance. The resulting dataset contains 3.6 K diverse documents and 32 K QA pairs, encompassing single and multi region as well as single and multi page scenarios. Each QA instance is grounded on explicit bounding boxes, enabling fine grained evaluation of spatial semantic alignment. Benchmarking multiple state of the art VLMs (e.g., GPT 5, Qwen2.5 VL, and InternVL) on BBox DocVQA reveals persistent challenges in spatial grounding and reasoning accuracy. Furthermore, fine tuning on BBox DocVQA substantially improves both bounding box localization and answer generation, validating its effectiveness for enhancing the reasoning ability of VLMs. Our dataset and code will be publicly released to advance research on interpretable and spatially grounded vision language reasoning.
Facial-R1: Aligning Reasoning and Recognition for Facial Emotion Analysis
Nov 13, 2025
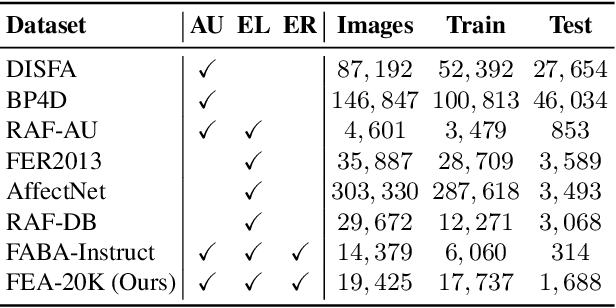
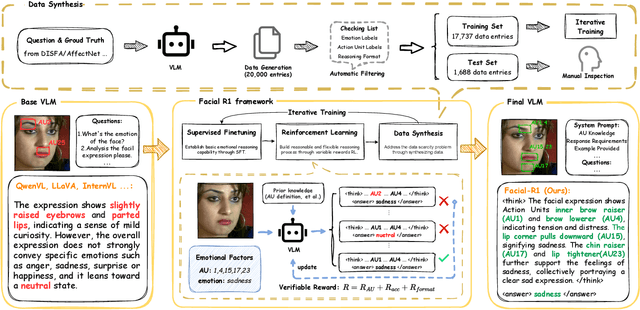
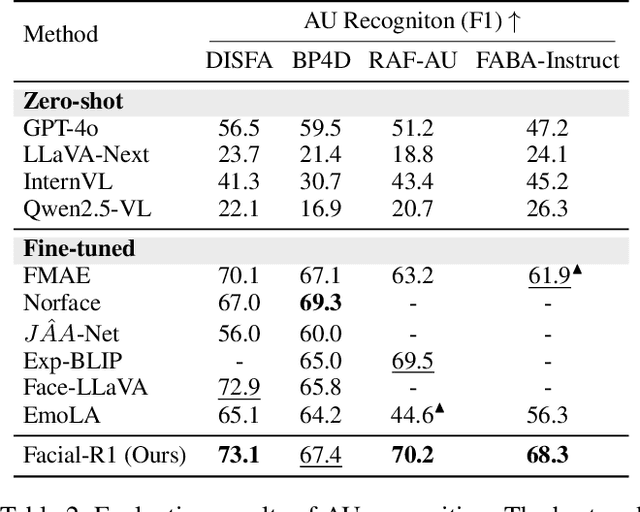
Facial Emotion Analysis (FEA) extends traditional facial emotion recognition by incorporating explainable, fine-grained reasoning. The task integrates three subtasks: emotion recognition, facial Action Unit (AU) recognition, and AU-based emotion reasoning to model affective states jointly. While recent approaches leverage Vision-Language Models (VLMs) and achieve promising results, they face two critical limitations: (1) hallucinated reasoning, where VLMs generate plausible but inaccurate explanations due to insufficient emotion-specific knowledge; and (2) misalignment between emotion reasoning and recognition, caused by fragmented connections between observed facial features and final labels. We propose Facial-R1, a three-stage alignment framework that effectively addresses both challenges with minimal supervision. First, we employ instruction fine-tuning to establish basic emotional reasoning capability. Second, we introduce reinforcement training guided by emotion and AU labels as reward signals, which explicitly aligns the generated reasoning process with the predicted emotion. Third, we design a data synthesis pipeline that iteratively leverages the prior stages to expand the training dataset, enabling scalable self-improvement of the model. Built upon this framework, we introduce FEA-20K, a benchmark dataset comprising 17,737 training and 1,688 test samples with fine-grained emotion analysis annotations. Extensive experiments across eight standard benchmarks demonstrate that Facial-R1 achieves state-of-the-art performance in FEA, with strong generalization and robust interpretability.
Cross-LoRA: A Data-Free LoRA Transfer Framework across Heterogeneous LLMs
Aug 07, 2025Traditional parameter-efficient fine-tuning (PEFT) methods such as LoRA are tightly coupled with the base model architecture, which constrains their applicability across heterogeneous pretrained large language models (LLMs). To address this limitation, we introduce Cross-LoRA, a data-free framework for transferring LoRA modules between diverse base models without requiring additional training data. Cross-LoRA consists of two key components: (a) LoRA-Align, which performs subspace alignment between source and target base models through rank-truncated singular value decomposition (SVD) and Frobenius-optimal linear transformation, ensuring compatibility under dimension mismatch; and (b) LoRA-Shift, which applies the aligned subspaces to project source LoRA weight updates into the target model parameter space. Both components are data-free, training-free, and enable lightweight adaptation on a commodity GPU in 20 minutes. Experiments on ARCs, OBOA and HellaSwag show that Cross-LoRA achieves relative gains of up to 5.26% over base models. Across other commonsense reasoning benchmarks, Cross-LoRA maintains performance comparable to that of directly trained LoRA adapters.
PAIRS: Parametric-Verified Adaptive Information Retrieval and Selection for Efficient RAG
Aug 06, 2025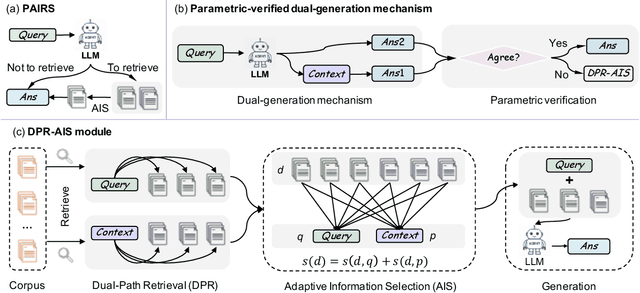
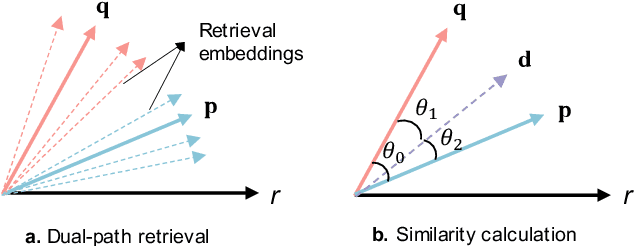
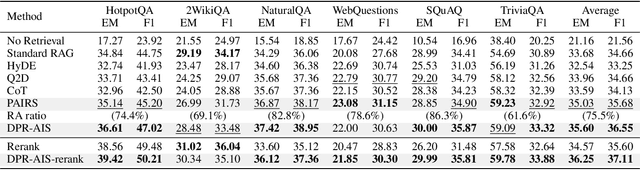
Retrieval-Augmented Generation (RAG) has become a cornerstone technique for enhancing large language models (LLMs) with external knowledge. However, current RAG systems face two critical limitations: (1) they inefficiently retrieve information for every query, including simple questions that could be resolved using the LLM's parametric knowledge alone, and (2) they risk retrieving irrelevant documents when queries contain sparse information signals. To address these gaps, we introduce Parametric-verified Adaptive Information Retrieval and Selection (PAIRS), a training-free framework that integrates parametric and retrieved knowledge to adaptively determine whether to retrieve and how to select external information. Specifically, PAIRS employs a dual-path generation mechanism: First, the LLM produces both a direct answer and a context-augmented answer using self-generated pseudo-context. When these outputs converge, PAIRS bypasses external retrieval entirely, dramatically improving the RAG system's efficiency. For divergent cases, PAIRS activates a dual-path retrieval (DPR) process guided by both the original query and self-generated contextual signals, followed by an Adaptive Information Selection (AIS) module that filters documents through weighted similarity to both sources. This simple yet effective approach can not only enhance efficiency by eliminating unnecessary retrievals but also improve accuracy through contextually guided retrieval and adaptive information selection. Experimental results on six question-answering (QA) benchmarks show that PAIRS reduces retrieval costs by around 25% (triggering for only 75% of queries) while still improving accuracy-achieving +1.1% EM and +1.0% F1 over prior baselines on average.
LDMapNet-U: An End-to-End System for City-Scale Lane-Level Map Updating
Jan 06, 2025



An up-to-date city-scale lane-level map is an indispensable infrastructure and a key enabling technology for ensuring the safety and user experience of autonomous driving systems. In industrial scenarios, reliance on manual annotation for map updates creates a critical bottleneck. Lane-level updates require precise change information and must ensure consistency with adjacent data while adhering to strict standards. Traditional methods utilize a three-stage approach-construction, change detection, and updating-which often necessitates manual verification due to accuracy limitations. This results in labor-intensive processes and hampers timely updates. To address these challenges, we propose LDMapNet-U, which implements a new end-to-end paradigm for city-scale lane-level map updating. By reconceptualizing the update task as an end-to-end map generation process grounded in historical map data, we introduce a paradigm shift in map updating that simultaneously generates vectorized maps and change information. To achieve this, a Prior-Map Encoding (PME) module is introduced to effectively encode historical maps, serving as a critical reference for detecting changes. Additionally, we incorporate a novel Instance Change Prediction (ICP) module that learns to predict associations with historical maps. Consequently, LDMapNet-U simultaneously achieves vectorized map element generation and change detection. To demonstrate the superiority and effectiveness of LDMapNet-U, extensive experiments are conducted using large-scale real-world datasets. In addition, LDMapNet-U has been successfully deployed in production at Baidu Maps since April 2024, supporting map updating for over 360 cities and significantly shortening the update cycle from quarterly to weekly. The updated maps serve hundreds of millions of users and are integrated into the autonomous driving systems of several leading vehicle companies.
DuMapNet: An End-to-End Vectorization System for City-Scale Lane-Level Map Generation
Jun 20, 2024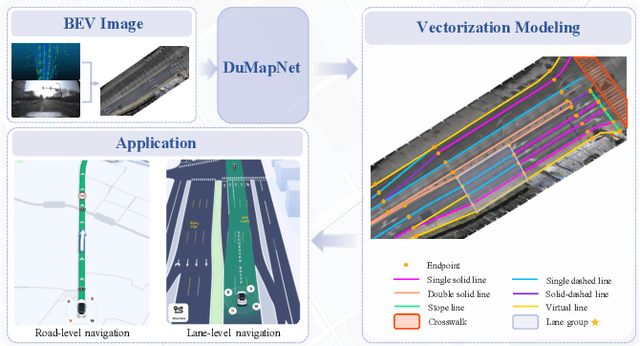
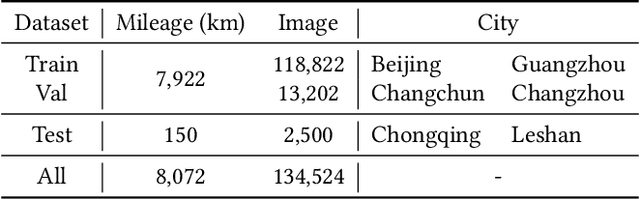
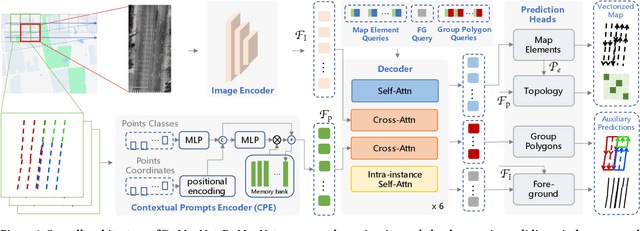
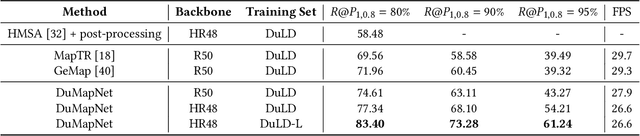
Generating city-scale lane-level maps faces significant challenges due to the intricate urban environments, such as blurred or absent lane markings. Additionally, a standard lane-level map requires a comprehensive organization of lane groupings, encompassing lane direction, style, boundary, and topology, yet has not been thoroughly examined in prior research. These obstacles result in labor-intensive human annotation and high maintenance costs. This paper overcomes these limitations and presents an industrial-grade solution named DuMapNet that outputs standardized, vectorized map elements and their topology in an end-to-end paradigm. To this end, we propose a group-wise lane prediction (GLP) system that outputs vectorized results of lane groups by meticulously tailoring a transformer-based network. Meanwhile, to enhance generalization in challenging scenarios, such as road wear and occlusions, as well as to improve global consistency, a contextual prompts encoder (CPE) module is proposed, which leverages the predicted results of spatial neighborhoods as contextual information. Extensive experiments conducted on large-scale real-world datasets demonstrate the superiority and effectiveness of DuMapNet. Additionally, DuMap-Net has already been deployed in production at Baidu Maps since June 2023, supporting lane-level map generation tasks for over 360 cities while bringing a 95% reduction in costs. This demonstrates that DuMapNet serves as a practical and cost-effective industrial solution for city-scale lane-level map generation.
More Than Routing: Joint GPS and Route Modeling for Refine Trajectory Representation Learning
Feb 25, 2024



Trajectory representation learning plays a pivotal role in supporting various downstream tasks. Traditional methods in order to filter the noise in GPS trajectories tend to focus on routing-based methods used to simplify the trajectories. However, this approach ignores the motion details contained in the GPS data, limiting the representation capability of trajectory representation learning. To fill this gap, we propose a novel representation learning framework that Joint GPS and Route Modelling based on self-supervised technology, namely JGRM. We consider GPS trajectory and route as the two modes of a single movement observation and fuse information through inter-modal information interaction. Specifically, we develop two encoders, each tailored to capture representations of route and GPS trajectories respectively. The representations from the two modalities are fed into a shared transformer for inter-modal information interaction. Eventually, we design three self-supervised tasks to train the model. We validate the effectiveness of the proposed method on two real datasets based on extensive experiments. The experimental results demonstrate that JGRM outperforms existing methods in both road segment representation and trajectory representation tasks. Our source code is available at Anonymous Github.