 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTakeAD: Preference-based Post-optimization for End-to-end Autonomous Driving with Expert Takeover Data
Dec 22, 2025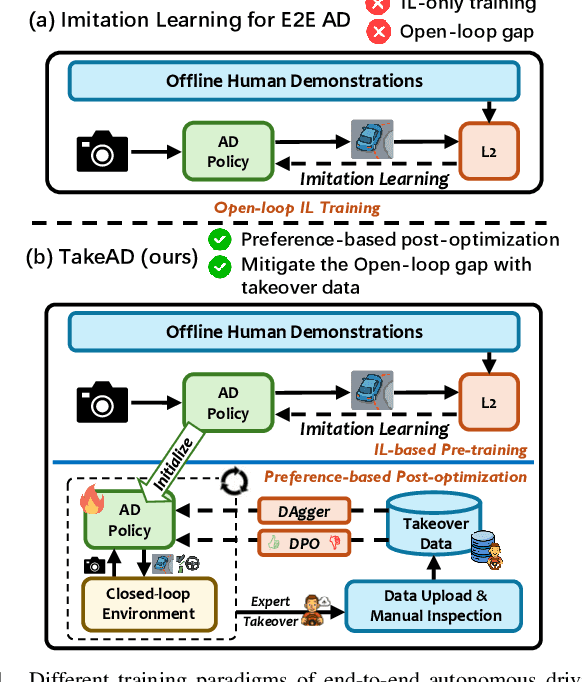
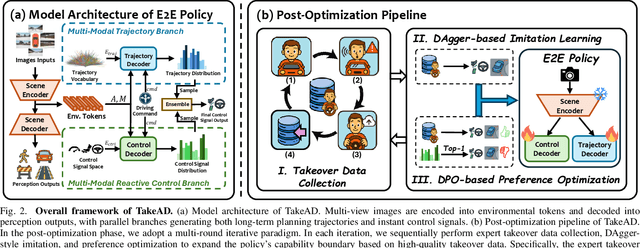
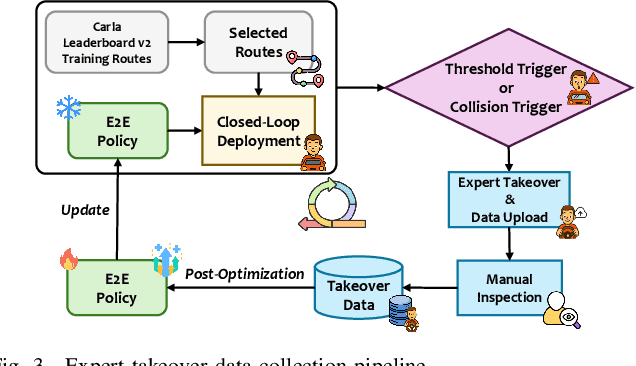
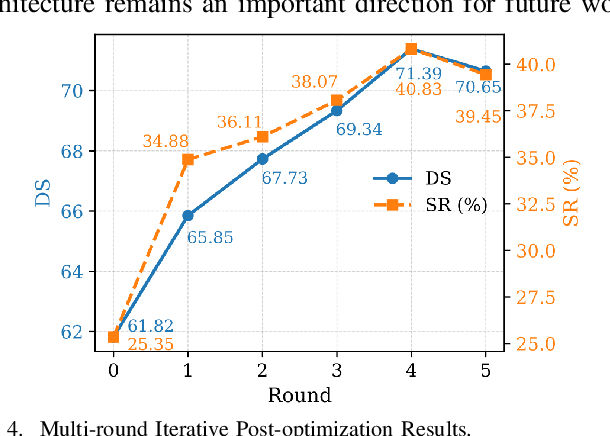
Existing end-to-end autonomous driving methods typically rely on imitation learning (IL) but face a key challenge: the misalignment between open-loop training and closed-loop deployment. This misalignment often triggers driver-initiated takeovers and system disengagements during closed-loop execution. How to leverage those expert takeover data from disengagement scenarios and effectively expand the IL policy's capability presents a valuable yet unexplored challenge. In this paper, we propose TakeAD, a novel preference-based post-optimization framework that fine-tunes the pre-trained IL policy with this disengagement data to enhance the closed-loop driving performance. First, we design an efficient expert takeover data collection pipeline inspired by human takeover mechanisms in real-world autonomous driving systems. Then, this post optimization framework integrates iterative Dataset Aggregation (DAgger) for imitation learning with Direct Preference Optimization (DPO) for preference alignment. The DAgger stage equips the policy with fundamental capabilities to handle disengagement states through direct imitation of expert interventions. Subsequently, the DPO stage refines the policy's behavior to better align with expert preferences in disengagement scenarios. Through multiple iterations, the policy progressively learns recovery strategies for disengagement states, thereby mitigating the open-loop gap. Experiments on the closed-loop Bench2Drive benchmark demonstrate our method's effectiveness compared with pure IL methods, with comprehensive ablations confirming the contribution of each component.
GraphAD: Interaction Scene Graph for End-to-end Autonomous Driving
Apr 07, 2024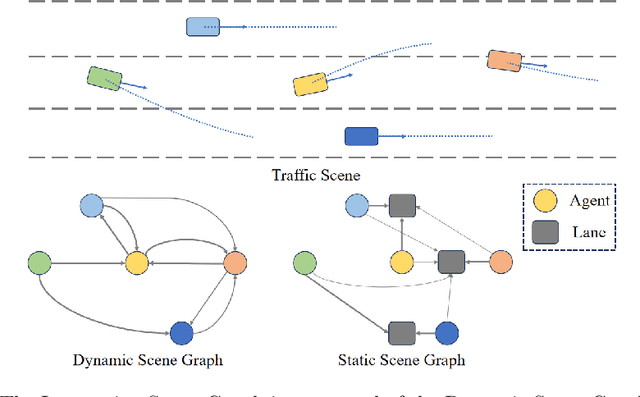
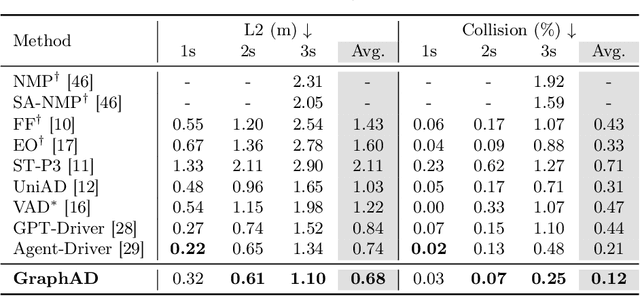
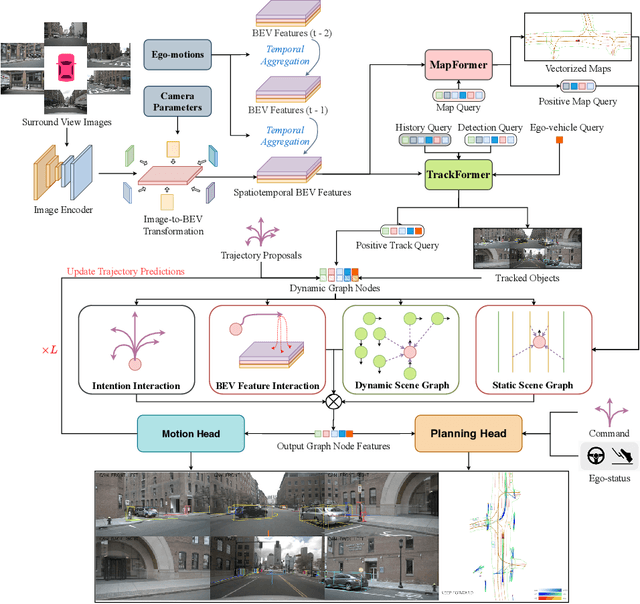
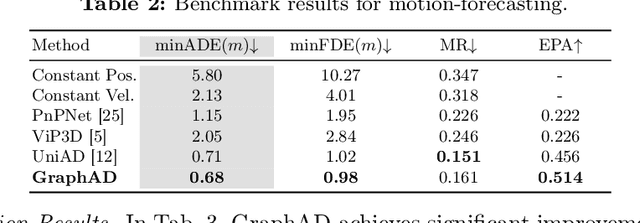
Modeling complicated interactions among the ego-vehicle, road agents, and map elements has been a crucial part for safety-critical autonomous driving. Previous works on end-to-end autonomous driving rely on the attention mechanism for handling heterogeneous interactions, which fails to capture the geometric priors and is also computationally intensive. In this paper, we propose the Interaction Scene Graph (ISG) as a unified method to model the interactions among the ego-vehicle, road agents, and map elements. With the representation of the ISG, the driving agents aggregate essential information from the most influential elements, including the road agents with potential collisions and the map elements to follow. Since a mass of unnecessary interactions are omitted, the more efficient scene-graph-based framework is able to focus on indispensable connections and leads to better performance. We evaluate the proposed method for end-to-end autonomous driving on the nuScenes dataset. Compared with strong baselines, our method significantly outperforms in the full-stack driving tasks, including perception, prediction, and planning. Code will be released at https://github.com/zhangyp15/GraphAD.
V2X-Seq: A Large-Scale Sequential Dataset for Vehicle-Infrastructure Cooperative Perception and Forecasting
May 10, 2023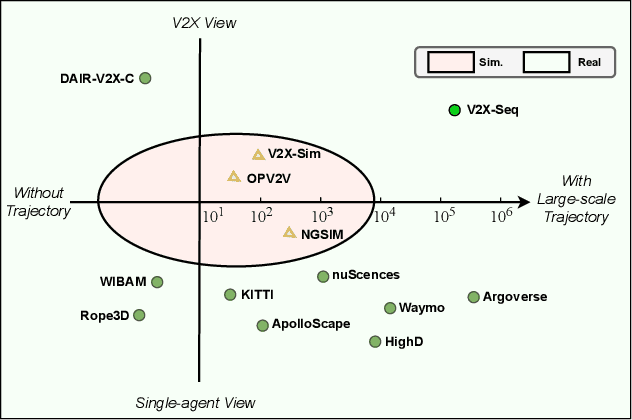
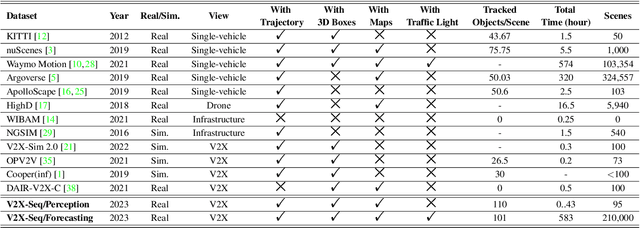
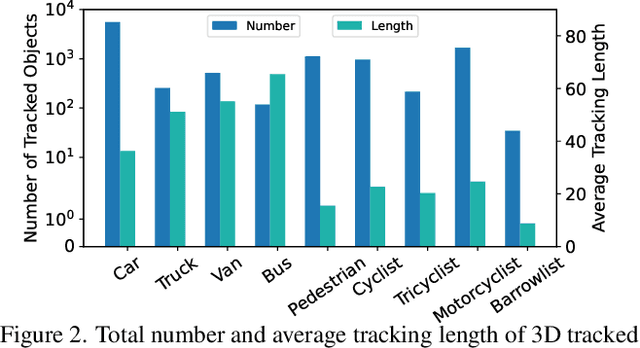
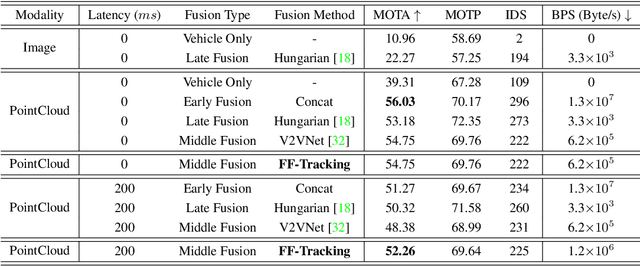
Utilizing infrastructure and vehicle-side information to track and forecast the behaviors of surrounding traffic participants can significantly improve decision-making and safety in autonomous driving. However, the lack of real-world sequential datasets limits research in this area. To address this issue, we introduce V2X-Seq, the first large-scale sequential V2X dataset, which includes data frames, trajectories, vector maps, and traffic lights captured from natural scenery. V2X-Seq comprises two parts: the sequential perception dataset, which includes more than 15,000 frames captured from 95 scenarios, and the trajectory forecasting dataset, which contains about 80,000 infrastructure-view scenarios, 80,000 vehicle-view scenarios, and 50,000 cooperative-view scenarios captured from 28 intersections' areas, covering 672 hours of data. Based on V2X-Seq, we introduce three new tasks for vehicle-infrastructure cooperative (VIC) autonomous driving: VIC3D Tracking, Online-VIC Forecasting, and Offline-VIC Forecasting. We also provide benchmarks for the introduced tasks. Find data, code, and more up-to-date information at \href{https://github.com/AIR-THU/DAIR-V2X-Seq}{https://github.com/AIR-THU/DAIR-V2X-Seq}.
A High Fidelity Simulation Framework for Potential Safety Benefits Estimation of Cooperative Pedestrian Perception
Oct 18, 2022
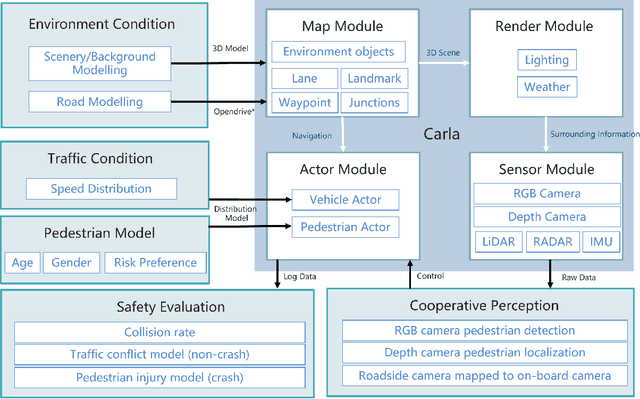
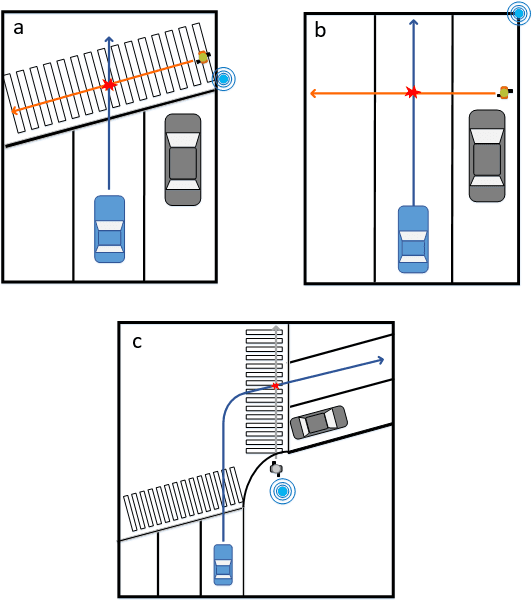
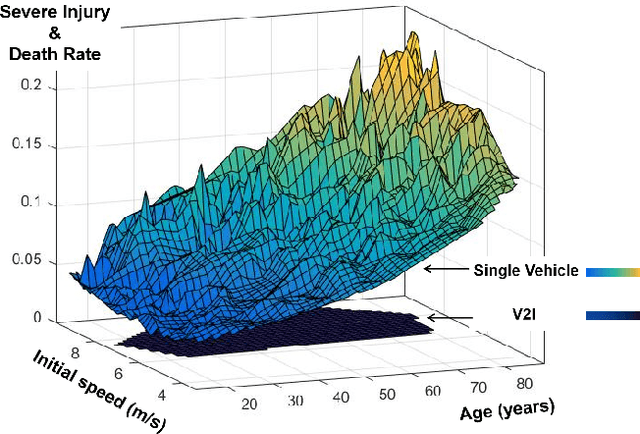
This paper proposes a high-fidelity simulation framework that can estimate the potential safety benefits of vehicle-to-infrastructure (V2I) pedestrian safety strategies. This simulator can support cooperative perception algorithms in the loop by simulating the environmental conditions, traffic conditions, and pedestrian characteristics at the same time. Besides, the benefit estimation model applied in our framework can systematically quantify both the risk conflict (non-crash condition) and the severity of the pedestrian's injuries (crash condition). An experiment was conducted in this paper that built a digital twin of a crowded urban intersection in China. The result shows that our framework is efficient for safety benefit estimation of V2I pedestrian safety strategies.
Text Flow: A Unified Text Detection System in Natural Scene Images
Apr 23, 2016

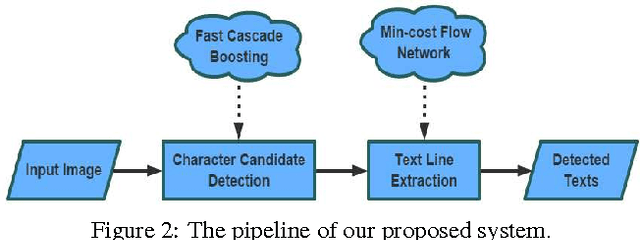
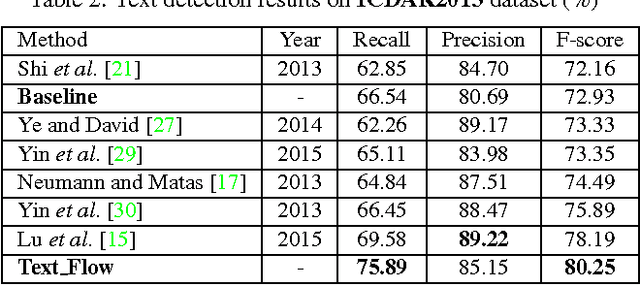
The prevalent scene text detection approach follows four sequential steps comprising character candidate detection, false character candidate removal, text line extraction, and text line verification. However, errors occur and accumulate throughout each of these sequential steps which often lead to low detection performance. To address these issues, we propose a unified scene text detection system, namely Text Flow, by utilizing the minimum cost (min-cost) flow network model. With character candidates detected by cascade boosting, the min-cost flow network model integrates the last three sequential steps into a single process which solves the error accumulation problem at both character level and text line level effectively. The proposed technique has been tested on three public datasets, i.e, ICDAR2011 dataset, ICDAR2013 dataset and a multilingual dataset and it outperforms the state-of-the-art methods on all three datasets with much higher recall and F-score. The good performance on the multilingual dataset shows that the proposed technique can be used for the detection of texts in different languages.