 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText Flow: A Unified Text Detection System in Natural Scene Images
Apr 23, 2016

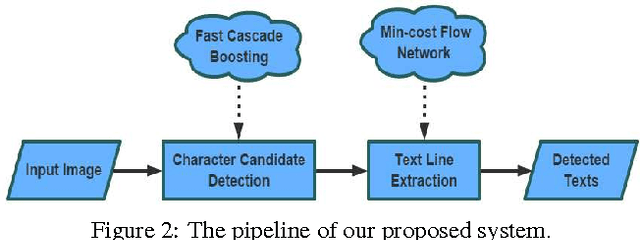
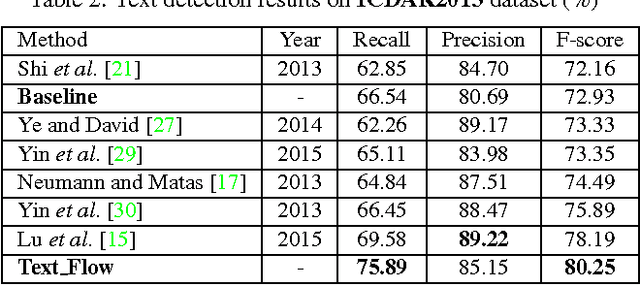
The prevalent scene text detection approach follows four sequential steps comprising character candidate detection, false character candidate removal, text line extraction, and text line verification. However, errors occur and accumulate throughout each of these sequential steps which often lead to low detection performance. To address these issues, we propose a unified scene text detection system, namely Text Flow, by utilizing the minimum cost (min-cost) flow network model. With character candidates detected by cascade boosting, the min-cost flow network model integrates the last three sequential steps into a single process which solves the error accumulation problem at both character level and text line level effectively. The proposed technique has been tested on three public datasets, i.e, ICDAR2011 dataset, ICDAR2013 dataset and a multilingual dataset and it outperforms the state-of-the-art methods on all three datasets with much higher recall and F-score. The good performance on the multilingual dataset shows that the proposed technique can be used for the detection of texts in different languages.
Automatic Alignment of English-Chinese Bilingual Texts of CNS News
Aug 27, 1996


In this paper we address a method to align English-Chinese bilingual news reports from China News Service, combining both lexical and satistical approaches. Because of the sentential structure differences between English and Chinese, matching at the sentence level as in many other works may result in frequent matching of several sentences en masse. In view of this, the current work also attempts to create shorter alignment pairs by permitting finer matching between clauses from both texts if possible. The current method is based on statiscal correlation between sentence or clause length of both texts and at the same time uses obvious anchors such as numbers and place names appearing frequently in the news reports as lexcial cues.