 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Cooperative Trajectory Representations for Motion Forecasting
Nov 01, 2023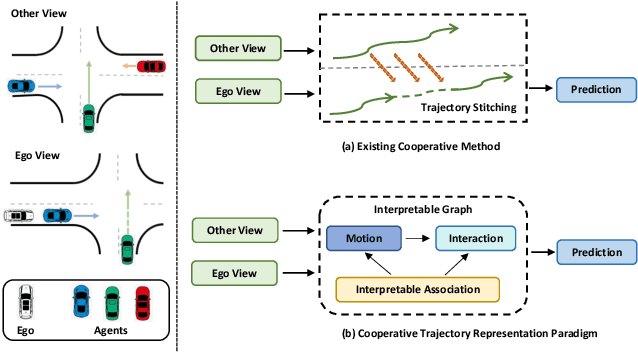
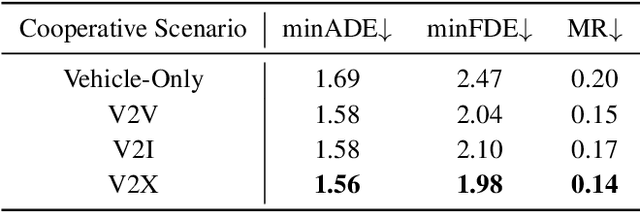
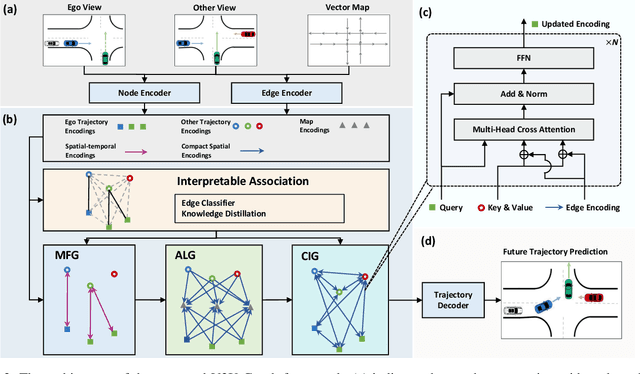
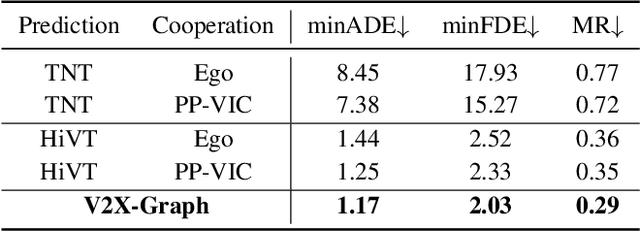
Motion forecasting is an essential task for autonomous driving, and the effective information utilization from infrastructure and other vehicles can enhance motion forecasting capabilities. Existing research have primarily focused on leveraging single-frame cooperative information to enhance the limited perception capability of the ego vehicle, while underutilizing the motion and interaction information of traffic participants observed from cooperative devices. In this paper, we first propose the cooperative trajectory representations learning paradigm. Specifically, we present V2X-Graph, the first interpretable and end-to-end learning framework for cooperative motion forecasting. V2X-Graph employs an interpretable graph to fully leverage the cooperative motion and interaction contexts. Experimental results on the vehicle-to-infrastructure (V2I) motion forecasting dataset, V2X-Seq, demonstrate the effectiveness of V2X-Graph. To further evaluate on V2X scenario, we construct the first real-world vehicle-to-everything (V2X) motion forecasting dataset V2X-Traj, and the performance shows the advantage of our method. We hope both V2X-Graph and V2X-Traj can facilitate the further development of cooperative motion forecasting. Find project at https://github.com/AIR-THU/V2X-Graph, find data at https://github.com/AIR-THU/DAIR-V2X-Seq.
V2X-Seq: A Large-Scale Sequential Dataset for Vehicle-Infrastructure Cooperative Perception and Forecasting
May 10, 2023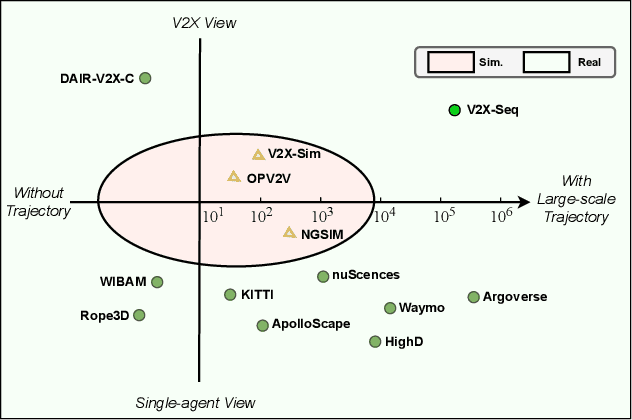
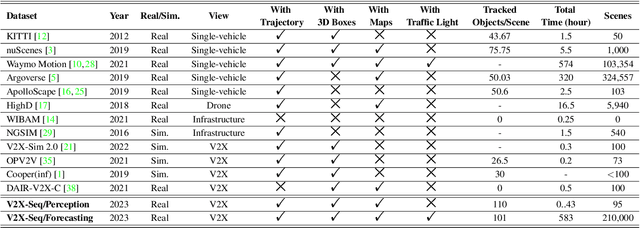
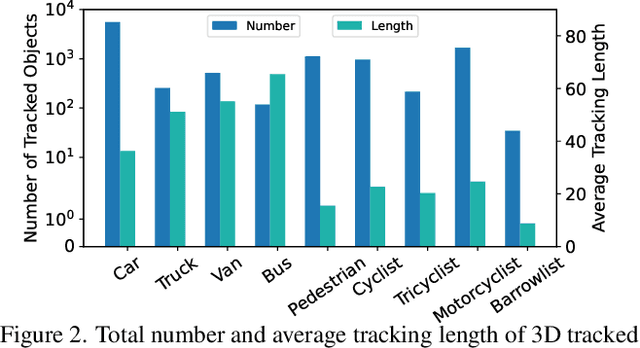
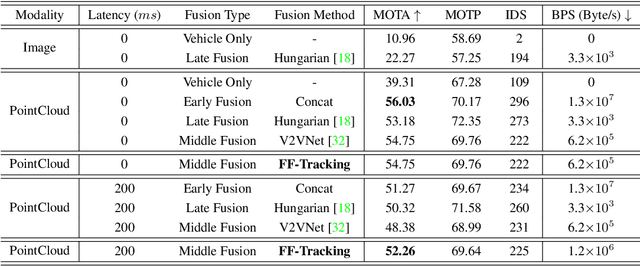
Utilizing infrastructure and vehicle-side information to track and forecast the behaviors of surrounding traffic participants can significantly improve decision-making and safety in autonomous driving. However, the lack of real-world sequential datasets limits research in this area. To address this issue, we introduce V2X-Seq, the first large-scale sequential V2X dataset, which includes data frames, trajectories, vector maps, and traffic lights captured from natural scenery. V2X-Seq comprises two parts: the sequential perception dataset, which includes more than 15,000 frames captured from 95 scenarios, and the trajectory forecasting dataset, which contains about 80,000 infrastructure-view scenarios, 80,000 vehicle-view scenarios, and 50,000 cooperative-view scenarios captured from 28 intersections' areas, covering 672 hours of data. Based on V2X-Seq, we introduce three new tasks for vehicle-infrastructure cooperative (VIC) autonomous driving: VIC3D Tracking, Online-VIC Forecasting, and Offline-VIC Forecasting. We also provide benchmarks for the introduced tasks. Find data, code, and more up-to-date information at \href{https://github.com/AIR-THU/DAIR-V2X-Seq}{https://github.com/AIR-THU/DAIR-V2X-Seq}.