 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSToFM: a Multi-scale Foundation Model for Spatial Transcriptomics
Jul 15, 2025Spatial Transcriptomics (ST) technologies provide biologists with rich insights into single-cell biology by preserving spatial context of cells. Building foundational models for ST can significantly enhance the analysis of vast and complex data sources, unlocking new perspectives on the intricacies of biological tissues. However, modeling ST data is inherently challenging due to the need to extract multi-scale information from tissue slices containing vast numbers of cells. This process requires integrating macro-scale tissue morphology, micro-scale cellular microenvironment, and gene-scale gene expression profile. To address this challenge, we propose SToFM, a multi-scale Spatial Transcriptomics Foundation Model. SToFM first performs multi-scale information extraction on each ST slice, to construct a set of ST sub-slices that aggregate macro-, micro- and gene-scale information. Then an SE(2) Transformer is used to obtain high-quality cell representations from the sub-slices. Additionally, we construct \textbf{SToCorpus-88M}, the largest high-resolution spatial transcriptomics corpus for pretraining. SToFM achieves outstanding performance on a variety of downstream tasks, such as tissue region semantic segmentation and cell type annotation, demonstrating its comprehensive understanding of ST data
OCSU: Optical Chemical Structure Understanding for Molecule-centric Scientific Discovery
Jan 26, 2025Understanding the chemical structure from a graphical representation of a molecule is a challenging image caption task that would greatly benefit molecule-centric scientific discovery. Variations in molecular images and caption subtasks pose a significant challenge in both image representation learning and task modeling. Yet, existing methods only focus on a specific caption task that translates a molecular image into its graph structure, i.e., OCSR. In this paper, we propose the Optical Chemical Structure Understanding (OCSU) task, which extends OCSR to molecular image caption from motif level to molecule level and abstract level. We present two approaches for that, including an OCSR-based method and an end-to-end OCSR-free method. The proposed Double-Check achieves SOTA OCSR performance on real-world patent and journal article scenarios via attentive feature enhancement for local ambiguous atoms. Cascading with SMILES-based molecule understanding methods, it can leverage the power of existing task-specific models for OCSU. While Mol-VL is an end-to-end optimized VLM-based model. An OCSU dataset, Vis-CheBI20, is built based on the widely used CheBI20 dataset for training and evaluation. Extensive experimental results on Vis-CheBI20 demonstrate the effectiveness of the proposed approaches. Improving OCSR capability can lead to a better OCSU performance for OCSR-based approach, and the SOTA performance of Mol-VL demonstrates the great potential of end-to-end approach.
MutaPLM: Protein Language Modeling for Mutation Explanation and Engineering
Oct 30, 2024



Studying protein mutations within amino acid sequences holds tremendous significance in life sciences. Protein language models (PLMs) have demonstrated strong capabilities in broad biological applications. However, due to architectural design and lack of supervision, PLMs model mutations implicitly with evolutionary plausibility, which is not satisfactory to serve as explainable and engineerable tools in real-world studies. To address these issues, we present MutaPLM, a unified framework for interpreting and navigating protein mutations with protein language models. MutaPLM introduces a protein delta network that captures explicit protein mutation representations within a unified feature space, and a transfer learning pipeline with a chain-of-thought (CoT) strategy to harvest protein mutation knowledge from biomedical texts. We also construct MutaDescribe, the first large-scale protein mutation dataset with rich textual annotations, which provides cross-modal supervision signals. Through comprehensive experiments, we demonstrate that MutaPLM excels at providing human-understandable explanations for mutational effects and prioritizing novel mutations with desirable properties. Our code, model, and data are open-sourced at https://github.com/PharMolix/MutaPLM.
Leveraging Temporal Contexts to Enhance Vehicle-Infrastructure Cooperative Perception
Aug 20, 2024Infrastructure sensors installed at elevated positions offer a broader perception range and encounter fewer occlusions. Integrating both infrastructure and ego-vehicle data through V2X communication, known as vehicle-infrastructure cooperation, has shown considerable advantages in enhancing perception capabilities and addressing corner cases encountered in single-vehicle autonomous driving. However, cooperative perception still faces numerous challenges, including limited communication bandwidth and practical communication interruptions. In this paper, we propose CTCE, a novel framework for cooperative 3D object detection. This framework transmits queries with temporal contexts enhancement, effectively balancing transmission efficiency and performance to accommodate real-world communication conditions. Additionally, we propose a temporal-guided fusion module to further improve performance. The roadside temporal enhancement and vehicle-side spatial-temporal fusion together constitute a multi-level temporal contexts integration mechanism, fully leveraging temporal information to enhance performance. Furthermore, a motion-aware reconstruction module is introduced to recover lost roadside queries due to communication interruptions. Experimental results on V2X-Seq and V2X-Sim datasets demonstrate that CTCE outperforms the baseline QUEST, achieving improvements of 3.8% and 1.3% in mAP, respectively. Experiments under communication interruption conditions validate CTCE's robustness to communication interruptions.
Learning Multi-view Molecular Representations with Structured and Unstructured Knowledge
Jun 14, 2024



Capturing molecular knowledge with representation learning approaches holds significant potential in vast scientific fields such as chemistry and life science. An effective and generalizable molecular representation is expected to capture the consensus and complementary molecular expertise from diverse views and perspectives. However, existing works fall short in learning multi-view molecular representations, due to challenges in explicitly incorporating view information and handling molecular knowledge from heterogeneous sources. To address these issues, we present MV-Mol, a molecular representation learning model that harvests multi-view molecular expertise from chemical structures, unstructured knowledge from biomedical texts, and structured knowledge from knowledge graphs. We utilize text prompts to model view information and design a fusion architecture to extract view-based molecular representations. We develop a two-stage pre-training procedure, exploiting heterogeneous data of varying quality and quantity. Through extensive experiments, we show that MV-Mol provides improved representations that substantially benefit molecular property prediction. Additionally, MV-Mol exhibits state-of-the-art performance in multi-modal comprehension of molecular structures and texts. Code and data are available at https://github.com/PharMolix/OpenBioMed.
LangCell: Language-Cell Pre-training for Cell Identity Understanding
May 09, 2024



Cell identity encompasses various semantic aspects of a cell, including cell type, pathway information, disease information, and more, which are essential for biologists to gain insights into its biological characteristics. Understanding cell identity from the transcriptomic data, such as annotating cell types, have become an important task in bioinformatics. As these semantic aspects are determined by human experts, it is impossible for AI models to effectively carry out cell identity understanding tasks without the supervision signals provided by single-cell and label pairs. The single-cell pre-trained language models (PLMs) currently used for this task are trained only on a single modality, transcriptomics data, lack an understanding of cell identity knowledge. As a result, they have to be fine-tuned for downstream tasks and struggle when lacking labeled data with the desired semantic labels. To address this issue, we propose an innovative solution by constructing a unified representation of single-cell data and natural language during the pre-training phase, allowing the model to directly incorporate insights related to cell identity. More specifically, we introduce \textbf{LangCell}, the first \textbf{Lang}uage-\textbf{Cell} pre-training framework. LangCell utilizes texts enriched with cell identity information to gain a profound comprehension of cross-modal knowledge. Results from experiments conducted on different benchmarks show that LangCell is the only single-cell PLM that can work effectively in zero-shot cell identity understanding scenarios, and also significantly outperforms existing models in few-shot and fine-tuning cell identity understanding scenarios.
RCooper: A Real-world Large-scale Dataset for Roadside Cooperative Perception
Mar 31, 2024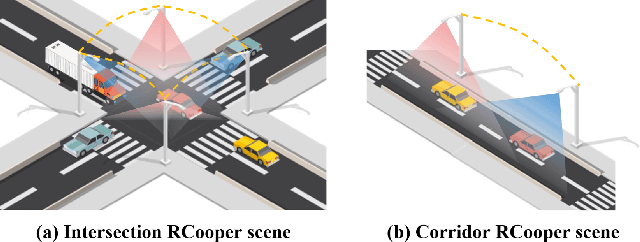
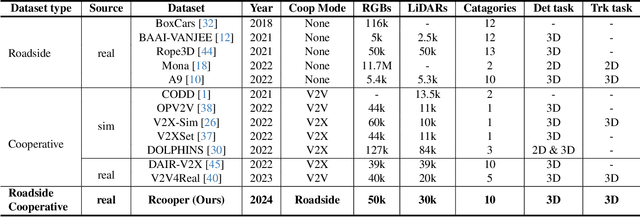
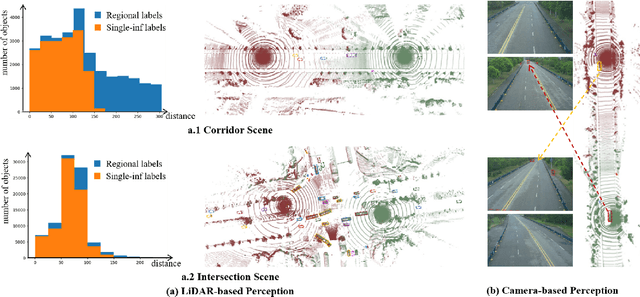

The value of roadside perception, which could extend the boundaries of autonomous driving and traffic management, has gradually become more prominent and acknowledged in recent years. However, existing roadside perception approaches only focus on the single-infrastructure sensor system, which cannot realize a comprehensive understanding of a traffic area because of the limited sensing range and blind spots. Orienting high-quality roadside perception, we need Roadside Cooperative Perception (RCooper) to achieve practical area-coverage roadside perception for restricted traffic areas. Rcooper has its own domain-specific challenges, but further exploration is hindered due to the lack of datasets. We hence release the first real-world, large-scale RCooper dataset to bloom the research on practical roadside cooperative perception, including detection and tracking. The manually annotated dataset comprises 50k images and 30k point clouds, including two representative traffic scenes (i.e., intersection and corridor). The constructed benchmarks prove the effectiveness of roadside cooperation perception and demonstrate the direction of further research. Codes and dataset can be accessed at: https://github.com/AIR-THU/DAIR-RCooper.
End-to-End Autonomous Driving through V2X Cooperation
Mar 31, 2024



Cooperatively utilizing both ego-vehicle and infrastructure sensor data via V2X communication has emerged as a promising approach for advanced autonomous driving. However, current research mainly focuses on improving individual modules, rather than taking end-to-end learning to optimize final planning performance, resulting in underutilized data potential. In this paper, we introduce UniV2X, a pioneering cooperative autonomous driving framework that seamlessly integrates all key driving modules across diverse views into a unified network. We propose a sparse-dense hybrid data transmission and fusion mechanism for effective vehicle-infrastructure cooperation, offering three advantages: 1) Effective for simultaneously enhancing agent perception, online mapping, and occupancy prediction, ultimately improving planning performance. 2) Transmission-friendly for practical and limited communication conditions. 3) Reliable data fusion with interpretability of this hybrid data. We implement UniV2X, as well as reproducing several benchmark methods, on the challenging DAIR-V2X, the real-world cooperative driving dataset. Experimental results demonstrate the effectiveness of UniV2X in significantly enhancing planning performance, as well as all intermediate output performance. Code is at https://github.com/AIR-THU/UniV2X.
Flow-Based Feature Fusion for Vehicle-Infrastructure Cooperative 3D Object Detection
Nov 03, 2023Cooperatively utilizing both ego-vehicle and infrastructure sensor data can significantly enhance autonomous driving perception abilities. However, the uncertain temporal asynchrony and limited communication conditions can lead to fusion misalignment and constrain the exploitation of infrastructure data. To address these issues in vehicle-infrastructure cooperative 3D (VIC3D) object detection, we propose the Feature Flow Net (FFNet), a novel cooperative detection framework. FFNet is a flow-based feature fusion framework that uses a feature flow prediction module to predict future features and compensate for asynchrony. Instead of transmitting feature maps extracted from still-images, FFNet transmits feature flow, leveraging the temporal coherence of sequential infrastructure frames. Furthermore, we introduce a self-supervised training approach that enables FFNet to generate feature flow with feature prediction ability from raw infrastructure sequences. Experimental results demonstrate that our proposed method outperforms existing cooperative detection methods while only requiring about 1/100 of the transmission cost of raw data and covers all latency in one model on the DAIR-V2X dataset. The code is available at \href{https://github.com/haibao-yu/FFNet-VIC3D}{https://github.com/haibao-yu/FFNet-VIC3D}.
Learning Cooperative Trajectory Representations for Motion Forecasting
Nov 01, 2023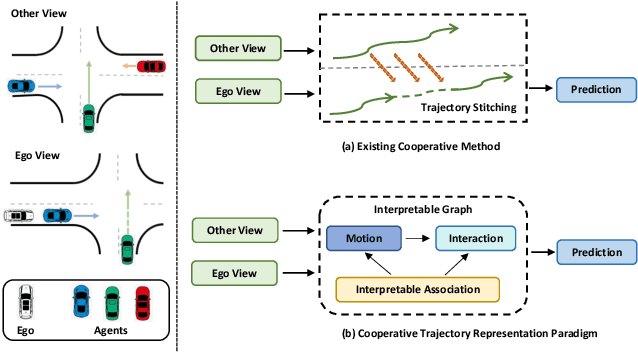
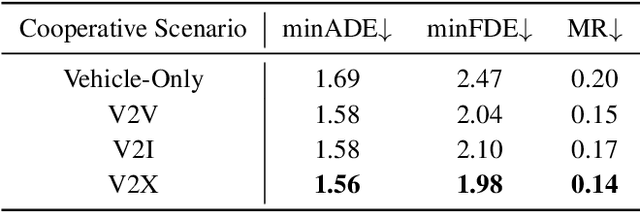
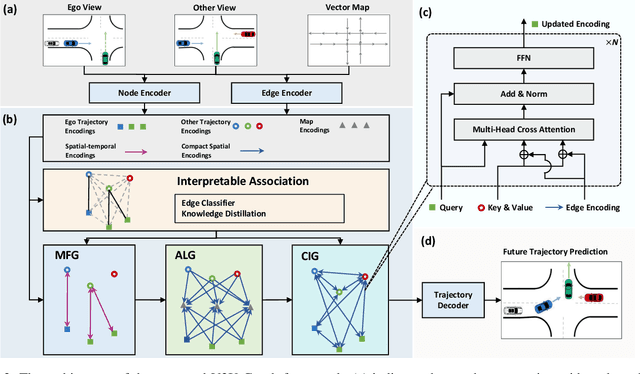
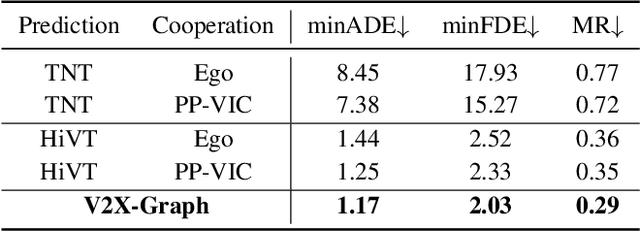
Motion forecasting is an essential task for autonomous driving, and the effective information utilization from infrastructure and other vehicles can enhance motion forecasting capabilities. Existing research have primarily focused on leveraging single-frame cooperative information to enhance the limited perception capability of the ego vehicle, while underutilizing the motion and interaction information of traffic participants observed from cooperative devices. In this paper, we first propose the cooperative trajectory representations learning paradigm. Specifically, we present V2X-Graph, the first interpretable and end-to-end learning framework for cooperative motion forecasting. V2X-Graph employs an interpretable graph to fully leverage the cooperative motion and interaction contexts. Experimental results on the vehicle-to-infrastructure (V2I) motion forecasting dataset, V2X-Seq, demonstrate the effectiveness of V2X-Graph. To further evaluate on V2X scenario, we construct the first real-world vehicle-to-everything (V2X) motion forecasting dataset V2X-Traj, and the performance shows the advantage of our method. We hope both V2X-Graph and V2X-Traj can facilitate the further development of cooperative motion forecasting. Find project at https://github.com/AIR-THU/V2X-Graph, find data at https://github.com/AIR-THU/DAIR-V2X-Seq.