 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforced Reasoning for End-to-End Retrosynthetic Planning
Mar 31, 2026Retrosynthetic planning is a fundamental task in organic chemistry, yet remains challenging due to its combinatorial complexity. To address this, conventional approaches typically rely on hybrid frameworks that combine single-step predictions with external search heuristics, inevitably fracturing the logical coherence between local molecular transformations and global planning objectives. To bridge this gap and embed sophisticated strategic foresight directly into the model's chemical reasoning, we introduce ReTriP, an end-to-end generative framework that reformulates retrosynthesis as a direct Chain-of-Thought reasoning task. We establish a path-coherent molecular representation and employ a progressive training curriculum that transitions from reasoning distillation to reinforcement learning with verifiable rewards, effectively aligning stepwise generation with practical route utility. Empirical evaluation on RetroBench demonstrates that ReTriP achieves state-of-the-art performance, exhibiting superior robustness in long-horizon planning compared to hybrid baselines.
SToFM: a Multi-scale Foundation Model for Spatial Transcriptomics
Jul 15, 2025Spatial Transcriptomics (ST) technologies provide biologists with rich insights into single-cell biology by preserving spatial context of cells. Building foundational models for ST can significantly enhance the analysis of vast and complex data sources, unlocking new perspectives on the intricacies of biological tissues. However, modeling ST data is inherently challenging due to the need to extract multi-scale information from tissue slices containing vast numbers of cells. This process requires integrating macro-scale tissue morphology, micro-scale cellular microenvironment, and gene-scale gene expression profile. To address this challenge, we propose SToFM, a multi-scale Spatial Transcriptomics Foundation Model. SToFM first performs multi-scale information extraction on each ST slice, to construct a set of ST sub-slices that aggregate macro-, micro- and gene-scale information. Then an SE(2) Transformer is used to obtain high-quality cell representations from the sub-slices. Additionally, we construct \textbf{SToCorpus-88M}, the largest high-resolution spatial transcriptomics corpus for pretraining. SToFM achieves outstanding performance on a variety of downstream tasks, such as tissue region semantic segmentation and cell type annotation, demonstrating its comprehensive understanding of ST data
MutaPLM: Protein Language Modeling for Mutation Explanation and Engineering
Oct 30, 2024



Studying protein mutations within amino acid sequences holds tremendous significance in life sciences. Protein language models (PLMs) have demonstrated strong capabilities in broad biological applications. However, due to architectural design and lack of supervision, PLMs model mutations implicitly with evolutionary plausibility, which is not satisfactory to serve as explainable and engineerable tools in real-world studies. To address these issues, we present MutaPLM, a unified framework for interpreting and navigating protein mutations with protein language models. MutaPLM introduces a protein delta network that captures explicit protein mutation representations within a unified feature space, and a transfer learning pipeline with a chain-of-thought (CoT) strategy to harvest protein mutation knowledge from biomedical texts. We also construct MutaDescribe, the first large-scale protein mutation dataset with rich textual annotations, which provides cross-modal supervision signals. Through comprehensive experiments, we demonstrate that MutaPLM excels at providing human-understandable explanations for mutational effects and prioritizing novel mutations with desirable properties. Our code, model, and data are open-sourced at https://github.com/PharMolix/MutaPLM.
Learning Multi-view Molecular Representations with Structured and Unstructured Knowledge
Jun 14, 2024



Capturing molecular knowledge with representation learning approaches holds significant potential in vast scientific fields such as chemistry and life science. An effective and generalizable molecular representation is expected to capture the consensus and complementary molecular expertise from diverse views and perspectives. However, existing works fall short in learning multi-view molecular representations, due to challenges in explicitly incorporating view information and handling molecular knowledge from heterogeneous sources. To address these issues, we present MV-Mol, a molecular representation learning model that harvests multi-view molecular expertise from chemical structures, unstructured knowledge from biomedical texts, and structured knowledge from knowledge graphs. We utilize text prompts to model view information and design a fusion architecture to extract view-based molecular representations. We develop a two-stage pre-training procedure, exploiting heterogeneous data of varying quality and quantity. Through extensive experiments, we show that MV-Mol provides improved representations that substantially benefit molecular property prediction. Additionally, MV-Mol exhibits state-of-the-art performance in multi-modal comprehension of molecular structures and texts. Code and data are available at https://github.com/PharMolix/OpenBioMed.
LangCell: Language-Cell Pre-training for Cell Identity Understanding
May 09, 2024



Cell identity encompasses various semantic aspects of a cell, including cell type, pathway information, disease information, and more, which are essential for biologists to gain insights into its biological characteristics. Understanding cell identity from the transcriptomic data, such as annotating cell types, have become an important task in bioinformatics. As these semantic aspects are determined by human experts, it is impossible for AI models to effectively carry out cell identity understanding tasks without the supervision signals provided by single-cell and label pairs. The single-cell pre-trained language models (PLMs) currently used for this task are trained only on a single modality, transcriptomics data, lack an understanding of cell identity knowledge. As a result, they have to be fine-tuned for downstream tasks and struggle when lacking labeled data with the desired semantic labels. To address this issue, we propose an innovative solution by constructing a unified representation of single-cell data and natural language during the pre-training phase, allowing the model to directly incorporate insights related to cell identity. More specifically, we introduce \textbf{LangCell}, the first \textbf{Lang}uage-\textbf{Cell} pre-training framework. LangCell utilizes texts enriched with cell identity information to gain a profound comprehension of cross-modal knowledge. Results from experiments conducted on different benchmarks show that LangCell is the only single-cell PLM that can work effectively in zero-shot cell identity understanding scenarios, and also significantly outperforms existing models in few-shot and fine-tuning cell identity understanding scenarios.
Empowering AI drug discovery with explicit and implicit knowledge
Apr 17, 2023Motivation: Recently, research on independently utilizing either explicit knowledge from knowledge graphs or implicit knowledge from biomedical literature for AI drug discovery has been growing rapidly. These approaches have greatly improved the prediction accuracy of AI models on multiple downstream tasks. However, integrating explicit and implicit knowledge independently hinders their understanding of molecules. Results: We propose DeepEIK, a unified deep learning framework that incorporates both explicit and implicit knowledge for AI drug discovery. We adopt feature fusion to process the multi-modal inputs, and leverage the attention mechanism to denoise the text information. Experiments show that DeepEIK significantly outperforms state-of-the-art methods on crucial tasks in AI drug discovery including drug-target interaction prediction, drug property prediction and protein-protein interaction prediction. Further studies show that benefiting from explicit and implicit knowledge, our framework achieves a deeper understanding of molecules and shows promising potential in facilitating drug discovery applications.
DAIR-V2X: A Large-Scale Dataset for Vehicle-Infrastructure Cooperative 3D Object Detection
Apr 12, 2022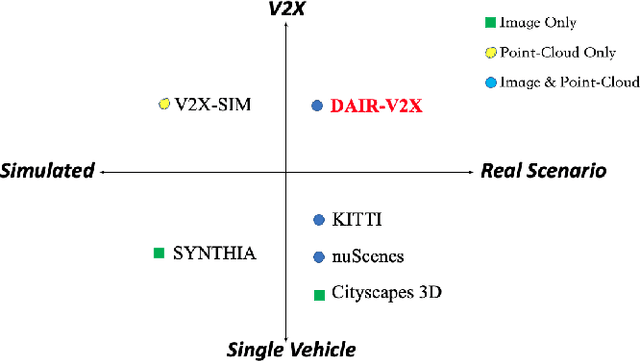
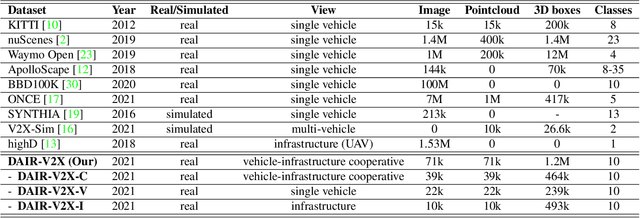
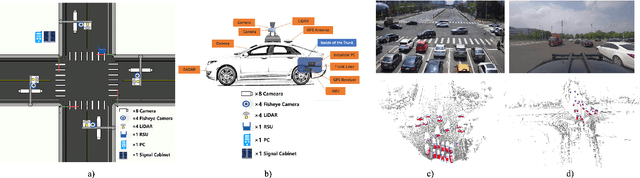
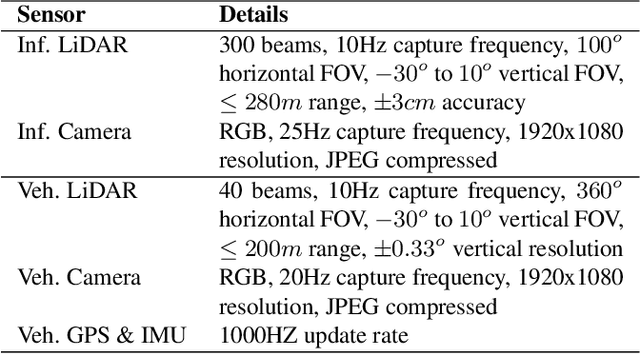
Autonomous driving faces great safety challenges for a lack of global perspective and the limitation of long-range perception capabilities. It has been widely agreed that vehicle-infrastructure cooperation is required to achieve Level 5 autonomy. However, there is still NO dataset from real scenarios available for computer vision researchers to work on vehicle-infrastructure cooperation-related problems. To accelerate computer vision research and innovation for Vehicle-Infrastructure Cooperative Autonomous Driving (VICAD), we release DAIR-V2X Dataset, which is the first large-scale, multi-modality, multi-view dataset from real scenarios for VICAD. DAIR-V2X comprises 71254 LiDAR frames and 71254 Camera frames, and all frames are captured from real scenes with 3D annotations. The Vehicle-Infrastructure Cooperative 3D Object Detection problem (VIC3D) is introduced, formulating the problem of collaboratively locating and identifying 3D objects using sensory inputs from both vehicle and infrastructure. In addition to solving traditional 3D object detection problems, the solution of VIC3D needs to consider the temporal asynchrony problem between vehicle and infrastructure sensors and the data transmission cost between them. Furthermore, we propose Time Compensation Late Fusion (TCLF), a late fusion framework for the VIC3D task as a benchmark based on DAIR-V2X. Find data, code, and more up-to-date information at https://thudair.baai.ac.cn/index and https://github.com/AIR-THU/DAIR-V2X.
CogDL: An Extensive Toolkit for Deep Learning on Graphs
Mar 01, 2021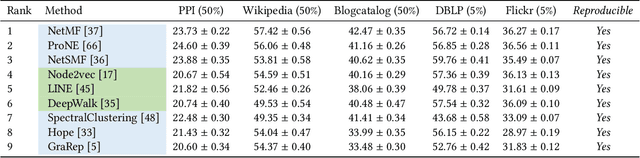
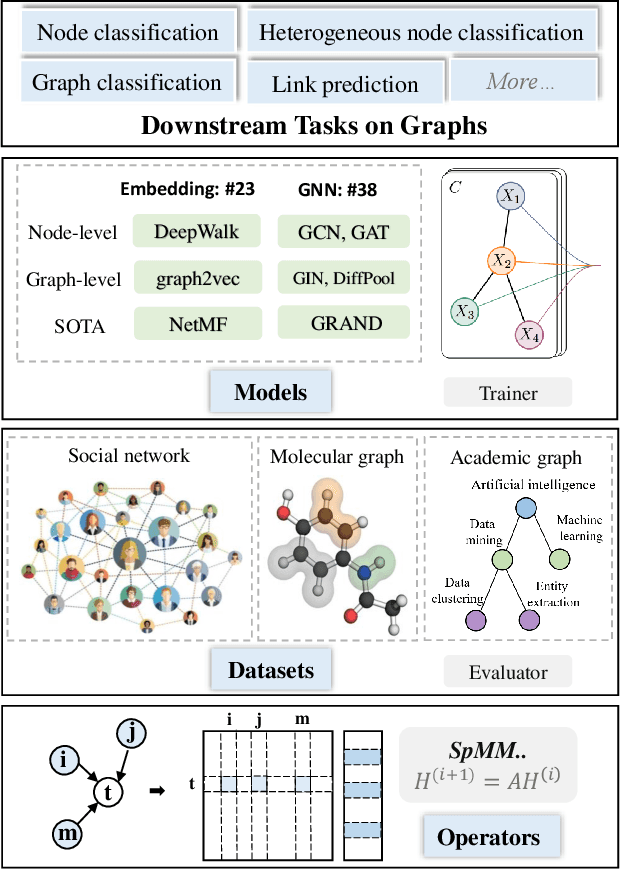
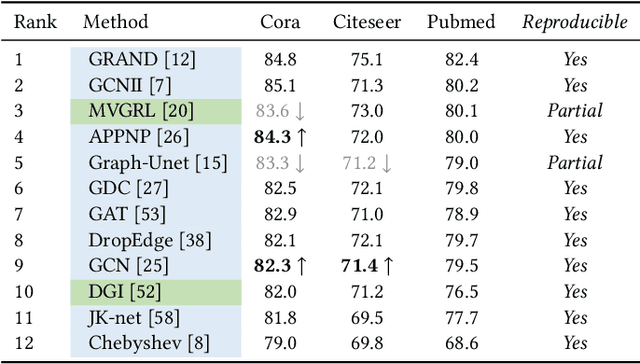
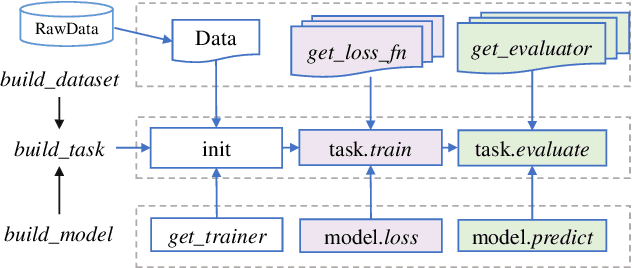
Graph representation learning aims to learn low-dimensional node embeddings for graphs. It is used in several real-world applications such as social network analysis and large-scale recommender systems. In this paper, we introduce CogDL, an extensive research toolkit for deep learning on graphs that allows researchers and developers to easily conduct experiments and build applications. It provides standard training and evaluation for the most important tasks in the graph domain, including node classification, link prediction, graph classification, and other graph tasks. For each task, it offers implementations of state-of-the-art models. The models in our toolkit are divided into two major parts, graph embedding methods and graph neural networks. Most of the graph embedding methods learn node-level or graph-level representations in an unsupervised way and preserves the graph properties such as structural information, while graph neural networks capture node features and work in semi-supervised or self-supervised settings. All models implemented in our toolkit can be easily reproducible for leaderboard results. Most models in CogDL are developed on top of PyTorch, and users can leverage the advantages of PyTorch to implement their own models. Furthermore, we demonstrate the effectiveness of CogDL for real-world applications in AMiner, which is a large academic database and system.