 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInternVL-X: Advancing and Accelerating InternVL Series with Efficient Visual Token Compression
Mar 27, 2025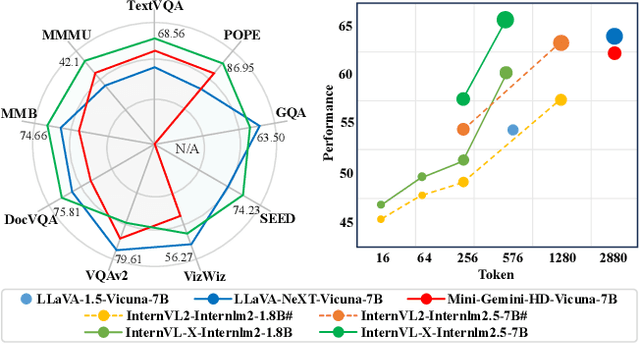



Most multimodal large language models (MLLMs) treat visual tokens as "a sequence of text", integrating them with text tokens into a large language model (LLM). However, a great quantity of visual tokens significantly increases the demand for computational resources and time. In this paper, we propose InternVL-X, which outperforms the InternVL model in both performance and efficiency by incorporating three visual token compression methods. First, we propose a novel vision-language projector, PVTC. This component integrates adjacent visual embeddings to form a local query and utilizes the transformed CLS token as a global query, then performs point-to-region cross-attention through these local and global queries to more effectively convert visual features. Second, we present a layer-wise visual token compression module, LVTC, which compresses tokens in the LLM shallow layers and then expands them through upsampling and residual connections in the deeper layers. This significantly enhances the model computational efficiency. Futhermore, we propose an efficient high resolution slicing method, RVTC, which dynamically adjusts the number of visual tokens based on image area or length filtering. RVTC greatly enhances training efficiency with only a slight reduction in performance. By utilizing 20% or fewer visual tokens, InternVL-X achieves state-of-the-art performance on 7 public MLLM benchmarks, and improves the average metric by 2.34% across 12 tasks.
DAIR-V2X: A Large-Scale Dataset for Vehicle-Infrastructure Cooperative 3D Object Detection
Apr 12, 2022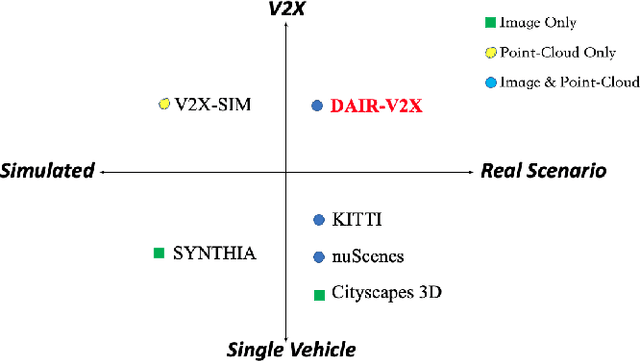
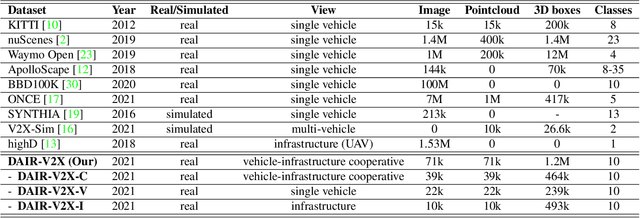
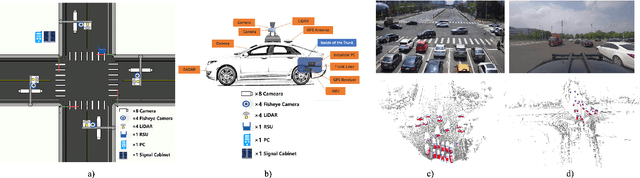
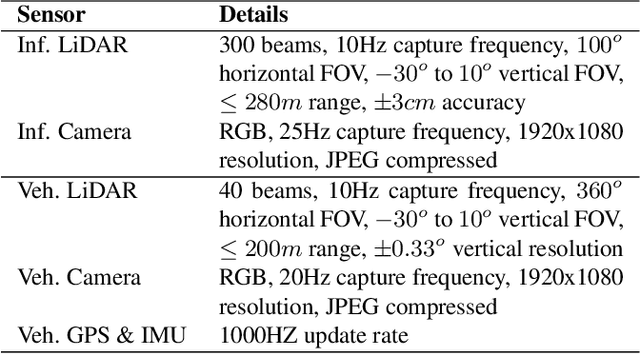
Autonomous driving faces great safety challenges for a lack of global perspective and the limitation of long-range perception capabilities. It has been widely agreed that vehicle-infrastructure cooperation is required to achieve Level 5 autonomy. However, there is still NO dataset from real scenarios available for computer vision researchers to work on vehicle-infrastructure cooperation-related problems. To accelerate computer vision research and innovation for Vehicle-Infrastructure Cooperative Autonomous Driving (VICAD), we release DAIR-V2X Dataset, which is the first large-scale, multi-modality, multi-view dataset from real scenarios for VICAD. DAIR-V2X comprises 71254 LiDAR frames and 71254 Camera frames, and all frames are captured from real scenes with 3D annotations. The Vehicle-Infrastructure Cooperative 3D Object Detection problem (VIC3D) is introduced, formulating the problem of collaboratively locating and identifying 3D objects using sensory inputs from both vehicle and infrastructure. In addition to solving traditional 3D object detection problems, the solution of VIC3D needs to consider the temporal asynchrony problem between vehicle and infrastructure sensors and the data transmission cost between them. Furthermore, we propose Time Compensation Late Fusion (TCLF), a late fusion framework for the VIC3D task as a benchmark based on DAIR-V2X. Find data, code, and more up-to-date information at https://thudair.baai.ac.cn/index and https://github.com/AIR-THU/DAIR-V2X.
Rope3D: TheRoadside Perception Dataset for Autonomous Driving and Monocular 3D Object Detection Task
Mar 25, 2022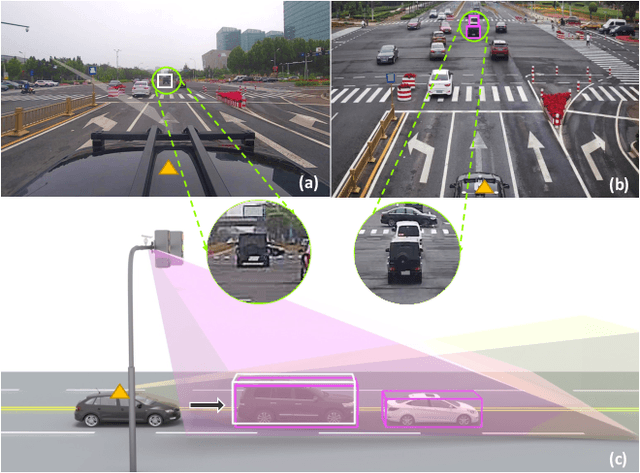
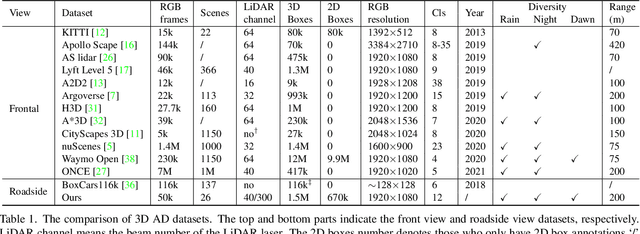

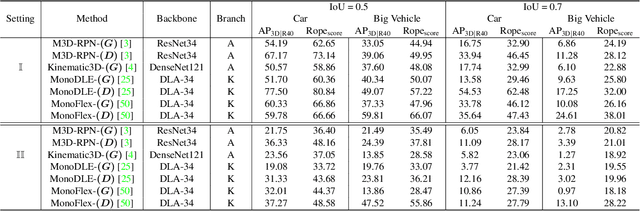
Concurrent perception datasets for autonomous driving are mainly limited to frontal view with sensors mounted on the vehicle. None of them is designed for the overlooked roadside perception tasks. On the other hand, the data captured from roadside cameras have strengths over frontal-view data, which is believed to facilitate a safer and more intelligent autonomous driving system. To accelerate the progress of roadside perception, we present the first high-diversity challenging Roadside Perception 3D dataset- Rope3D from a novel view. The dataset consists of 50k images and over 1.5M 3D objects in various scenes, which are captured under different settings including various cameras with ambiguous mounting positions, camera specifications, viewpoints, and different environmental conditions. We conduct strict 2D-3D joint annotation and comprehensive data analysis, as well as set up a new 3D roadside perception benchmark with metrics and evaluation devkit. Furthermore, we tailor the existing frontal-view monocular 3D object detection approaches and propose to leverage the geometry constraint to solve the inherent ambiguities caused by various sensors, viewpoints. Our dataset is available on https://thudair.baai.ac.cn/rope.