 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInternVL-X: Advancing and Accelerating InternVL Series with Efficient Visual Token Compression
Mar 27, 2025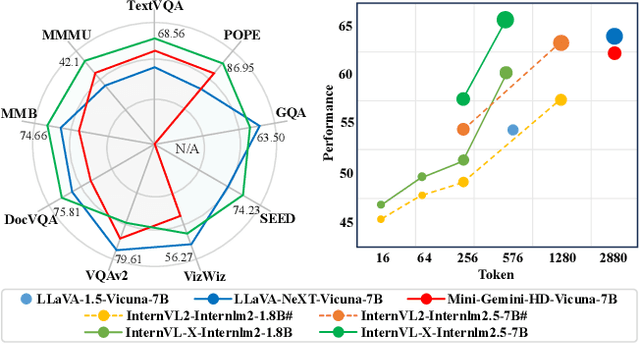



Most multimodal large language models (MLLMs) treat visual tokens as "a sequence of text", integrating them with text tokens into a large language model (LLM). However, a great quantity of visual tokens significantly increases the demand for computational resources and time. In this paper, we propose InternVL-X, which outperforms the InternVL model in both performance and efficiency by incorporating three visual token compression methods. First, we propose a novel vision-language projector, PVTC. This component integrates adjacent visual embeddings to form a local query and utilizes the transformed CLS token as a global query, then performs point-to-region cross-attention through these local and global queries to more effectively convert visual features. Second, we present a layer-wise visual token compression module, LVTC, which compresses tokens in the LLM shallow layers and then expands them through upsampling and residual connections in the deeper layers. This significantly enhances the model computational efficiency. Futhermore, we propose an efficient high resolution slicing method, RVTC, which dynamically adjusts the number of visual tokens based on image area or length filtering. RVTC greatly enhances training efficiency with only a slight reduction in performance. By utilizing 20% or fewer visual tokens, InternVL-X achieves state-of-the-art performance on 7 public MLLM benchmarks, and improves the average metric by 2.34% across 12 tasks.
Towards Aligned Data Forgetting via Twin Machine Unlearning
Jan 15, 2025Modern privacy regulations have spurred the evolution of machine unlearning, a technique enabling a trained model to efficiently forget specific training data. In prior unlearning methods, the concept of "data forgetting" is often interpreted and implemented as achieving zero classification accuracy on such data. Nevertheless, the authentic aim of machine unlearning is to achieve alignment between the unlearned model and the gold model, i.e., encouraging them to have identical classification accuracy. On the other hand, the gold model often exhibits non-zero classification accuracy due to its generalization ability. To achieve aligned data forgetting, we propose a Twin Machine Unlearning (TMU) approach, where a twin unlearning problem is defined corresponding to the original unlearning problem. Consequently, the generalization-label predictor trained on the twin problem can be transferred to the original problem, facilitating aligned data forgetting. Comprehensive empirical experiments illustrate that our approach significantly enhances the alignment between the unlearned model and the gold model.
Towards Aligned Data Removal via Twin Machine Unlearning
Aug 21, 2024



Modern privacy regulations have spurred the evolution of machine unlearning, a technique that enables the removal of data from an already trained ML model without requiring retraining from scratch. Previous unlearning methods tend to induce the model to achieve lowest classification accuracy on the removal data. Nonetheless, the authentic objective of machine unlearning is to align the unlearned model with the gold model, i.e., achieving the same classification accuracy as the gold model. For this purpose, we present a Twin Machine Unlearning (TMU) approach, where a twin unlearning problem is defined corresponding to the original unlearning problem. As a results, the generalization-label predictor trained on the twin problem can be transferred to the original problem, facilitating aligned data removal. Comprehensive empirical experiments illustrate that our approach significantly enhances the alignment between the unlearned model and the gold model. Meanwhile, our method allows data removal without compromising the model accuracy.
Efficient LLM-Jailbreaking by Introducing Visual Modality
May 30, 2024This paper focuses on jailbreaking attacks against large language models (LLMs), eliciting them to generate objectionable content in response to harmful user queries. Unlike previous LLM-jailbreaks that directly orient to LLMs, our approach begins by constructing a multimodal large language model (MLLM) through the incorporation of a visual module into the target LLM. Subsequently, we conduct an efficient MLLM-jailbreak to generate jailbreaking embeddings embJS. Finally, we convert the embJS into text space to facilitate the jailbreaking of the target LLM. Compared to direct LLM-jailbreaking, our approach is more efficient, as MLLMs are more vulnerable to jailbreaking than pure LLM. Additionally, to improve the attack success rate (ASR) of jailbreaking, we propose an image-text semantic matching scheme to identify a suitable initial input. Extensive experiments demonstrate that our approach surpasses current state-of-the-art methods in terms of both efficiency and effectiveness. Moreover, our approach exhibits superior cross-class jailbreaking capabilities.
Towards Unified Robustness Against Both Backdoor and Adversarial Attacks
May 28, 2024Deep Neural Networks (DNNs) are known to be vulnerable to both backdoor and adversarial attacks. In the literature, these two types of attacks are commonly treated as distinct robustness problems and solved separately, since they belong to training-time and inference-time attacks respectively. However, this paper revealed that there is an intriguing connection between them: (1) planting a backdoor into a model will significantly affect the model's adversarial examples; (2) for an infected model, its adversarial examples have similar features as the triggered images. Based on these observations, a novel Progressive Unified Defense (PUD) algorithm is proposed to defend against backdoor and adversarial attacks simultaneously. Specifically, our PUD has a progressive model purification scheme to jointly erase backdoors and enhance the model's adversarial robustness. At the early stage, the adversarial examples of infected models are utilized to erase backdoors. With the backdoor gradually erased, our model purification can naturally turn into a stage to boost the model's robustness against adversarial attacks. Besides, our PUD algorithm can effectively identify poisoned images, which allows the initial extra dataset not to be completely clean. Extensive experimental results show that, our discovered connection between backdoor and adversarial attacks is ubiquitous, no matter what type of backdoor attack. The proposed PUD outperforms the state-of-the-art backdoor defense, including the model repairing-based and data filtering-based methods. Besides, it also has the ability to compete with the most advanced adversarial defense methods.
Active Admittance Control with Iterative Learning for General-Purpose Contact-Rich Manipulation
Mar 25, 2024

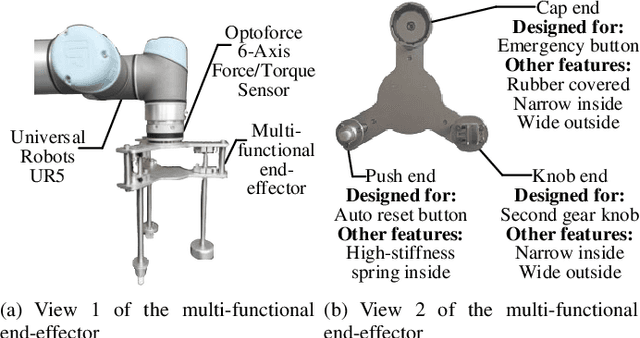
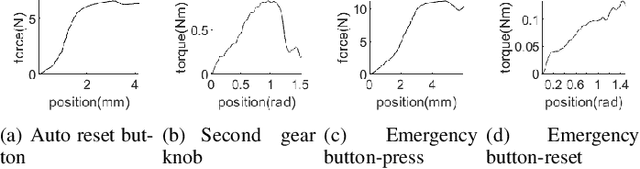
Force interaction is inevitable when robots face multiple operation scenarios. How to make the robot competent in force control for generalized operations such as multi-tasks still remains a challenging problem. Aiming at the reproducibility of interaction tasks and the lack of a generalized force control framework for multi-task scenarios, this paper proposes a novel hybrid control framework based on active admittance control with iterative learning parameters-tunning mechanism. The method adopts admittance control as the underlying algorithm to ensure flexibility, and iterative learning as the high-level algorithm to regulate the parameters of the admittance model. The whole algorithm has flexibility and learning ability, which is capable of achieving the goal of excellent versatility. Four representative interactive robot manipulation tasks are chosen to investigate the consistency and generalisability of the proposed method. Experiments are designed to verify the effectiveness of the whole framework, and an average of 98.21% and 91.52% improvement of RMSE is obtained relative to the traditional admittance control as well as the model-free adaptive control, respectively.
A Lightweight Deep Network for Efficient CSI Feedback in Massive MIMO Systems
May 21, 2021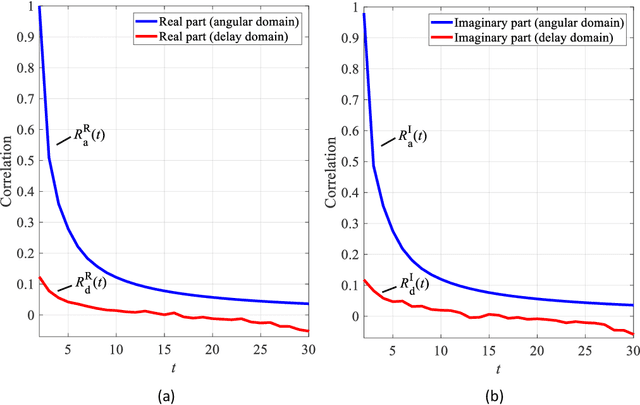
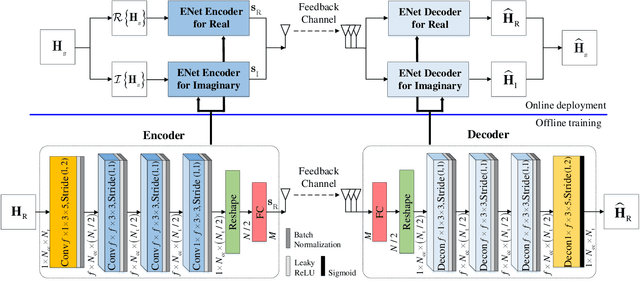
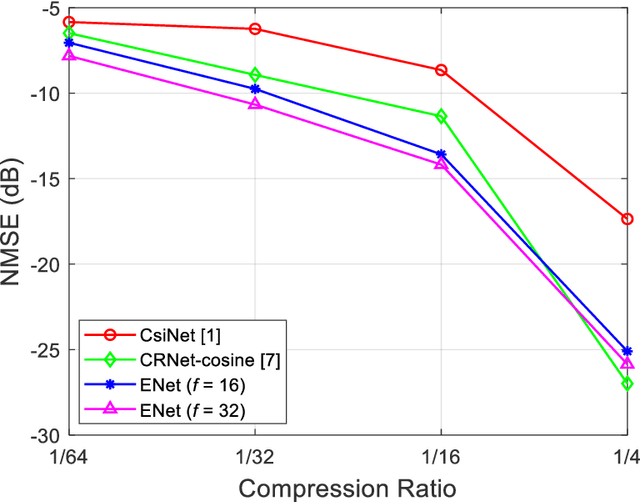
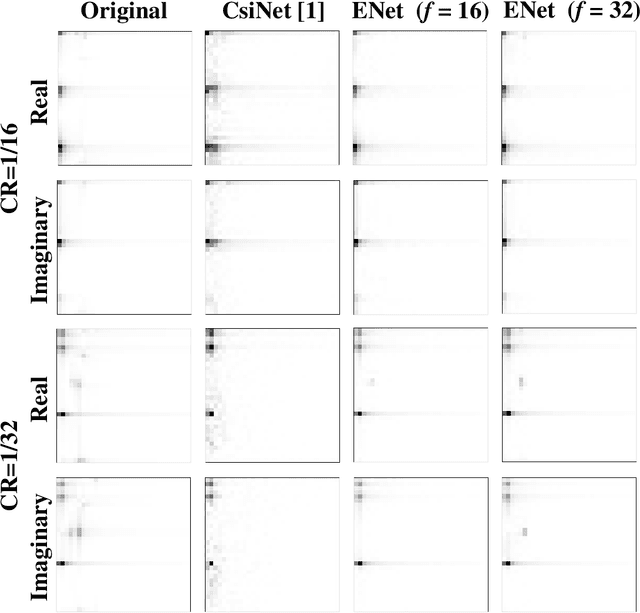
To fully exploit the advantages of massive multiple-input multiple-output (m-MIMO), accurate channel state information (CSI) is required at the transmitter. However, excessive CSI feedback for large antenna arrays is inefficient and thus undesirable in practical applications. By exploiting the inherent correlation characteristics of complex-valued channel responses in the angular-delay domain, we propose a novel neural network (NN) architecture, namely ENet, for CSI compression and feedback in m-MIMO. Even if the ENet processes the real and imaginary parts of the CSI values separately, its special structure enables the network trained for the real part only to be reused for the imaginary part. The proposed ENet shows enhanced performance with the network size reduced by nearly an order of magnitude compared to the existing NN-based solutions. Experimental results verify the effectiveness of the proposed ENet.