 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFissionVAE: Federated Non-IID Image Generation with Latent Space and Decoder Decomposition
Aug 30, 2024



Federated learning is a machine learning paradigm that enables decentralized clients to collaboratively learn a shared model while keeping all the training data local. While considerable research has focused on federated image generation, particularly Generative Adversarial Networks, Variational Autoencoders have received less attention. In this paper, we address the challenges of non-IID (independently and identically distributed) data environments featuring multiple groups of images of different types. Specifically, heterogeneous data distributions can lead to difficulties in maintaining a consistent latent space and can also result in local generators with disparate texture features being blended during aggregation. We introduce a novel approach, FissionVAE, which decomposes the latent space and constructs decoder branches tailored to individual client groups. This method allows for customized learning that aligns with the unique data distributions of each group. Additionally, we investigate the incorporation of hierarchical VAE architectures and demonstrate the use of heterogeneous decoder architectures within our model. We also explore strategies for setting the latent prior distributions to enhance the decomposition process. To evaluate our approach, we assemble two composite datasets: the first combines MNIST and FashionMNIST; the second comprises RGB datasets of cartoon and human faces, wild animals, marine vessels, and remote sensing images of Earth. Our experiments demonstrate that FissionVAE greatly improves generation quality on these datasets compared to baseline federated VAE models.
Efficient LLM-Jailbreaking by Introducing Visual Modality
May 30, 2024This paper focuses on jailbreaking attacks against large language models (LLMs), eliciting them to generate objectionable content in response to harmful user queries. Unlike previous LLM-jailbreaks that directly orient to LLMs, our approach begins by constructing a multimodal large language model (MLLM) through the incorporation of a visual module into the target LLM. Subsequently, we conduct an efficient MLLM-jailbreak to generate jailbreaking embeddings embJS. Finally, we convert the embJS into text space to facilitate the jailbreaking of the target LLM. Compared to direct LLM-jailbreaking, our approach is more efficient, as MLLMs are more vulnerable to jailbreaking than pure LLM. Additionally, to improve the attack success rate (ASR) of jailbreaking, we propose an image-text semantic matching scheme to identify a suitable initial input. Extensive experiments demonstrate that our approach surpasses current state-of-the-art methods in terms of both efficiency and effectiveness. Moreover, our approach exhibits superior cross-class jailbreaking capabilities.
Gradient Leakage Defense with Key-Lock Module for Federated Learning
May 06, 2023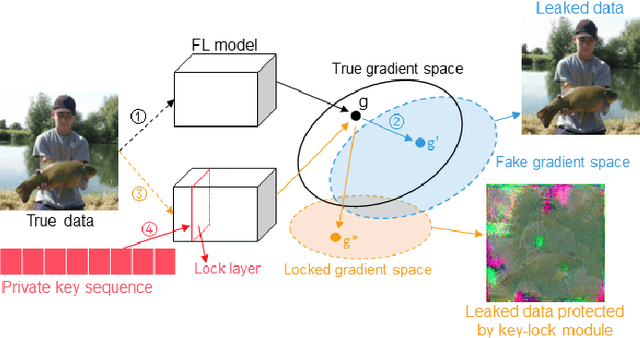

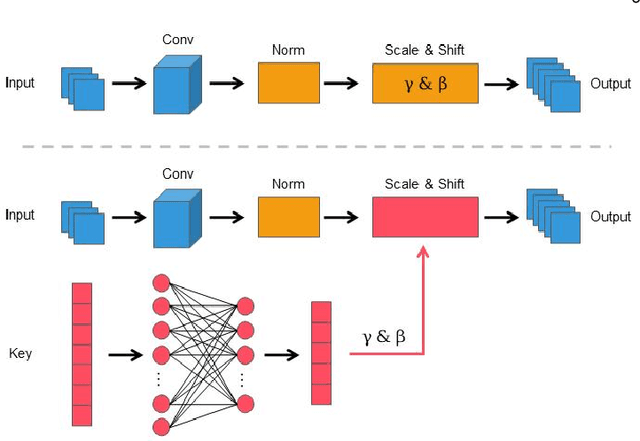
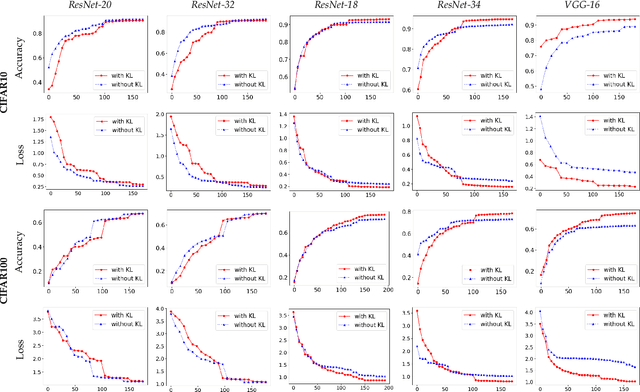
Federated Learning (FL) is a widely adopted privacy-preserving machine learning approach where private data remains local, enabling secure computations and the exchange of local model gradients between local clients and third-party parameter servers. However, recent findings reveal that privacy may be compromised and sensitive information potentially recovered from shared gradients. In this study, we offer detailed analysis and a novel perspective on understanding the gradient leakage problem. These theoretical works lead to a new gradient leakage defense technique that secures arbitrary model architectures using a private key-lock module. Only the locked gradient is transmitted to the parameter server for global model aggregation. Our proposed learning method is resistant to gradient leakage attacks, and the key-lock module is designed and trained to ensure that, without the private information of the key-lock module: a) reconstructing private training data from the shared gradient is infeasible; and b) the global model's inference performance is significantly compromised. We discuss the theoretical underpinnings of why gradients can leak private information and provide theoretical proof of our method's effectiveness. We conducted extensive empirical evaluations with a total of forty-four models on several popular benchmarks, demonstrating the robustness of our proposed approach in both maintaining model performance and defending against gradient leakage attacks.
Generative Graph Neural Networks for Link Prediction
Dec 31, 2022



Inferring missing links or detecting spurious ones based on observed graphs, known as link prediction, is a long-standing challenge in graph data analysis. With the recent advances in deep learning, graph neural networks have been used for link prediction and have achieved state-of-the-art performance. Nevertheless, existing methods developed for this purpose are typically discriminative, computing features of local subgraphs around two neighboring nodes and predicting potential links between them from the perspective of subgraph classification. In this formalism, the selection of enclosing subgraphs and heuristic structural features for subgraph classification significantly affects the performance of the methods. To overcome this limitation, this paper proposes a novel and radically different link prediction algorithm based on the network reconstruction theory, called GraphLP. Instead of sampling positive and negative links and heuristically computing the features of their enclosing subgraphs, GraphLP utilizes the feature learning ability of deep-learning models to automatically extract the structural patterns of graphs for link prediction under the assumption that real-world graphs are not locally isolated. Moreover, GraphLP explores high-order connectivity patterns to utilize the hierarchical organizational structures of graphs for link prediction. Our experimental results on all common benchmark datasets from different applications demonstrate that the proposed method consistently outperforms other state-of-the-art methods. Unlike the discriminative neural network models used for link prediction, GraphLP is generative, which provides a new paradigm for neural-network-based link prediction.