 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMLLM Machine Unlearning via Visual Knowledge Distillation
Dec 12, 2025Recently, machine unlearning approaches have been proposed to remove sensitive information from well-trained large models. However, most existing methods are tailored for LLMs, while MLLM-oriented unlearning remains at its early stage. Inspired by recent studies exploring the internal mechanisms of MLLMs, we propose to disentangle the visual and textual knowledge embedded within MLLMs and introduce a dedicated approach to selectively erase target visual knowledge while preserving textual knowledge. Unlike previous unlearning methods that rely on output-level supervision, our approach introduces a Visual Knowledge Distillation (VKD) scheme, which leverages intermediate visual representations within the MLLM as supervision signals. This design substantially enhances both unlearning effectiveness and model utility. Moreover, since our method only fine-tunes the visual components of the MLLM, it offers significant efficiency advantages. Extensive experiments demonstrate that our approach outperforms state-of-the-art unlearning methods in terms of both effectiveness and efficiency. Moreover, we are the first to evaluate the robustness of MLLM unlearning against relearning attacks.
Expand Your SCOPE: Semantic Cognition over Potential-Based Exploration for Embodied Visual Navigation
Nov 12, 2025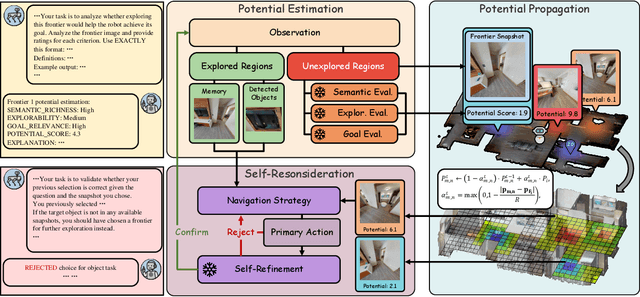
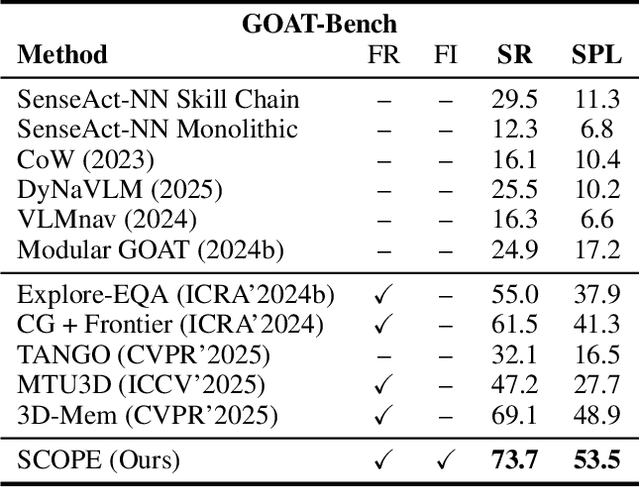
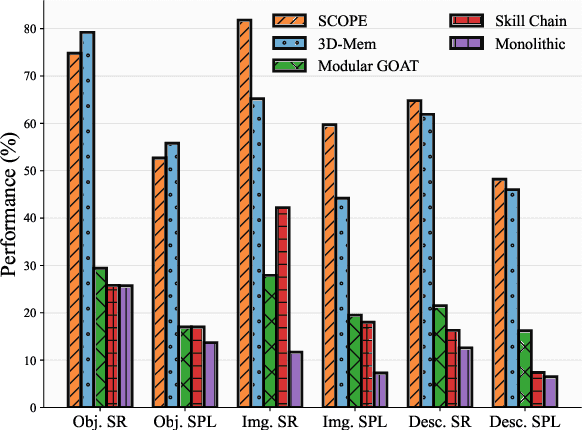
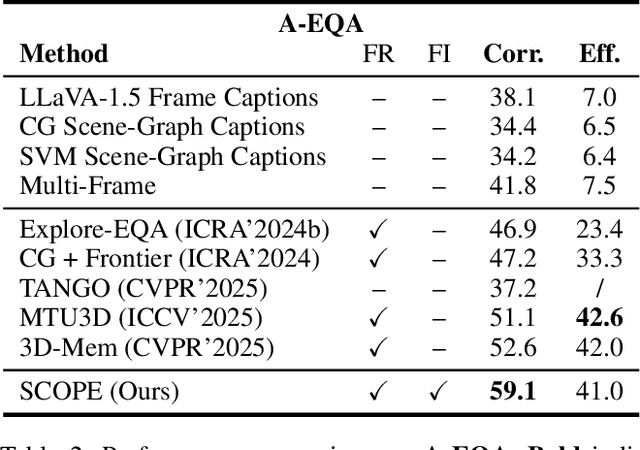
Embodied visual navigation remains a challenging task, as agents must explore unknown environments with limited knowledge. Existing zero-shot studies have shown that incorporating memory mechanisms to support goal-directed behavior can improve long-horizon planning performance. However, they overlook visual frontier boundaries, which fundamentally dictate future trajectories and observations, and fall short of inferring the relationship between partial visual observations and navigation goals. In this paper, we propose Semantic Cognition Over Potential-based Exploration (SCOPE), a zero-shot framework that explicitly leverages frontier information to drive potential-based exploration, enabling more informed and goal-relevant decisions. SCOPE estimates exploration potential with a Vision-Language Model and organizes it into a spatio-temporal potential graph, capturing boundary dynamics to support long-horizon planning. In addition, SCOPE incorporates a self-reconsideration mechanism that revisits and refines prior decisions, enhancing reliability and reducing overconfident errors. Experimental results on two diverse embodied navigation tasks show that SCOPE outperforms state-of-the-art baselines by 4.6\% in accuracy. Further analysis demonstrates that its core components lead to improved calibration, stronger generalization, and higher decision quality.
Towards Aligned Data Forgetting via Twin Machine Unlearning
Jan 15, 2025Modern privacy regulations have spurred the evolution of machine unlearning, a technique enabling a trained model to efficiently forget specific training data. In prior unlearning methods, the concept of "data forgetting" is often interpreted and implemented as achieving zero classification accuracy on such data. Nevertheless, the authentic aim of machine unlearning is to achieve alignment between the unlearned model and the gold model, i.e., encouraging them to have identical classification accuracy. On the other hand, the gold model often exhibits non-zero classification accuracy due to its generalization ability. To achieve aligned data forgetting, we propose a Twin Machine Unlearning (TMU) approach, where a twin unlearning problem is defined corresponding to the original unlearning problem. Consequently, the generalization-label predictor trained on the twin problem can be transferred to the original problem, facilitating aligned data forgetting. Comprehensive empirical experiments illustrate that our approach significantly enhances the alignment between the unlearned model and the gold model.
Efficient LLM-Jailbreaking by Introducing Visual Modality
May 30, 2024This paper focuses on jailbreaking attacks against large language models (LLMs), eliciting them to generate objectionable content in response to harmful user queries. Unlike previous LLM-jailbreaks that directly orient to LLMs, our approach begins by constructing a multimodal large language model (MLLM) through the incorporation of a visual module into the target LLM. Subsequently, we conduct an efficient MLLM-jailbreak to generate jailbreaking embeddings embJS. Finally, we convert the embJS into text space to facilitate the jailbreaking of the target LLM. Compared to direct LLM-jailbreaking, our approach is more efficient, as MLLMs are more vulnerable to jailbreaking than pure LLM. Additionally, to improve the attack success rate (ASR) of jailbreaking, we propose an image-text semantic matching scheme to identify a suitable initial input. Extensive experiments demonstrate that our approach surpasses current state-of-the-art methods in terms of both efficiency and effectiveness. Moreover, our approach exhibits superior cross-class jailbreaking capabilities.