 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Local Patterns to Global Understanding: Cross-Stock Trend Integration for Enhanced Predictive Modeling
May 22, 2025Stock price prediction is a critical area of financial forecasting, traditionally approached by training models using the historical price data of individual stocks. While these models effectively capture single-stock patterns, they fail to leverage potential correlations among stock trends, which could improve predictive performance. Current single-stock learning methods are thus limited in their ability to provide a broader understanding of price dynamics across multiple stocks. To address this, we propose a novel method that merges local patterns into a global understanding through cross-stock pattern integration. Our strategy is inspired by Federated Learning (FL), a paradigm designed for decentralized model training. FL enables collaborative learning across distributed datasets without sharing raw data, facilitating the aggregation of global insights while preserving data privacy. In our adaptation, we train models on individual stock data and iteratively merge them to create a unified global model. This global model is subsequently fine-tuned on specific stock data to retain local relevance. The proposed strategy enables parallel training of individual stock models, facilitating efficient utilization of computational resources and reducing overall training time. We conducted extensive experiments to evaluate the proposed method, demonstrating that it outperforms benchmark models and enhances the predictive capabilities of state-of-the-art approaches. Our results highlight the efficacy of Cross-Stock Trend Integration (CSTI) in advancing stock price prediction, offering a robust alternative to traditional single-stock learning methodologies.
Triplane Grasping: Efficient 6-DoF Grasping with Single RGB Images
Oct 21, 2024

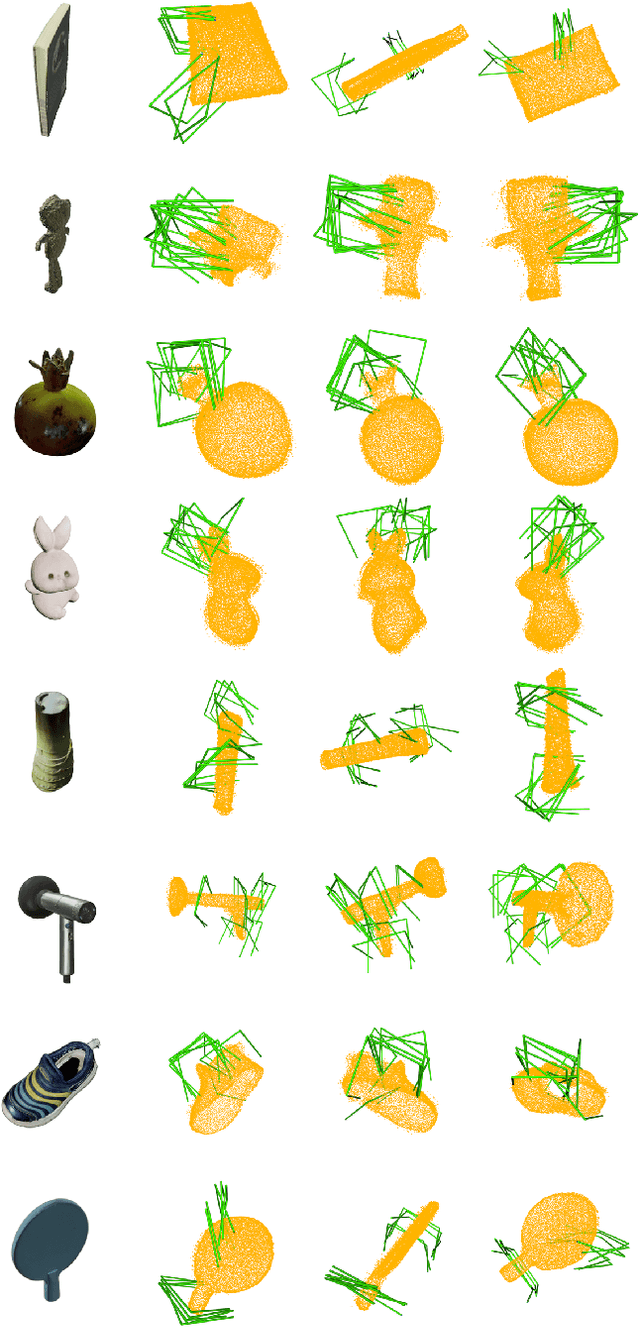
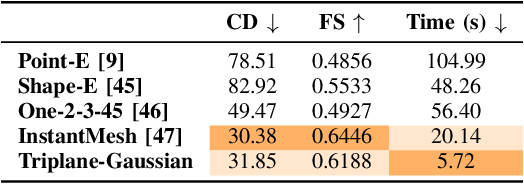
Reliable object grasping is one of the fundamental tasks in robotics. However, determining grasping pose based on single-image input has long been a challenge due to limited visual information and the complexity of real-world objects. In this paper, we propose Triplane Grasping, a fast grasping decision-making method that relies solely on a single RGB-only image as input. Triplane Grasping creates a hybrid Triplane-Gaussian 3D representation through a point decoder and a triplane decoder, which produce an efficient and high-quality reconstruction of the object to be grasped to meet real-time grasping requirements. We propose to use an end-to-end network to generate 6-DoF parallel-jaw grasp distributions directly from 3D points in the point cloud as potential grasp contacts and anchor the grasp pose in the observed data. Experiments demonstrate that our method achieves rapid modeling and grasping pose decision-making for daily objects, and exhibits a high grasping success rate in zero-shot scenarios.
Task-oriented Robotic Manipulation with Vision Language Models
Oct 21, 2024



Vision-Language Models (VLMs) play a crucial role in robotic manipulation by enabling robots to understand and interpret the visual properties of objects and their surroundings, allowing them to perform manipulation based on this multimodal understanding. However, understanding object attributes and spatial relationships is a non-trivial task but is critical in robotic manipulation tasks. In this work, we present a new dataset focused on spatial relationships and attribute assignment and a novel method to utilize VLMs to perform object manipulation with task-oriented, high-level input. In this dataset, the spatial relationships between objects are manually described as captions. Additionally, each object is labeled with multiple attributes, such as fragility, mass, material, and transparency, derived from a fine-tuned vision language model. The embedded object information from captions are automatically extracted and transformed into a data structure (in this case, tree, for demonstration purposes) that captures the spatial relationships among the objects within each image. The tree structures, along with the object attributes, are then fed into a language model to transform into a new tree structure that determines how these objects should be organized in order to accomplish a specific (high-level) task. We demonstrate that our method not only improves the comprehension of spatial relationships among objects in the visual environment but also enables robots to interact with these objects more effectively. As a result, this approach significantly enhances spatial reasoning in robotic manipulation tasks. To our knowledge, this is the first method of its kind in the literature, offering a novel solution that allows robots to more efficiently organize and utilize objects in their surroundings.
Distributed Learning for UAV Swarms
Oct 21, 2024Unmanned Aerial Vehicle (UAV) swarms are increasingly deployed in dynamic, data-rich environments for applications such as environmental monitoring and surveillance. These scenarios demand efficient data processing while maintaining privacy and security, making Federated Learning (FL) a promising solution. FL allows UAVs to collaboratively train global models without sharing raw data, but challenges arise due to the non-Independent and Identically Distributed (non-IID) nature of the data collected by UAVs. In this study, we show an integration of the state-of-the-art FL methods to UAV Swarm application and invetigate the performance of multiple aggregation methods (namely FedAvg, FedProx, FedOpt, and MOON) with a particular focus on tackling non-IID on a variety of datasets, specifically MNIST for baseline performance, CIFAR10 for natural object classification, EuroSAT for environment monitoring, and CelebA for surveillance. These algorithms were selected to cover improved techniques on both client-side updates and global aggregation. Results show that while all algorithms perform comparably on IID data, their performance deteriorates significantly under non-IID conditions. FedProx demonstrated the most stable overall performance, emphasising the importance of regularising local updates in non-IID environments to mitigate drastic deviations in local models.
Blended Latent Diffusion under Attention Control for Real-World Video Editing
Sep 05, 2024


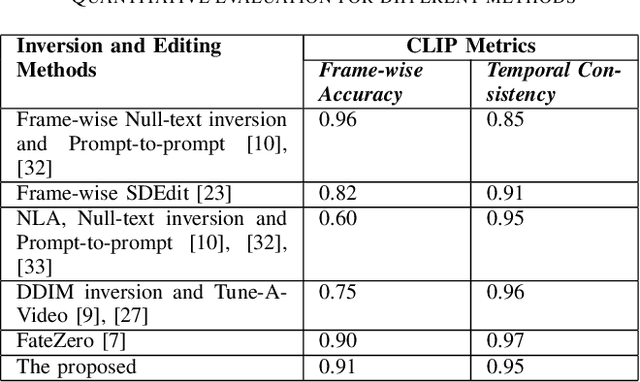
Due to lack of fully publicly available text-to-video models, current video editing methods tend to build on pre-trained text-to-image generation models, however, they still face grand challenges in dealing with the local editing of video with temporal information. First, although existing methods attempt to focus on local area editing by a pre-defined mask, the preservation of the outside-area background is non-ideal due to the spatially entire generation of each frame. In addition, specially providing a mask by user is an additional costly undertaking, so an autonomous masking strategy integrated into the editing process is desirable. Last but not least, image-level pretrained model hasn't learned temporal information across frames of a video which is vital for expressing the motion and dynamics. In this paper, we propose to adapt a image-level blended latent diffusion model to perform local video editing tasks. Specifically, we leverage DDIM inversion to acquire the latents as background latents instead of the randomly noised ones to better preserve the background information of the input video. We further introduce an autonomous mask manufacture mechanism derived from cross-attention maps in diffusion steps. Finally, we enhance the temporal consistency across video frames by transforming the self-attention blocks of U-Net into temporal-spatial blocks. Through extensive experiments, our proposed approach demonstrates effectiveness in different real-world video editing tasks.
FissionVAE: Federated Non-IID Image Generation with Latent Space and Decoder Decomposition
Aug 30, 2024



Federated learning is a machine learning paradigm that enables decentralized clients to collaboratively learn a shared model while keeping all the training data local. While considerable research has focused on federated image generation, particularly Generative Adversarial Networks, Variational Autoencoders have received less attention. In this paper, we address the challenges of non-IID (independently and identically distributed) data environments featuring multiple groups of images of different types. Specifically, heterogeneous data distributions can lead to difficulties in maintaining a consistent latent space and can also result in local generators with disparate texture features being blended during aggregation. We introduce a novel approach, FissionVAE, which decomposes the latent space and constructs decoder branches tailored to individual client groups. This method allows for customized learning that aligns with the unique data distributions of each group. Additionally, we investigate the incorporation of hierarchical VAE architectures and demonstrate the use of heterogeneous decoder architectures within our model. We also explore strategies for setting the latent prior distributions to enhance the decomposition process. To evaluate our approach, we assemble two composite datasets: the first combines MNIST and FashionMNIST; the second comprises RGB datasets of cartoon and human faces, wild animals, marine vessels, and remote sensing images of Earth. Our experiments demonstrate that FissionVAE greatly improves generation quality on these datasets compared to baseline federated VAE models.
MLMT-CNN for Object Detection and Segmentation in Multi-layer and Multi-spectral Images
Jul 19, 2024Precisely localising solar Active Regions (AR) from multi-spectral images is a challenging but important task in understanding solar activity and its influence on space weather. A main challenge comes from each modality capturing a different location of the 3D objects, as opposed to typical multi-spectral imaging scenarios where all image bands observe the same scene. Thus, we refer to this special multi-spectral scenario as multi-layer. We present a multi-task deep learning framework that exploits the dependencies between image bands to produce 3D AR localisation (segmentation and detection) where different image bands (and physical locations) have their own set of results. Furthermore, to address the difficulty of producing dense AR annotations for training supervised machine learning (ML) algorithms, we adapt a training strategy based on weak labels (i.e. bounding boxes) in a recursive manner. We compare our detection and segmentation stages against baseline approaches for solar image analysis (multi-channel coronal hole detection, SPOCA for ARs) and state-of-the-art deep learning methods (Faster RCNN, U-Net). Additionally, both detection a nd segmentation stages are quantitatively validated on artificially created data of similar spatial configurations made from annotated multi-modal magnetic resonance images. Our framework achieves an average of 0.72 IoU (segmentation) and 0.90 F1 score (detection) across all modalities, comparing to the best performing baseline methods with scores of 0.53 and 0.58, respectively, on the artificial dataset, and 0.84 F1 score in the AR detection task comparing to baseline of 0.82 F1 score. Our segmentation results are qualitatively validated by an expert on real ARs.
AttentNet: Fully Convolutional 3D Attention for Lung Nodule Detection
Jul 19, 2024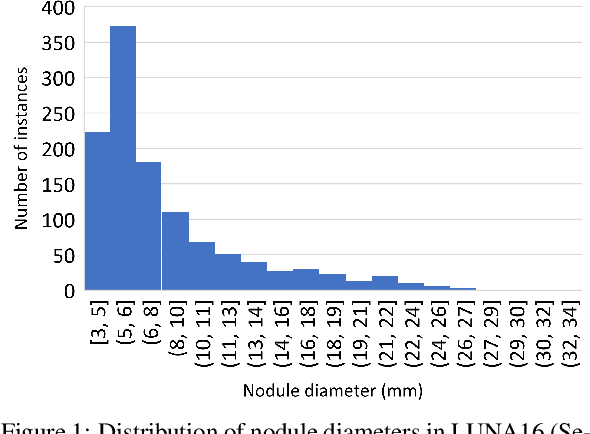
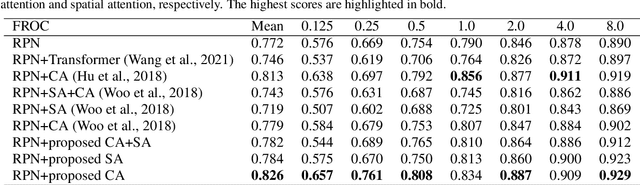
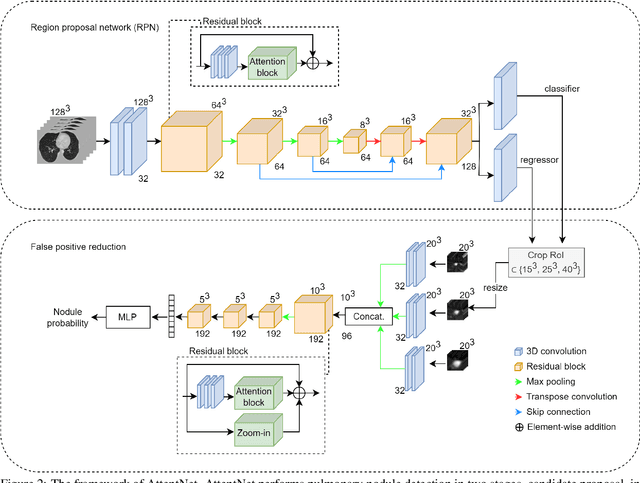

Motivated by the increasing popularity of attention mechanisms, we observe that popular convolutional (conv.) attention models like Squeeze-and-Excite (SE) and Convolutional Block Attention Module (CBAM) rely on expensive multi-layer perception (MLP) layers. These MLP layers significantly increase computational complexity, making such models less applicable to 3D image contexts, where data dimensionality and computational costs are higher. In 3D medical imaging, such as 3D pulmonary CT scans, efficient processing is crucial due to the large data volume. Traditional 2D attention generalized to 3D increases the computational load, creating demand for more efficient attention mechanisms for 3D tasks. We investigate the possibility of incorporating fully convolutional (conv.) attention in 3D context. We present two 3D fully conv. attention blocks, demonstrating their effectiveness in 3D context. Using pulmonary CT scans for 3D lung nodule detection, we present AttentNet, an automated lung nodule detection framework from CT images, performing detection as an ensemble of two stages, candidate proposal and false positive (FP) reduction. We compare the proposed 3D attention blocks to popular 2D conv. attention methods generalized to 3D modules and to self-attention units. For the FP reduction stage, we also use a joint analysis approach to aggregate spatial information from different contextual levels. We use LUNA-16 lung nodule detection dataset to demonstrate the benefits of the proposed fully conv. attention blocks compared to baseline popular lung nodule detection methods when no attention is used. Our work does not aim at achieving state-of-the-art results in the lung nodule detection task, rather to demonstrate the benefits of incorporating fully conv. attention within a 3D context.
Multi-scale gridded Gabor attention for cirrus segmentation
Jul 11, 2024In this paper, we address the challenge of segmenting global contaminants in large images. The precise delineation of such structures requires ample global context alongside understanding of textural patterns. CNNs specialise in the latter, though their ability to generate global features is limited. Attention measures long range dependencies in images, capturing global context, though at a large computational cost. We propose a gridded attention mechanism to address this limitation, greatly increasing efficiency by processing multi-scale features into smaller tiles. We also enhance the attention mechanism for increased sensitivity to texture orientation, by measuring correlations across features dependent on different orientations, in addition to channel and positional attention. We present results on a new dataset of astronomical images, where the task is segmenting large contaminating dust clouds.
Panoptic Segmentation of Galactic Structures in LSB Images
Jul 10, 2024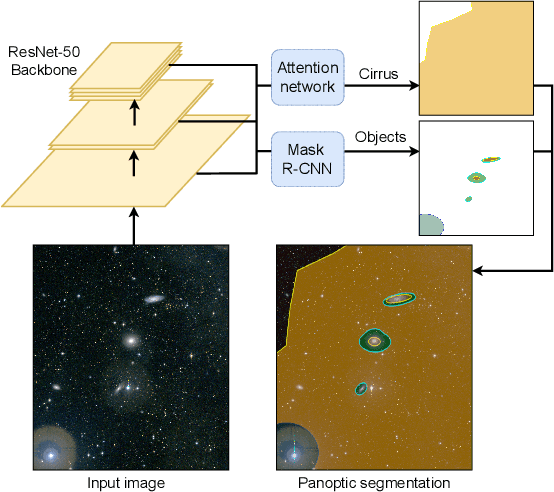


We explore the use of deep learning to localise galactic structures in low surface brightness (LSB) images. LSB imaging reveals many interesting structures, though these are frequently confused with galactic dust contamination, due to a strong local visual similarity. We propose a novel unified approach to multi-class segmentation of galactic structures and of extended amorphous image contaminants. Our panoptic segmentation model combines Mask R-CNN with a contaminant specialised network and utilises an adaptive preprocessing layer to better capture the subtle features of LSB images. Further, a human-in-the-loop training scheme is employed to augment ground truth labels. These different approaches are evaluated in turn, and together greatly improve the detection of both galactic structures and contaminants in LSB images.