 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM2StyleGS: Multi-Modality 3D Style Transfer with Gaussian Splatting
Apr 04, 2026Conventional 3D style transfer methods rely on a fixed reference image to apply artistic patterns to 3D scenes. However, in practical applications such as virtual or augmented reality, users often prefer more flexible inputs, including textual descriptions and diverse imagery. In this work, we introduce a novel real-time styling technique M2StyleGS to generate a sequence of precisely color-mapped views. It utilizes 3D Gaussian Splatting (3DGS) as a 3D presentation and multi-modality knowledge refined by CLIP as a reference style. M2StyleGS resolves the abnormal transformation issue by employing a precise feature alignment, namely subdivisive flow, it strengthens the projection of the mapped CLIP text-visual combination feature to the VGG style feature. In addition, we introduce observation loss, which assists in the stylized scene better matching the reference style during the generation, and suppression loss, which suppresses the offset of reference color information throughout the decoding process. By integrating these approaches, M2StyleGS can employ text or images as references to generate a set of style-enhanced novel views. Our experiments show that M2StyleGS achieves better visual quality and surpasses the previous work by up to 32.92% in terms of consistency.
From Local Patterns to Global Understanding: Cross-Stock Trend Integration for Enhanced Predictive Modeling
May 22, 2025Stock price prediction is a critical area of financial forecasting, traditionally approached by training models using the historical price data of individual stocks. While these models effectively capture single-stock patterns, they fail to leverage potential correlations among stock trends, which could improve predictive performance. Current single-stock learning methods are thus limited in their ability to provide a broader understanding of price dynamics across multiple stocks. To address this, we propose a novel method that merges local patterns into a global understanding through cross-stock pattern integration. Our strategy is inspired by Federated Learning (FL), a paradigm designed for decentralized model training. FL enables collaborative learning across distributed datasets without sharing raw data, facilitating the aggregation of global insights while preserving data privacy. In our adaptation, we train models on individual stock data and iteratively merge them to create a unified global model. This global model is subsequently fine-tuned on specific stock data to retain local relevance. The proposed strategy enables parallel training of individual stock models, facilitating efficient utilization of computational resources and reducing overall training time. We conducted extensive experiments to evaluate the proposed method, demonstrating that it outperforms benchmark models and enhances the predictive capabilities of state-of-the-art approaches. Our results highlight the efficacy of Cross-Stock Trend Integration (CSTI) in advancing stock price prediction, offering a robust alternative to traditional single-stock learning methodologies.
Adaptive Graph Learning from Spatial Information for Surgical Workflow Anticipation
Dec 09, 2024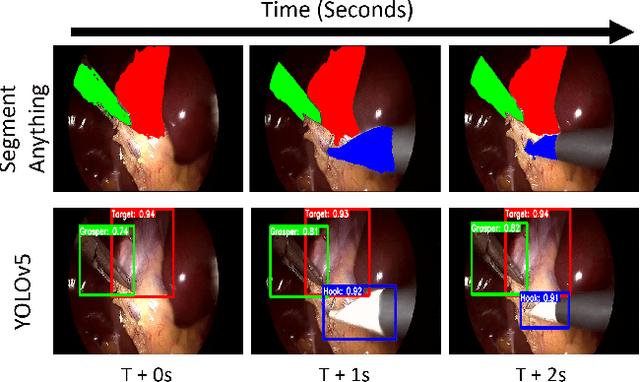
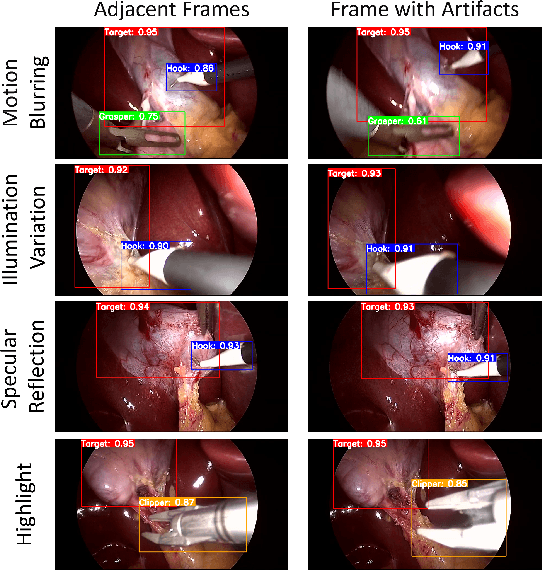
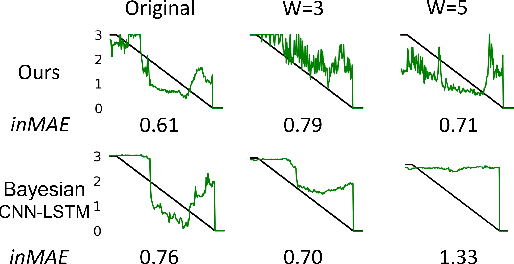
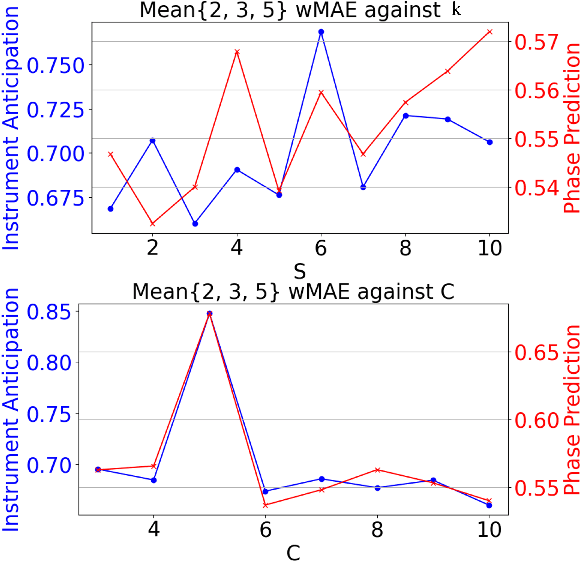
Surgical workflow anticipation is the task of predicting the timing of relevant surgical events from live video data, which is critical in Robotic-Assisted Surgery (RAS). Accurate predictions require the use of spatial information to model surgical interactions. However, current methods focus solely on surgical instruments, assume static interactions between instruments, and only anticipate surgical events within a fixed time horizon. To address these challenges, we propose an adaptive graph learning framework for surgical workflow anticipation based on a novel spatial representation, featuring three key innovations. First, we introduce a new representation of spatial information based on bounding boxes of surgical instruments and targets, including their detection confidence levels. These are trained on additional annotations we provide for two benchmark datasets. Second, we design an adaptive graph learning method to capture dynamic interactions. Third, we develop a multi-horizon objective that balances learning objectives for different time horizons, allowing for unconstrained predictions. Evaluations on two benchmarks reveal superior performance in short-to-mid-term anticipation, with an error reduction of approximately 3% for surgical phase anticipation and 9% for remaining surgical duration anticipation. These performance improvements demonstrate the effectiveness of our method and highlight its potential for enhancing preparation and coordination within the RAS team. This can improve surgical safety and the efficiency of operating room usage.
Artificial Intelligence for Geometry-Based Feature Extraction, Analysis and Synthesis in Artistic Images: A Survey
Dec 02, 2024Artificial Intelligence significantly enhances the visual art industry by analyzing, identifying and generating digitized artistic images. This review highlights the substantial benefits of integrating geometric data into AI models, addressing challenges such as high inter-class variations, domain gaps, and the separation of style from content by incorporating geometric information. Models not only improve AI-generated graphics synthesis quality, but also effectively distinguish between style and content, utilizing inherent model biases and shared data traits. We explore methods like geometric data extraction from artistic images, the impact on human perception, and its use in discriminative tasks. The review also discusses the potential for improving data quality through innovative annotation techniques and the use of geometric data to enhance model adaptability and output refinement. Overall, incorporating geometric guidance boosts model performance in classification and synthesis tasks, providing crucial insights for future AI applications in the visual arts domain.
Triplane Grasping: Efficient 6-DoF Grasping with Single RGB Images
Oct 21, 2024

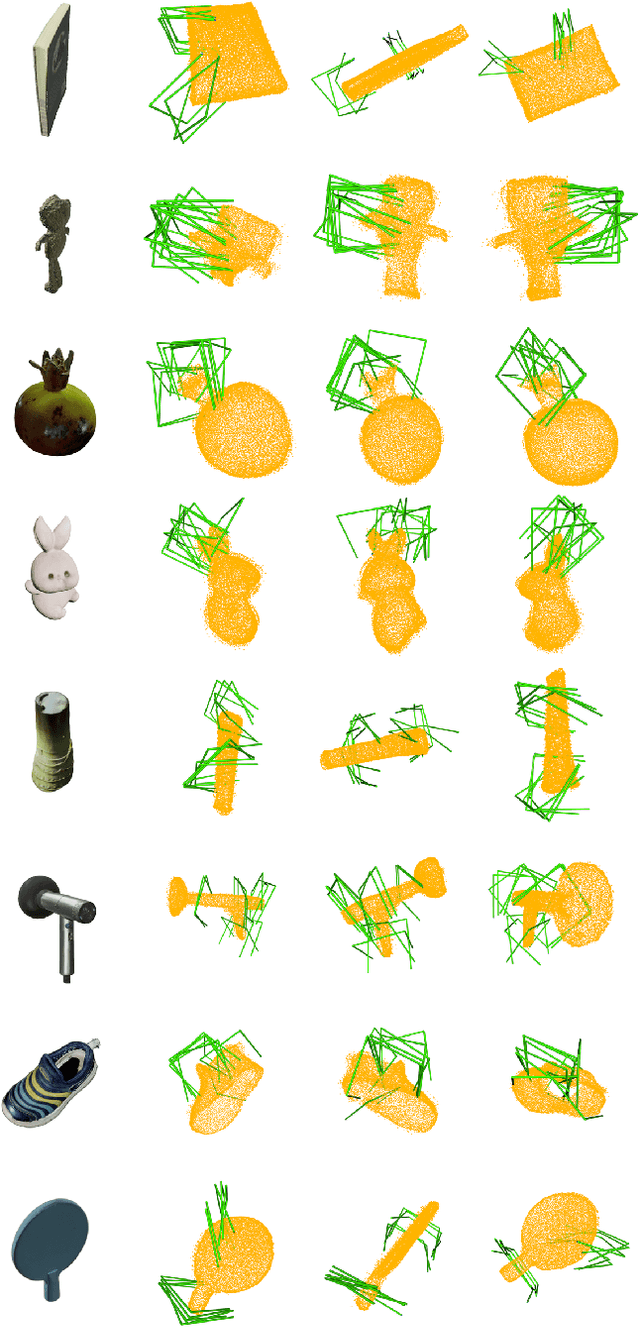
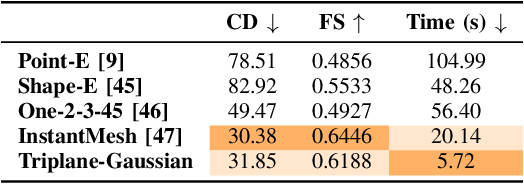
Reliable object grasping is one of the fundamental tasks in robotics. However, determining grasping pose based on single-image input has long been a challenge due to limited visual information and the complexity of real-world objects. In this paper, we propose Triplane Grasping, a fast grasping decision-making method that relies solely on a single RGB-only image as input. Triplane Grasping creates a hybrid Triplane-Gaussian 3D representation through a point decoder and a triplane decoder, which produce an efficient and high-quality reconstruction of the object to be grasped to meet real-time grasping requirements. We propose to use an end-to-end network to generate 6-DoF parallel-jaw grasp distributions directly from 3D points in the point cloud as potential grasp contacts and anchor the grasp pose in the observed data. Experiments demonstrate that our method achieves rapid modeling and grasping pose decision-making for daily objects, and exhibits a high grasping success rate in zero-shot scenarios.
Distributed Learning for UAV Swarms
Oct 21, 2024Unmanned Aerial Vehicle (UAV) swarms are increasingly deployed in dynamic, data-rich environments for applications such as environmental monitoring and surveillance. These scenarios demand efficient data processing while maintaining privacy and security, making Federated Learning (FL) a promising solution. FL allows UAVs to collaboratively train global models without sharing raw data, but challenges arise due to the non-Independent and Identically Distributed (non-IID) nature of the data collected by UAVs. In this study, we show an integration of the state-of-the-art FL methods to UAV Swarm application and invetigate the performance of multiple aggregation methods (namely FedAvg, FedProx, FedOpt, and MOON) with a particular focus on tackling non-IID on a variety of datasets, specifically MNIST for baseline performance, CIFAR10 for natural object classification, EuroSAT for environment monitoring, and CelebA for surveillance. These algorithms were selected to cover improved techniques on both client-side updates and global aggregation. Results show that while all algorithms perform comparably on IID data, their performance deteriorates significantly under non-IID conditions. FedProx demonstrated the most stable overall performance, emphasising the importance of regularising local updates in non-IID environments to mitigate drastic deviations in local models.
Task-oriented Robotic Manipulation with Vision Language Models
Oct 21, 2024



Vision-Language Models (VLMs) play a crucial role in robotic manipulation by enabling robots to understand and interpret the visual properties of objects and their surroundings, allowing them to perform manipulation based on this multimodal understanding. However, understanding object attributes and spatial relationships is a non-trivial task but is critical in robotic manipulation tasks. In this work, we present a new dataset focused on spatial relationships and attribute assignment and a novel method to utilize VLMs to perform object manipulation with task-oriented, high-level input. In this dataset, the spatial relationships between objects are manually described as captions. Additionally, each object is labeled with multiple attributes, such as fragility, mass, material, and transparency, derived from a fine-tuned vision language model. The embedded object information from captions are automatically extracted and transformed into a data structure (in this case, tree, for demonstration purposes) that captures the spatial relationships among the objects within each image. The tree structures, along with the object attributes, are then fed into a language model to transform into a new tree structure that determines how these objects should be organized in order to accomplish a specific (high-level) task. We demonstrate that our method not only improves the comprehension of spatial relationships among objects in the visual environment but also enables robots to interact with these objects more effectively. As a result, this approach significantly enhances spatial reasoning in robotic manipulation tasks. To our knowledge, this is the first method of its kind in the literature, offering a novel solution that allows robots to more efficiently organize and utilize objects in their surroundings.
FissionVAE: Federated Non-IID Image Generation with Latent Space and Decoder Decomposition
Aug 30, 2024



Federated learning is a machine learning paradigm that enables decentralized clients to collaboratively learn a shared model while keeping all the training data local. While considerable research has focused on federated image generation, particularly Generative Adversarial Networks, Variational Autoencoders have received less attention. In this paper, we address the challenges of non-IID (independently and identically distributed) data environments featuring multiple groups of images of different types. Specifically, heterogeneous data distributions can lead to difficulties in maintaining a consistent latent space and can also result in local generators with disparate texture features being blended during aggregation. We introduce a novel approach, FissionVAE, which decomposes the latent space and constructs decoder branches tailored to individual client groups. This method allows for customized learning that aligns with the unique data distributions of each group. Additionally, we investigate the incorporation of hierarchical VAE architectures and demonstrate the use of heterogeneous decoder architectures within our model. We also explore strategies for setting the latent prior distributions to enhance the decomposition process. To evaluate our approach, we assemble two composite datasets: the first combines MNIST and FashionMNIST; the second comprises RGB datasets of cartoon and human faces, wild animals, marine vessels, and remote sensing images of Earth. Our experiments demonstrate that FissionVAE greatly improves generation quality on these datasets compared to baseline federated VAE models.
ST-SACLF: Style Transfer Informed Self-Attention Classifier for Bias-Aware Painting Classification
Aug 03, 2024



Painting classification plays a vital role in organizing, finding, and suggesting artwork for digital and classic art galleries. Existing methods struggle with adapting knowledge from the real world to artistic images during training, leading to poor performance when dealing with different datasets. Our innovation lies in addressing these challenges through a two-step process. First, we generate more data using Style Transfer with Adaptive Instance Normalization (AdaIN), bridging the gap between diverse styles. Then, our classifier gains a boost with feature-map adaptive spatial attention modules, improving its understanding of artistic details. Moreover, we tackle the problem of imbalanced class representation by dynamically adjusting augmented samples. Through a dual-stage process involving careful hyperparameter search and model fine-tuning, we achieve an impressive 87.24\% accuracy using the ResNet-50 backbone over 40 training epochs. Our study explores quantitative analyses that compare different pretrained backbones, investigates model optimization through ablation studies, and examines how varying augmentation levels affect model performance. Complementing this, our qualitative experiments offer valuable insights into the model's decision-making process using spatial attention and its ability to differentiate between easy and challenging samples based on confidence ranking.
An Element-Wise Weights Aggregation Method for Federated Learning
Apr 24, 2024Federated learning (FL) is a powerful Machine Learning (ML) paradigm that enables distributed clients to collaboratively learn a shared global model while keeping the data on the original device, thereby preserving privacy. A central challenge in FL is the effective aggregation of local model weights from disparate and potentially unbalanced participating clients. Existing methods often treat each client indiscriminately, applying a single proportion to the entire local model. However, it is empirically advantageous for each weight to be assigned a specific proportion. This paper introduces an innovative Element-Wise Weights Aggregation Method for Federated Learning (EWWA-FL) aimed at optimizing learning performance and accelerating convergence speed. Unlike traditional FL approaches, EWWA-FL aggregates local weights to the global model at the level of individual elements, thereby allowing each participating client to make element-wise contributions to the learning process. By taking into account the unique dataset characteristics of each client, EWWA-FL enhances the robustness of the global model to different datasets while also achieving rapid convergence. The method is flexible enough to employ various weighting strategies. Through comprehensive experiments, we demonstrate the advanced capabilities of EWWA-FL, showing significant improvements in both accuracy and convergence speed across a range of backbones and benchmarks.