 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeROOM: A Physics-Based Continuum Robot Simulator for Photorealistic Medical Datasets Generation
Sep 16, 2025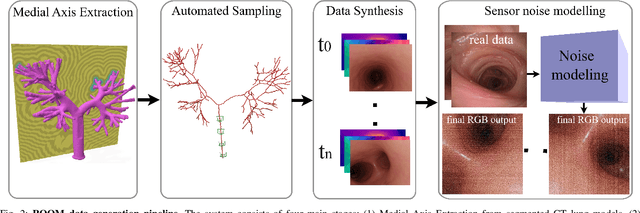



Continuum robots are advancing bronchoscopy procedures by accessing complex lung airways and enabling targeted interventions. However, their development is limited by the lack of realistic training and test environments: Real data is difficult to collect due to ethical constraints and patient safety concerns, and developing autonomy algorithms requires realistic imaging and physical feedback. We present ROOM (Realistic Optical Observation in Medicine), a comprehensive simulation framework designed for generating photorealistic bronchoscopy training data. By leveraging patient CT scans, our pipeline renders multi-modal sensor data including RGB images with realistic noise and light specularities, metric depth maps, surface normals, optical flow and point clouds at medically relevant scales. We validate the data generated by ROOM in two canonical tasks for medical robotics -- multi-view pose estimation and monocular depth estimation, demonstrating diverse challenges that state-of-the-art methods must overcome to transfer to these medical settings. Furthermore, we show that the data produced by ROOM can be used to fine-tune existing depth estimation models to overcome these challenges, also enabling other downstream applications such as navigation. We expect that ROOM will enable large-scale data generation across diverse patient anatomies and procedural scenarios that are challenging to capture in clinical settings. Code and data: https://github.com/iamsalvatore/room.
Using Fixed and Mobile Eye Tracking to Understand How Visitors View Art in a Museum: A Study at the Bowes Museum, County Durham, UK
Apr 28, 2025The following paper describes a collaborative project involving researchers at Durham University, and professionals at the Bowes Museum, Barnard Castle, County Durham, UK, during which we used fixed and mobile eye tracking to understand how visitors view art. Our study took place during summer 2024 and builds on work presented at DH2017 (Bailey-Ross et al., 2017). Our interdisciplinary team included researchers from digital humanities, psychology, art history and computer science, working in collaboration with professionals from the museum. We used fixed and mobile eye tracking to understand how museum visitors view art in a physical gallery setting. This research will enable us to make recommendations about how the Museum's collections could be more effectively displayed, encouraging visitors to engage with them more fully.
Adaptive Graph Learning from Spatial Information for Surgical Workflow Anticipation
Dec 09, 2024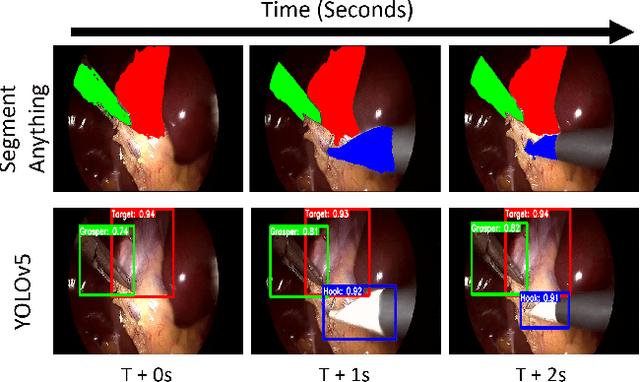
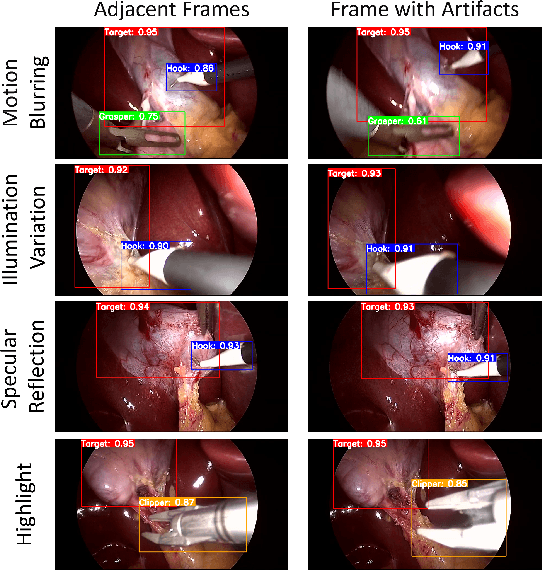
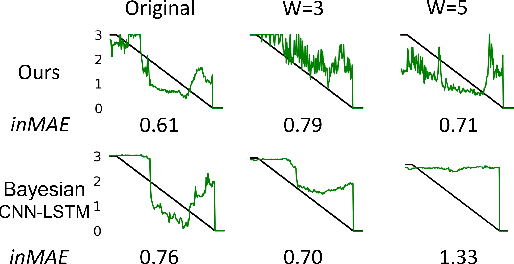
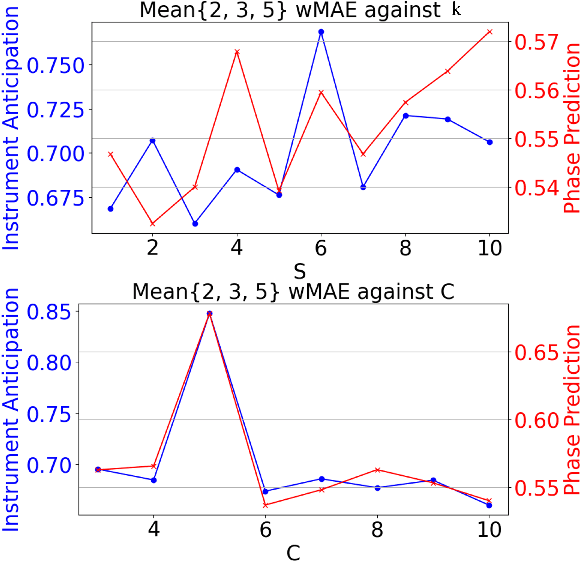
Surgical workflow anticipation is the task of predicting the timing of relevant surgical events from live video data, which is critical in Robotic-Assisted Surgery (RAS). Accurate predictions require the use of spatial information to model surgical interactions. However, current methods focus solely on surgical instruments, assume static interactions between instruments, and only anticipate surgical events within a fixed time horizon. To address these challenges, we propose an adaptive graph learning framework for surgical workflow anticipation based on a novel spatial representation, featuring three key innovations. First, we introduce a new representation of spatial information based on bounding boxes of surgical instruments and targets, including their detection confidence levels. These are trained on additional annotations we provide for two benchmark datasets. Second, we design an adaptive graph learning method to capture dynamic interactions. Third, we develop a multi-horizon objective that balances learning objectives for different time horizons, allowing for unconstrained predictions. Evaluations on two benchmarks reveal superior performance in short-to-mid-term anticipation, with an error reduction of approximately 3% for surgical phase anticipation and 9% for remaining surgical duration anticipation. These performance improvements demonstrate the effectiveness of our method and highlight its potential for enhancing preparation and coordination within the RAS team. This can improve surgical safety and the efficiency of operating room usage.
Depth-Aware Endoscopic Video Inpainting
Jul 02, 2024
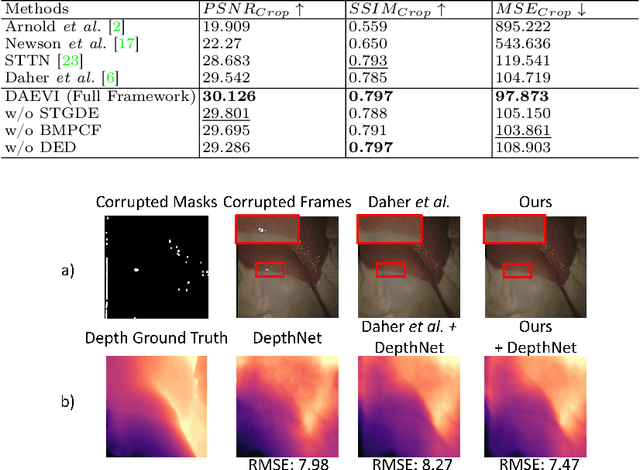

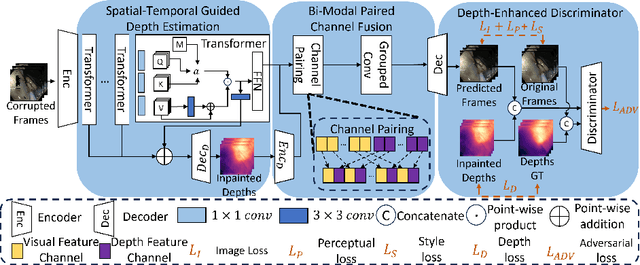
Video inpainting fills in corrupted video content with plausible replacements. While recent advances in endoscopic video inpainting have shown potential for enhancing the quality of endoscopic videos, they mainly repair 2D visual information without effectively preserving crucial 3D spatial details for clinical reference. Depth-aware inpainting methods attempt to preserve these details by incorporating depth information. Still, in endoscopic contexts, they face challenges including reliance on pre-acquired depth maps, less effective fusion designs, and ignorance of the fidelity of 3D spatial details. To address them, we introduce a novel Depth-aware Endoscopic Video Inpainting (DAEVI) framework. It features a Spatial-Temporal Guided Depth Estimation module for direct depth estimation from visual features, a Bi-Modal Paired Channel Fusion module for effective channel-by-channel fusion of visual and depth information, and a Depth Enhanced Discriminator to assess the fidelity of the RGB-D sequence comprised of the inpainted frames and estimated depth images. Experimental evaluations on established benchmarks demonstrate our framework's superiority, achieving a 2% improvement in PSNR and a 6% reduction in MSE compared to state-of-the-art methods. Qualitative analyses further validate its enhanced ability to inpaint fine details, highlighting the benefits of integrating depth information into endoscopic inpainting.