 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIR-SIM: A Lightweight Skill-Native Simulator for Navigation, Learning, and Benchmarking
Jun 07, 2026Simulation plays a key role in automated robotics research supported by large language models (LLMs). However, existing simulators often require custom code or complex interfaces, creating a barrier to rapid prototyping and automated algorithm development. To this end, we propose the Intelligent Robot Simulator (IR-SIM), a lightweight skill-native navigation simulator designed for rapid scenario construction, benchmarking, and robot learning. In IR-SIM, scenarios are entirely defined by YAML configuration files that specify mobile robot kinematics, geometric collision checking, LiDAR sensing, visualization, and behavior modules. This design makes robotic simulation fully describable and reproducible, allowing scenarios to be generated and modified from text prompts through the proposed IR-SIM agent skills. The resulting scenarios can be used for automated benchmarking of navigation algorithms and for automated generation of training data for learning methods. Furthermore, IR-SIM provides bridges to high fidelity simulators and real world deployment, allowing users to validate their algorithms in more realistic settings after prototyping without extra coding. The experiments showcase the convenience and versatility of IR-SIM in multiple tasks: constructing navigation scenarios from natural language, training a collision avoidance policy, benchmarking social navigation policies, and bridging to high fidelity simulators and real world deployment. The project website is available at https://github.com/hanruihua/ir-sim.
Global Convergence of Wasserstein Policy Gradient for Entropy-Regularized Reinforcement Learning
May 26, 2026Wasserstein policy gradient (WPG) is a policy optimization method for reinforcement learning (RL) that exploits the optimal-transport geometry of action distributions. For the entropy-regularized RL objective, WPG evolves each state-conditional policy by transporting it along the action gradient of the soft Q-function together with a Langevin-type diffusion. Despite its appeal for continuous-control problems, its global convergence properties remain poorly understood. Standard Langevin analyses do not directly apply, because the RL objective depends on the policy through the Bellman recursion rather than through a static convex functional, and the Langevin drift is determined by the soft Q-function, whose regularity must be controlled along the policy iterates. In this paper, we develop a global convergence theory for WPG by exploiting the Bellman structure of entropy-regularized RL. We show that the role usually played by convexity can be replaced by a Bellman-based argument: the soft Bellman residual admits a statewise KL representation with respect to a Gibbs policy; Bellman contraction relates this residual to the global optimality gap; and a Bellman resolvent identity connects value improvement to relative Fisher information. Combined with a uniform log-Sobolev inequality (LSI) for the evolving Gibbs family, these ingredients yield a distributional Polyak--Łojasiewicz condition. We further establish the regularity and uniform bounds needed to control the discretization error, thereby obtaining geometric contraction up to a discretization bias. Conceptually, our analysis shows that although entropy-regularized RL is not convex in the usual flat sense, the Bellman recursion induces a favorable Polyak--Lojasiewicz-type (PL) geometry that supports global convergence of WPG.
C-MORAL: Controllable Multi-Objective Molecular Optimization with Reinforcement Alignment for LLMs
Apr 24, 2026Large language models (LLMs) show promise for molecular optimization, but aligning them with selective and competing drug-design constraints remains challenging. We propose C-Moral, a reinforcement learning post-training framework for controllable multi-objective molecular optimization. C-Moral combines group-based relative optimization, property score alignment for heterogeneous objectives, and continuous non-linear reward aggregation to improve stability across competing properties. Experiments on the C-MuMOInstruct benchmark show that C-Moral consistently outperforms state-of-the-art models across both in-domain and out-of-domain settings, achieving the best Success Optimized Rate (SOR) of 48.9% on IND tasks and 39.5% on OOD tasks, while largely preserving scaffold similarity. These results suggest that RL post-training is an effective way to align molecular language models with continuous molecular design objectives. Our code and models are publicly available at https://github.com/Rwigie/C-MORAL.
Wasserstein Proximal Policy Gradient
Mar 03, 2026We study policy gradient methods for continuous-action, entropy-regularized reinforcement learning through the lens of Wasserstein geometry. Starting from a Wasserstein proximal update, we derive Wasserstein Proximal Policy Gradient (WPPG) via an operator-splitting scheme that alternates an optimal transport update with a heat step implemented by Gaussian convolution. This formulation avoids evaluating the policy's log density or its gradient, making the method directly applicable to expressive implicit stochastic policies specified as pushforward maps. We establish a global linear convergence rate for WPPG, covering both exact policy evaluation and actor-critic implementations with controlled approximation error. Empirically, WPPG is simple to implement and attains competitive performance on standard continuous-control benchmarks.
LLM-Driven Scenario-Aware Planning for Autonomous Driving
Jan 29, 2026Hybrid planner switching framework (HPSF) for autonomous driving needs to reconcile high-speed driving efficiency with safe maneuvering in dense traffic. Existing HPSF methods often fail to make reliable mode transitions or sustain efficient driving in congested environments, owing to heuristic scene recognition and low-frequency control updates. To address the limitation, this paper proposes LAP, a large language model (LLM) driven, adaptive planning method, which switches between high-speed driving in low-complexity scenes and precise driving in high-complexity scenes, enabling high qualities of trajectory generation through confined gaps. This is achieved by leveraging LLM for scene understanding and integrating its inference into the joint optimization of mode configuration and motion planning. The joint optimization is solved using tree-search model predictive control and alternating minimization. We implement LAP by Python in Robot Operating System (ROS). High-fidelity simulation results show that the proposed LAP outperforms other benchmarks in terms of both driving time and success rate.
DeepHalo: A Neural Choice Model with Controllable Context Effects
Jan 08, 2026Modeling human decision-making is central to applications such as recommendation, preference learning, and human-AI alignment. While many classic models assume context-independent choice behavior, a large body of behavioral research shows that preferences are often influenced by the composition of the choice set itself -- a phenomenon known as the context effect or Halo effect. These effects can manifest as pairwise (first-order) or even higher-order interactions among the available alternatives. Recent models that attempt to capture such effects either focus on the featureless setting or, in the feature-based setting, rely on restrictive interaction structures or entangle interactions across all orders, which limits interpretability. In this work, we propose DeepHalo, a neural modeling framework that incorporates features while enabling explicit control over interaction order and principled interpretation of context effects. Our model enables systematic identification of interaction effects by order and serves as a universal approximator of context-dependent choice functions when specialized to a featureless setting. Experiments on synthetic and real-world datasets demonstrate strong predictive performance while providing greater transparency into the drivers of choice.
Sigma-MoE-Tiny Technical Report
Dec 19, 2025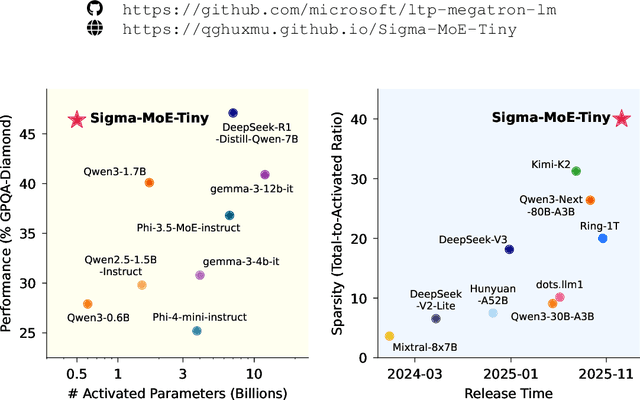

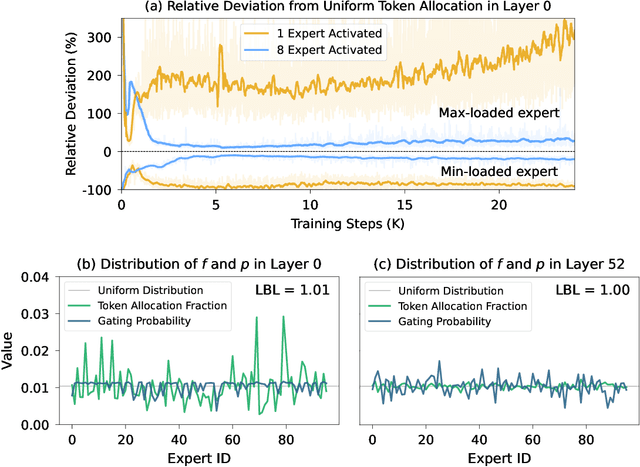
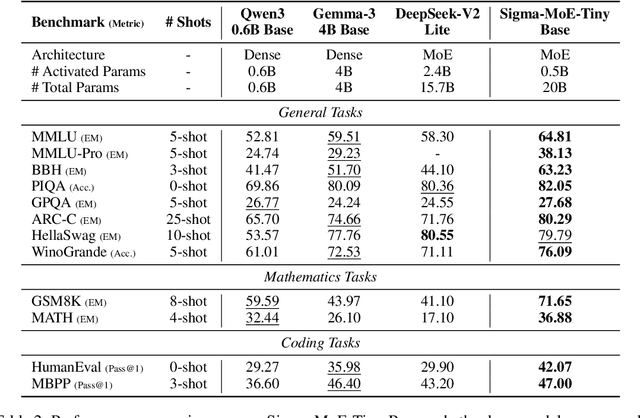
Mixture-of-Experts (MoE) has emerged as a promising paradigm for foundation models due to its efficient and powerful scalability. In this work, we present Sigma-MoE-Tiny, an MoE language model that achieves the highest sparsity compared to existing open-source models. Sigma-MoE-Tiny employs fine-grained expert segmentation with up to 96 experts per layer, while activating only one expert for each token, resulting in 20B total parameters with just 0.5B activated. The major challenge introduced by such extreme sparsity lies in expert load balancing. We find that the widely-used load balancing loss tends to become ineffective in the lower layers under this setting. To address this issue, we propose a progressive sparsification schedule aiming to balance expert utilization and training stability. Sigma-MoE-Tiny is pre-trained on a diverse and high-quality corpus, followed by post-training to further unlock its capabilities. The entire training process remains remarkably stable, with no occurrence of irrecoverable loss spikes. Comprehensive evaluations reveal that, despite activating only 0.5B parameters, Sigma-MoE-Tiny achieves top-tier performance among counterparts of comparable or significantly larger scale. In addition, we provide an in-depth discussion of load balancing in highly sparse MoE models, offering insights for advancing sparsity in future MoE architectures. Project page: https://qghuxmu.github.io/Sigma-MoE-Tiny Code: https://github.com/microsoft/ltp-megatron-lm
SIGMA: An AI-Empowered Training Stack on Early-Life Hardware
Dec 15, 2025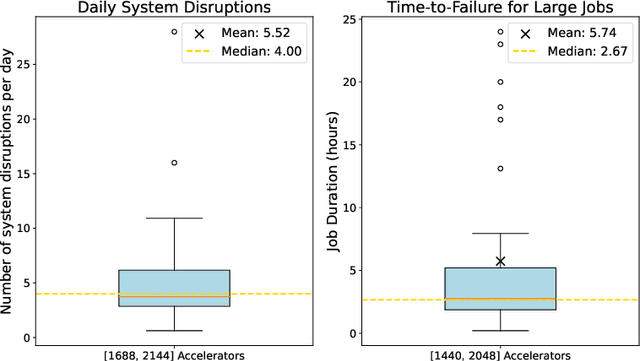

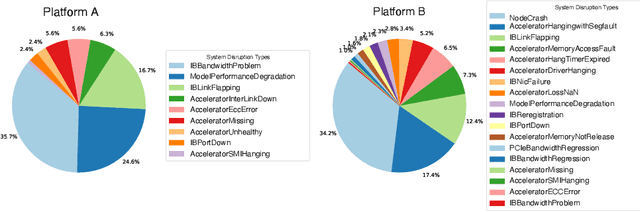

An increasing variety of AI accelerators is being considered for large-scale training. However, enabling large-scale training on early-life AI accelerators faces three core challenges: frequent system disruptions and undefined failure modes that undermine reliability; numerical errors and training instabilities that threaten correctness and convergence; and the complexity of parallelism optimization combined with unpredictable local noise that degrades efficiency. To address these challenges, SIGMA is an open-source training stack designed to improve the reliability, stability, and efficiency of large-scale distributed training on early-life AI hardware. The core of this initiative is the LUCIA TRAINING PLATFORM (LTP), the system optimized for clusters with early-life AI accelerators. Since its launch in March 2025, LTP has significantly enhanced training reliability and operational productivity. Over the past five months, it has achieved an impressive 94.45% effective cluster accelerator utilization, while also substantially reducing node recycling and job-recovery times. Building on the foundation of LTP, the LUCIA TRAINING FRAMEWORK (LTF) successfully trained SIGMA-MOE, a 200B MoE model, using 2,048 AI accelerators. This effort delivered remarkable stability and efficiency outcomes, achieving 21.08% MFU, state-of-the-art downstream accuracy, and encountering only one stability incident over a 75-day period. Together, these advances establish SIGMA, which not only tackles the critical challenges of large-scale training but also establishes a new benchmark for AI infrastructure and platform innovation, offering a robust, cost-effective alternative to prevailing established accelerator stacks and significantly advancing AI capabilities and scalability. The source code of SIGMA is available at https://github.com/microsoft/LuciaTrainingPlatform.
Data-driven modeling of fluid flow around rotating structures with graph neural networks
Mar 28, 2025Graph neural networks, recently introduced into the field of fluid flow surrogate modeling, have been successfully applied to model the temporal evolution of various fluid flow systems. Existing applications, however, are mostly restricted to cases where the domain is time-invariant. The present work extends the application of graph neural network-based modeling to fluid flow around structures rotating with respect to a certain axis. Specifically, we propose to apply a graph neural network-based surrogate modeling for fluid flow with the mesh corotating with the structure. Unlike conventional data-driven approaches that rely on structured Cartesian meshes, our framework operates on unstructured co-rotating meshes, enforcing rotation equivariance of the learned model by leveraging co-rotating polar (2D) and cylindrical (3D) coordinate systems. To model the pressure for systems without Dirichlet pressure boundaries, we propose a novel local directed pressure difference formulation that is invariant to the reference pressure point and value. For flow systems with large mesh sizes, we introduce a scheme to train the network in single or distributed graphics processing units by accumulating the backpropagated gradients from partitions of the mesh. The effectiveness of our proposed framework is examined on two test cases: (i) fluid flow in a 2D rotating mixer, and (ii) the flow past a 3D rotating cube. Our results show that the model achieves stable and accurate rollouts for over 2000 time steps in periodic regimes while capturing accurate short-term dynamics in chaotic flow regimes. In addition, the drag and lift force predictions closely match the CFD calculations, highlighting the potential of the framework for modeling both periodic and chaotic fluid flow around rotating structures.
FetalFlex: Anatomy-Guided Diffusion Model for Flexible Control on Fetal Ultrasound Image Synthesis
Mar 19, 2025Fetal ultrasound (US) examinations require the acquisition of multiple planes, each providing unique diagnostic information to evaluate fetal development and screening for congenital anomalies. However, obtaining a comprehensive, multi-plane annotated fetal US dataset remains challenging, particularly for rare or complex anomalies owing to their low incidence and numerous subtypes. This poses difficulties in training novice radiologists and developing robust AI models, especially for detecting abnormal fetuses. In this study, we introduce a Flexible Fetal US image generation framework (FetalFlex) to address these challenges, which leverages anatomical structures and multimodal information to enable controllable synthesis of fetal US images across diverse planes. Specifically, FetalFlex incorporates a pre-alignment module to enhance controllability and introduces a repaint strategy to ensure consistent texture and appearance. Moreover, a two-stage adaptive sampling strategy is developed to progressively refine image quality from coarse to fine levels. We believe that FetalFlex is the first method capable of generating both in-distribution normal and out-of-distribution abnormal fetal US images, without requiring any abnormal data. Experiments on multi-center datasets demonstrate that FetalFlex achieved state-of-the-art performance across multiple image quality metrics. A reader study further confirms the close alignment of the generated results with expert visual assessments. Furthermore, synthetic images by FetalFlex significantly improve the performance of six typical deep models in downstream classification and anomaly detection tasks. Lastly, FetalFlex's anatomy-level controllable generation offers a unique advantage for anomaly simulation and creating paired or counterfactual data at the pixel level. The demo is available at: https://dyf1023.github.io/FetalFlex/.