 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelating-Up: Advancing Graph Neural Networks through Inter-Graph Relationships
May 07, 2024



Graph Neural Networks (GNNs) have excelled in learning from graph-structured data, especially in understanding the relationships within a single graph, i.e., intra-graph relationships. Despite their successes, GNNs are limited by neglecting the context of relationships across graphs, i.e., inter-graph relationships. Recognizing the potential to extend this capability, we introduce Relating-Up, a plug-and-play module that enhances GNNs by exploiting inter-graph relationships. This module incorporates a relation-aware encoder and a feedback training strategy. The former enables GNNs to capture relationships across graphs, enriching relation-aware graph representation through collective context. The latter utilizes a feedback loop mechanism for the recursively refinement of these representations, leveraging insights from refining inter-graph dynamics to conduct feedback loop. The synergy between these two innovations results in a robust and versatile module. Relating-Up enhances the expressiveness of GNNs, enabling them to encapsulate a wider spectrum of graph relationships with greater precision. Our evaluations across 16 benchmark datasets demonstrate that integrating Relating-Up into GNN architectures substantially improves performance, positioning Relating-Up as a formidable choice for a broad spectrum of graph representation learning tasks.
Interaction Pattern Disentangling for Multi-Agent Reinforcement Learning
Jul 08, 2022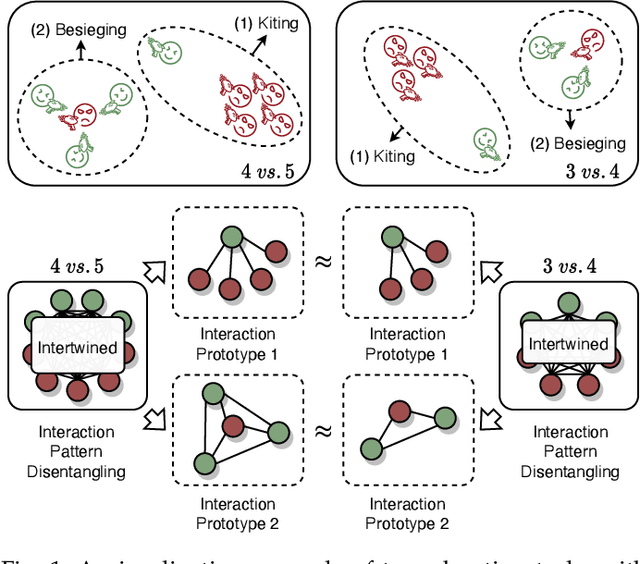

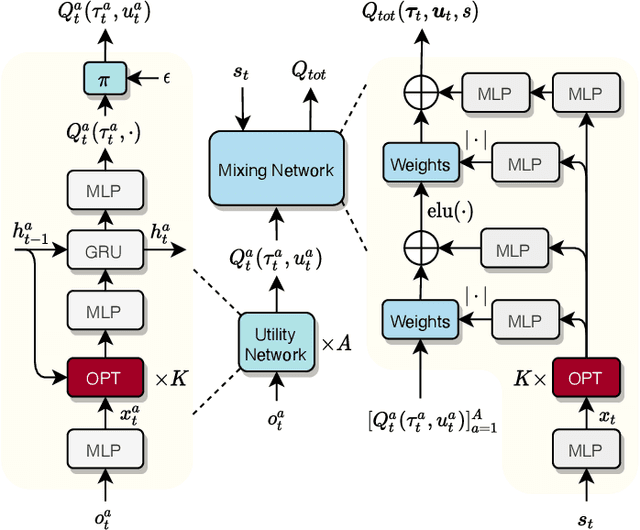
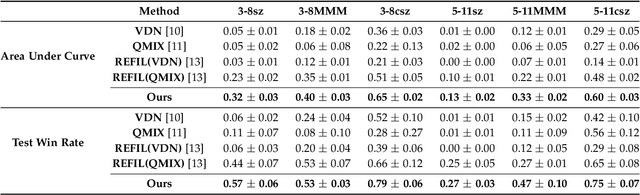
Deep cooperative multi-agent reinforcement learning has demonstrated its remarkable success over a wide spectrum of complex control tasks. However, recent advances in multi-agent learning mainly focus on value decomposition while leaving entity interactions still intertwined, which easily leads to over-fitting on noisy interactions between entities. In this work, we introduce a novel interactiOn Pattern disenTangling (OPT) method, to disentangle not only the joint value function into agent-wise value functions for decentralized execution, but also the entity interactions into interaction prototypes, each of which represents an underlying interaction pattern within a sub-group of the entities. OPT facilitates filtering the noisy interactions between irrelevant entities and thus significantly improves generalizability as well as interpretability. Specifically, OPT introduces a sparse disagreement mechanism to encourage sparsity and diversity among discovered interaction prototypes. Then the model selectively restructures these prototypes into a compact interaction pattern by an aggregator with learnable weights. To alleviate the training instability issue caused by partial observability, we propose to maximize the mutual information between the aggregation weights and the history behaviors of each agent. Experiments on both single-task and multi-task benchmarks demonstrate that the proposed method yields results superior to the state-of-the-art counterparts. Our code will be made publicly available.
Ask-AC: An Initiative Advisor-in-the-Loop Actor-Critic Framework
Jul 05, 2022



Despite the promising results achieved, state-of-the-art interactive reinforcement learning schemes rely on passively receiving supervision signals from advisor experts, in the form of either continuous monitoring or pre-defined rules, which inevitably result in a cumbersome and expensive learning process. In this paper, we introduce a novel initiative advisor-in-the-loop actor-critic framework, termed as Ask-AC, that replaces the unilateral advisor-guidance mechanism with a bidirectional learner-initiative one, and thereby enables a customized and efficacious message exchange between learner and advisor. At the heart of Ask-AC are two complementary components, namely action requester and adaptive state selector, that can be readily incorporated into various discrete actor-critic architectures. The former component allows the agent to initiatively seek advisor intervention in the presence of uncertain states, while the latter identifies the unstable states potentially missed by the former especially when environment changes, and then learns to promote the ask action on such states. Experimental results on both stationary and non-stationary environments and across different actor-critic backbones demonstrate that the proposed framework significantly improves the learning efficiency of the agent, and achieves the performances on par with those obtained by continuous advisor monitoring.
Distribution-Aware Graph Representation Learning for Transient Stability Assessment of Power System
May 12, 2022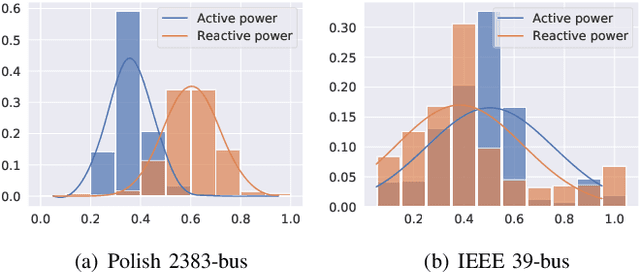

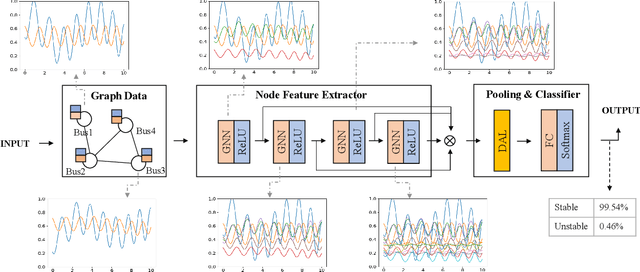
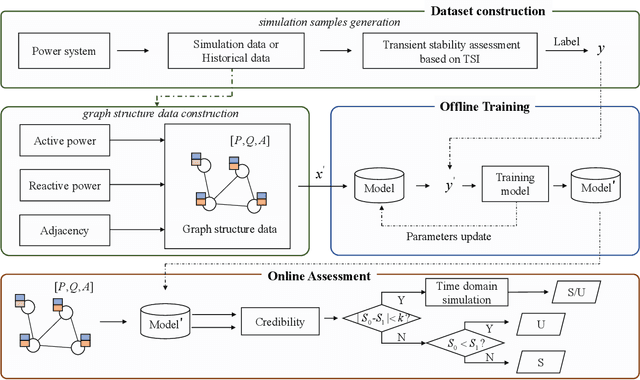
The real-time transient stability assessment (TSA) plays a critical role in the secure operation of the power system. Although the classic numerical integration method, \textit{i.e.} time-domain simulation (TDS), has been widely used in industry practice, it is inevitably trapped in a high computational complexity due to the high latitude sophistication of the power system. In this work, a data-driven power system estimation method is proposed to quickly predict the stability of the power system before TDS reaches the end of simulating time windows, which can reduce the average simulation time of stability assessment without loss of accuracy. As the topology of the power system is in the form of graph structure, graph neural network based representation learning is naturally suitable for learning the status of the power system. Motivated by observing the distribution information of crucial active power and reactive power on the power system's bus nodes, we thus propose a distribution-aware learning~(DAL) module to explore an informative graph representation vector for describing the status of a power system. Then, TSA is re-defined as a binary classification task, and the stability of the system is determined directly from the resulting graph representation without numerical integration. Finally, we apply our method to the online TSA task. The case studies on the IEEE 39-bus system and Polish 2383-bus system demonstrate the effectiveness of our proposed method.
Imbalanced Sample Generation and Evaluation for Power System Transient Stability Using CTGAN
Dec 16, 2021



Although deep learning has achieved impressive advances in transient stability assessment of power systems, the insufficient and imbalanced samples still trap the training effect of the data-driven methods. This paper proposes a controllable sample generation framework based on Conditional Tabular Generative Adversarial Network (CTGAN) to generate specified transient stability samples. To fit the complex feature distribution of the transient stability samples, the proposed framework firstly models the samples as tabular data and uses Gaussian mixture models to normalize the tabular data. Then we transform multiple conditions into a single conditional vector to enable multi-conditional generation. Furthermore, this paper introduces three evaluation metrics to verify the quality of generated samples based on the proposed framework. Experimental results on the IEEE 39-bus system show that the proposed framework effectively balances the transient stability samples and significantly improves the performance of transient stability assessment models.
Distribution Knowledge Embedding for Graph Pooling
Oct 15, 2021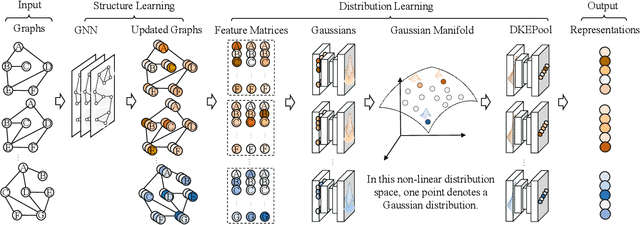
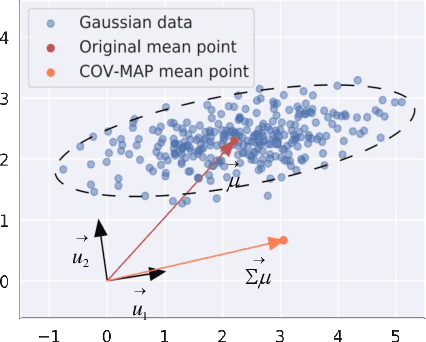
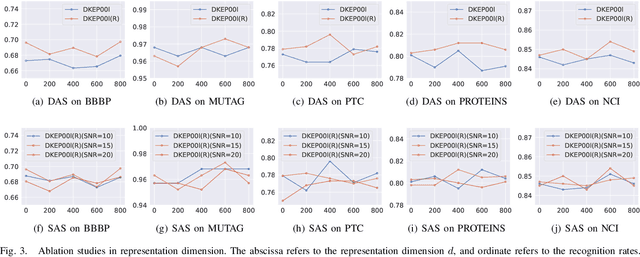
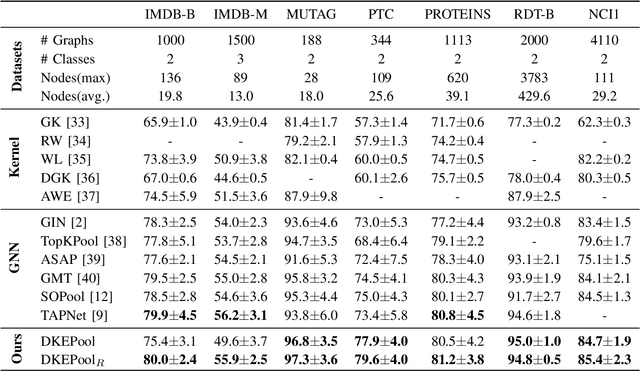
Graph-level representation learning is the pivotal step for downstream tasks that operate on the whole graph. The most common approach to this problem heretofore is graph pooling, where node features are typically averaged or summed to obtain the graph representations. However, pooling operations like averaging or summing inevitably cause massive information missing, which may severely downgrade the final performance. In this paper, we argue what is crucial to graph-level downstream tasks includes not only the topological structure but also the distribution from which nodes are sampled. Therefore, powered by existing Graph Neural Networks (GNN), we propose a new plug-and-play pooling module, termed as Distribution Knowledge Embedding (DKEPool), where graphs are rephrased as distributions on top of GNNs and the pooling goal is to summarize the entire distribution information instead of retaining a certain feature vector by simple predefined pooling operations. A DKEPool network de facto disassembles representation learning into two stages, structure learning and distribution learning. Structure learning follows a recursive neighborhood aggregation scheme to update node features where structure information is obtained. Distribution learning, on the other hand, omits node interconnections and focuses more on the distribution depicted by all the nodes. Extensive experiments demonstrate that the proposed DKEPool significantly and consistently outperforms the state-of-the-art methods.