 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistribution Knowledge Embedding for Graph Pooling
Paper and Code
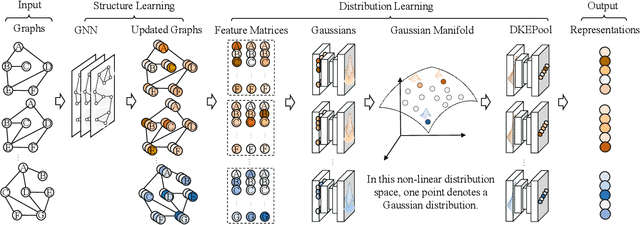
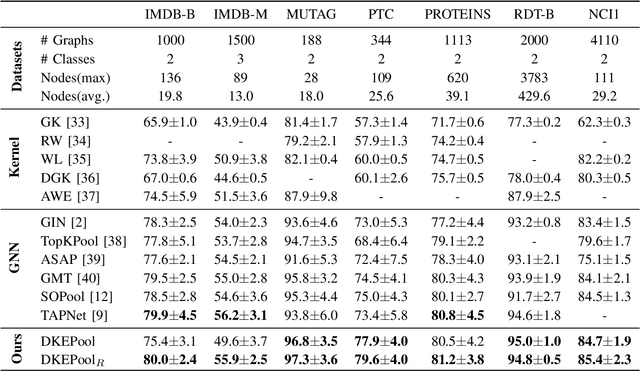
Graph-level representation learning is the pivotal step for downstream tasks that operate on the whole graph. The most common approach to this problem heretofore is graph pooling, where node features are typically averaged or summed to obtain the graph representations. However, pooling operations like averaging or summing inevitably cause massive information missing, which may severely downgrade the final performance. In this paper, we argue what is crucial to graph-level downstream tasks includes not only the topological structure but also the distribution from which nodes are sampled. Therefore, powered by existing Graph Neural Networks (GNN), we propose a new plug-and-play pooling module, termed as Distribution Knowledge Embedding (DKEPool), where graphs are rephrased as distributions on top of GNNs and the pooling goal is to summarize the entire distribution information instead of retaining a certain feature vector by simple predefined pooling operations. A DKEPool network de facto disassembles representation learning into two stages, structure learning and distribution learning. Structure learning follows a recursive neighborhood aggregation scheme to update node features where structure information is obtained. Distribution learning, on the other hand, omits node interconnections and focuses more on the distribution depicted by all the nodes. Extensive experiments demonstrate that the proposed DKEPool significantly and consistently outperforms the state-of-the-art methods.