 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhanced Bloom's Educational Taxonomy for Fostering Information Literacy in the Era of Large Language Models
Mar 25, 2025The advent of Large Language Models (LLMs) has profoundly transformed the paradigms of information retrieval and problem-solving, enabling students to access information acquisition more efficiently to support learning. However, there is currently a lack of standardized evaluation frameworks that guide learners in effectively leveraging LLMs. This paper proposes an LLM-driven Bloom's Educational Taxonomy that aims to recognize and evaluate students' information literacy (IL) with LLMs, and to formalize and guide students practice-based activities of using LLMs to solve complex problems. The framework delineates the IL corresponding to the cognitive abilities required to use LLM into two distinct stages: Exploration & Action and Creation & Metacognition. It further subdivides these into seven phases: Perceiving, Searching, Reasoning, Interacting, Evaluating, Organizing, and Curating. Through the case presentation, the analysis demonstrates the framework's applicability and feasibility, supporting its role in fostering IL among students with varying levels of prior knowledge. This framework fills the existing gap in the analysis of LLM usage frameworks and provides theoretical support for guiding learners to improve IL.
FetalFlex: Anatomy-Guided Diffusion Model for Flexible Control on Fetal Ultrasound Image Synthesis
Mar 19, 2025Fetal ultrasound (US) examinations require the acquisition of multiple planes, each providing unique diagnostic information to evaluate fetal development and screening for congenital anomalies. However, obtaining a comprehensive, multi-plane annotated fetal US dataset remains challenging, particularly for rare or complex anomalies owing to their low incidence and numerous subtypes. This poses difficulties in training novice radiologists and developing robust AI models, especially for detecting abnormal fetuses. In this study, we introduce a Flexible Fetal US image generation framework (FetalFlex) to address these challenges, which leverages anatomical structures and multimodal information to enable controllable synthesis of fetal US images across diverse planes. Specifically, FetalFlex incorporates a pre-alignment module to enhance controllability and introduces a repaint strategy to ensure consistent texture and appearance. Moreover, a two-stage adaptive sampling strategy is developed to progressively refine image quality from coarse to fine levels. We believe that FetalFlex is the first method capable of generating both in-distribution normal and out-of-distribution abnormal fetal US images, without requiring any abnormal data. Experiments on multi-center datasets demonstrate that FetalFlex achieved state-of-the-art performance across multiple image quality metrics. A reader study further confirms the close alignment of the generated results with expert visual assessments. Furthermore, synthetic images by FetalFlex significantly improve the performance of six typical deep models in downstream classification and anomaly detection tasks. Lastly, FetalFlex's anatomy-level controllable generation offers a unique advantage for anomaly simulation and creating paired or counterfactual data at the pixel level. The demo is available at: https://dyf1023.github.io/FetalFlex/.
Aurora:Activating Chinese chat capability for Mixtral-8x7B sparse Mixture-of-Experts through Instruction-Tuning
Jan 01, 2024
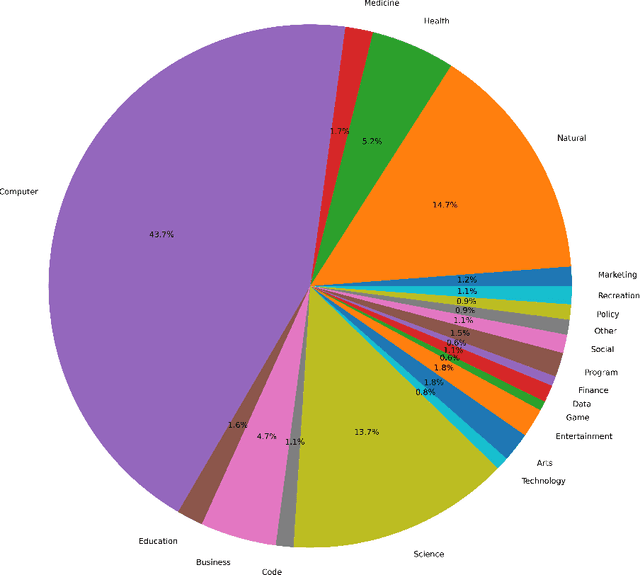

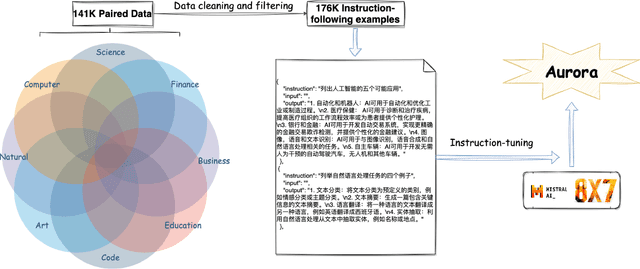
Existing research has demonstrated that refining large language models (LLMs) through the utilization of machine-generated instruction-following data empowers these models to exhibit impressive zero-shot capabilities for novel tasks, without requiring human-authored instructions. In this paper, we systematically investigate, preprocess, and integrate three Chinese instruction-following datasets with the aim of enhancing the Chinese conversational capabilities of Mixtral-8x7B sparse Mixture-of-Experts model. Through instruction fine-tuning on this carefully processed dataset, we successfully construct the Mixtral-8x7B sparse Mixture-of-Experts model named "Aurora." To assess the performance of Aurora, we utilize three widely recognized benchmark tests: C-Eval, MMLU, and CMMLU. Empirical studies validate the effectiveness of instruction fine-tuning applied to Mixtral-8x7B sparse Mixture-of-Experts model. This work is pioneering in the execution of instruction fine-tuning on a sparse expert-mixed model, marking a significant breakthrough in enhancing the capabilities of this model architecture. Our code, data and model are publicly available at https://github.com/WangRongsheng/Aurora
IvyGPT: InteractiVe Chinese pathwaY language model in medical domain
Jul 20, 2023General large language models (LLMs) such as ChatGPT have shown remarkable success. However, such LLMs have not been widely adopted for medical purposes, due to poor accuracy and inability to provide medical advice. We propose IvyGPT, an LLM based on LLaMA that is trained and fine-tuned with high-quality medical question-answer (QA) instances and Reinforcement Learning from Human Feedback (RLHF). After supervised fine-tuning, IvyGPT has good multi-turn conversation capabilities, but it cannot perform like a doctor in other aspects, such as comprehensive diagnosis. Through RLHF, IvyGPT can output richer diagnosis and treatment answers that are closer to human. In the training, we used QLoRA to train 33 billion parameters on a small number of NVIDIA A100 (80GB) GPUs. Experimental results show that IvyGPT has outperformed other medical GPT models.
Multi-source Transfer Learning with Ensemble for Financial Time Series Forecasting
Mar 26, 2021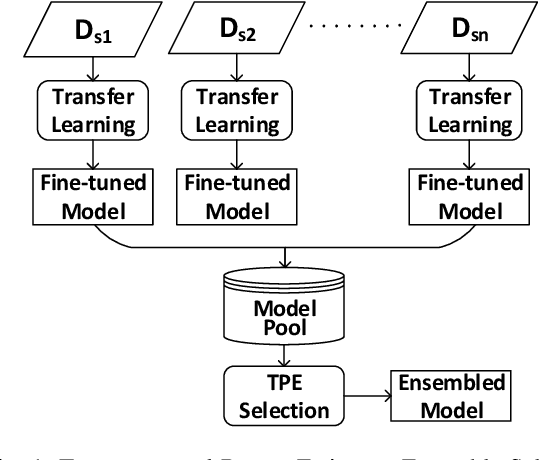



Although transfer learning is proven to be effective in computer vision and natural language processing applications, it is rarely investigated in forecasting financial time series. Majority of existing works on transfer learning are based on single-source transfer learning due to the availability of open-access large-scale datasets. However, in financial domain, the lengths of individual time series are relatively short and single-source transfer learning models are less effective. Therefore, in this paper, we investigate multi-source deep transfer learning for financial time series. We propose two multi-source transfer learning methods namely Weighted Average Ensemble for Transfer Learning (WAETL) and Tree-structured Parzen Estimator Ensemble Selection (TPEES). The effectiveness of our approach is evaluated on financial time series extracted from stock markets. Experiment results reveal that TPEES outperforms other baseline methods on majority of multi-source transfer tasks.