 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeADCD-Net: Robust Document Image Forgery Localization via Adaptive DCT Feature and Hierarchical Content Disentanglement
Jul 22, 2025The advancement of image editing tools has enabled malicious manipulation of sensitive document images, underscoring the need for robust document image forgery detection.Though forgery detectors for natural images have been extensively studied, they struggle with document images, as the tampered regions can be seamlessly blended into the uniform document background (BG) and structured text. On the other hand, existing document-specific methods lack sufficient robustness against various degradations, which limits their practical deployment. This paper presents ADCD-Net, a robust document forgery localization model that adaptively leverages the RGB/DCT forensic traces and integrates key characteristics of document images. Specifically, to address the DCT traces' sensitivity to block misalignment, we adaptively modulate the DCT feature contribution based on a predicted alignment score, resulting in much improved resilience to various distortions, including resizing and cropping. Also, a hierarchical content disentanglement approach is proposed to boost the localization performance via mitigating the text-BG disparities. Furthermore, noticing the predominantly pristine nature of BG regions, we construct a pristine prototype capturing traces of untampered regions, and eventually enhance both the localization accuracy and robustness. Our proposed ADCD-Net demonstrates superior forgery localization performance, consistently outperforming state-of-the-art methods by 20.79\% averaged over 5 types of distortions. The code is available at https://github.com/KAHIMWONG/ACDC-Net.
FontGuard: A Robust Font Watermarking Approach Leveraging Deep Font Knowledge
Apr 04, 2025The proliferation of AI-generated content brings significant concerns on the forensic and security issues such as source tracing, copyright protection, etc, highlighting the need for effective watermarking technologies. Font-based text watermarking has emerged as an effective solution to embed information, which could ensure copyright, traceability, and compliance of the generated text content. Existing font watermarking methods usually neglect essential font knowledge, which leads to watermarked fonts of low quality and limited embedding capacity. These methods are also vulnerable to real-world distortions, low-resolution fonts, and inaccurate character segmentation. In this paper, we introduce FontGuard, a novel font watermarking model that harnesses the capabilities of font models and language-guided contrastive learning. Unlike previous methods that focus solely on the pixel-level alteration, FontGuard modifies fonts by altering hidden style features, resulting in better font quality upon watermark embedding. We also leverage the font manifold to increase the embedding capacity of our proposed method by generating substantial font variants closely resembling the original font. Furthermore, in the decoder, we employ an image-text contrastive learning to reconstruct the embedded bits, which can achieve desirable robustness against various real-world transmission distortions. FontGuard outperforms state-of-the-art methods by +5.4%, +7.4%, and +5.8% in decoding accuracy under synthetic, cross-media, and online social network distortions, respectively, while improving the visual quality by 52.7% in terms of LPIPS. Moreover, FontGuard uniquely allows the generation of watermarked fonts for unseen fonts without re-training the network. The code and dataset are available at https://github.com/KAHIMWONG/FontGuard.
AttFC: Attention Fully-Connected Layer for Large-Scale Face Recognition with One GPU
Mar 10, 2025Nowadays, with the advancement of deep neural networks (DNNs) and the availability of large-scale datasets, the face recognition (FR) model has achieved exceptional performance. However, since the parameter magnitude of the fully connected (FC) layer directly depends on the number of identities in the dataset. If training the FR model on large-scale datasets, the size of the model parameter will be excessively huge, leading to substantial demand for computational resources, such as time and memory. This paper proposes the attention fully connected (AttFC) layer, which could significantly reduce computational resources. AttFC employs an attention loader to generate the generative class center (GCC), and dynamically store the class center with Dynamic Class Container (DCC). DCC only stores a small subset of all class centers in FC, thus its parameter count is substantially less than the FC layer. Also, training face recognition models on large-scale datasets with one GPU often encounter out-of-memory (OOM) issues. AttFC overcomes this and achieves comparable performance to state-of-the-art methods.
MSConv: Multiplicative and Subtractive Convolution for Face Recognition
Mar 08, 2025In Neural Networks, there are various methods of feature fusion. Different strategies can significantly affect the effectiveness of feature representation, consequently influencing the ability of model to extract representative and discriminative features. In the field of face recognition, traditional feature fusion methods include feature concatenation and feature addition. Recently, various attention mechanism-based fusion strategies have emerged. However, we found that these methods primarily focus on the important features in the image, referred to as salient features in this paper, while neglecting another equally important set of features for image recognition tasks, which we term differential features. This may cause the model to overlook critical local differences when dealing with complex facial samples. Therefore, in this paper, we propose an efficient convolution module called MSConv (Multiplicative and Subtractive Convolution), designed to balance the learning of model about salient and differential features. Specifically, we employ multi-scale mixed convolution to capture both local and broader contextual information from face images, and then utilize Multiplication Operation (MO) and Subtraction Operation (SO) to extract salient and differential features, respectively. Experimental results demonstrate that by integrating both salient and differential features, MSConv outperforms models that only focus on salient features.
RVAFM: Re-parameterizing Vertical Attention Fusion Module for Handwritten Paragraph Text Recognition
Mar 05, 2025



Handwritten Paragraph Text Recognition (HPTR) is a challenging task in Computer Vision, requiring the transformation of a paragraph text image, rich in handwritten text, into text encoding sequences. One of the most advanced models for this task is Vertical Attention Network (VAN), which utilizes a Vertical Attention Module (VAM) to implicitly segment paragraph text images into text lines, thereby reducing the difficulty of the recognition task. However, from a network structure perspective, VAM is a single-branch module, which is less effective in learning compared to multi-branch modules. In this paper, we propose a new module, named Re-parameterizing Vertical Attention Fusion Module (RVAFM), which incorporates structural re-parameterization techniques. RVAFM decouples the structure of the module during training and inference stages. During training, it uses a multi-branch structure for more effective learning, and during inference, it uses a single-branch structure for faster processing. The features learned by the multi-branch structure are fused into the single-branch structure through a special fusion method named Re-parameterization Fusion (RF) without any loss of information. As a result, we achieve a Character Error Rate (CER) of 4.44% and a Word Error Rate (WER) of 14.37% on the IAM paragraph-level test set. Additionally, the inference speed is slightly faster than VAN.
X2-Softmax: Margin Adaptive Loss Function for Face Recognition
Dec 19, 2023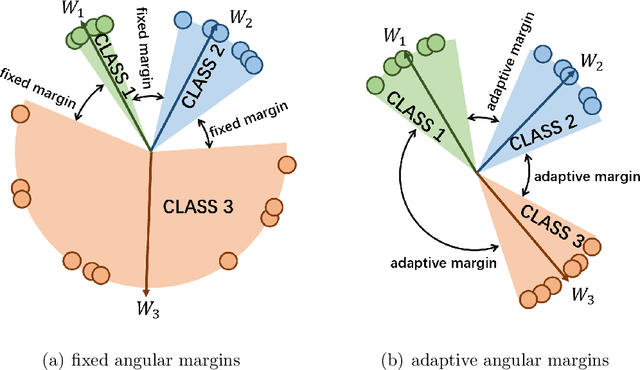

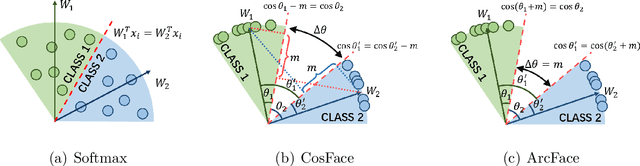

Learning the discriminative features of different faces is an important task in face recognition. By extracting face features in neural networks, it becomes easy to measure the similarity of different face images, which makes face recognition possible. To enhance the neural network's face feature separability, incorporating an angular margin during training is common practice. State-of-the-art loss functions CosFace and ArcFace apply fixed margins between weights of classes to enhance the inter-class separation of face features. Since the distribution of samples in the training set is imbalanced, similarities between different identities are unequal. Therefore, using an inappropriately fixed angular margin may lead to the problem that the model is difficult to converge or the face features are not discriminative enough. It is more in line with our intuition that the margins are angular adaptive, which could increase with the angles between classes growing. In this paper, we propose a new angular margin loss named X2-Softmax. X2-Softmax loss has adaptive angular margins, which provide the margin that increases with the angle between different classes growing. The angular adaptive margin ensures model flexibility and effectively improves the effect of face recognition. We have trained the neural network with X2-Softmax loss on the MS1Mv3 dataset and tested it on several evaluation benchmarks to demonstrate the effectiveness and superiority of our loss function.
KDCTime: Knowledge Distillation with Calibration on InceptionTime for Time-series Classification
Dec 04, 2021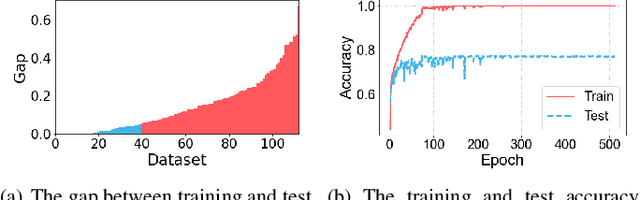


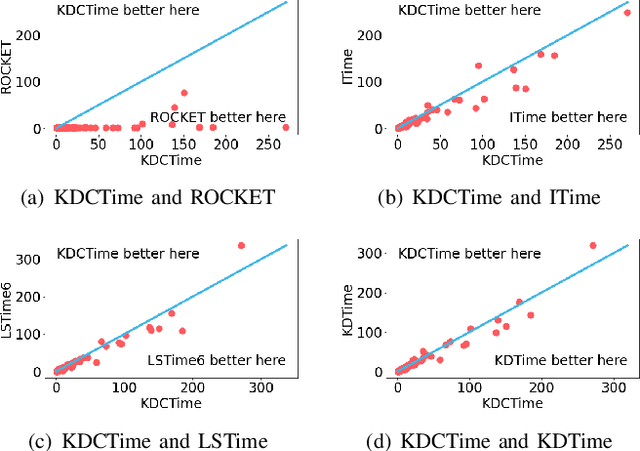
Time-series classification approaches based on deep neural networks are easy to be overfitting on UCR datasets, which is caused by the few-shot problem of those datasets. Therefore, in order to alleviate the overfitting phenomenon for further improving the accuracy, we first propose Label Smoothing for InceptionTime (LSTime), which adopts the information of soft labels compared to just hard labels. Next, instead of manually adjusting soft labels by LSTime, Knowledge Distillation for InceptionTime (KDTime) is proposed in order to automatically generate soft labels by the teacher model. At last, in order to rectify the incorrect predicted soft labels from the teacher model, Knowledge Distillation with Calibration for InceptionTime (KDCTime) is proposed, where it contains two optional calibrating strategies, i.e. KDC by Translating (KDCT) and KDC by Reordering (KDCR). The experimental results show that the accuracy of KDCTime is promising, while its inference time is two orders of magnitude faster than ROCKET with an acceptable training time overhead.
Multi-source Transfer Learning with Ensemble for Financial Time Series Forecasting
Mar 26, 2021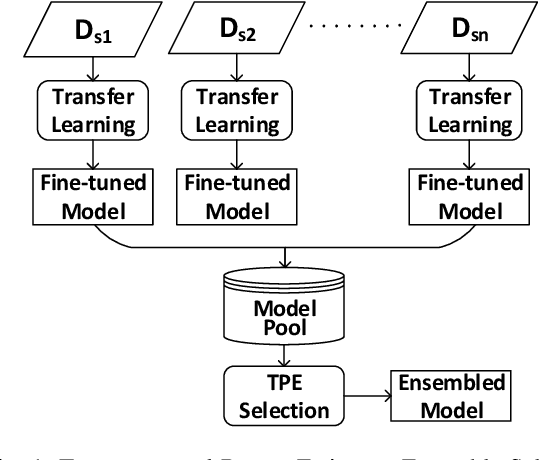



Although transfer learning is proven to be effective in computer vision and natural language processing applications, it is rarely investigated in forecasting financial time series. Majority of existing works on transfer learning are based on single-source transfer learning due to the availability of open-access large-scale datasets. However, in financial domain, the lengths of individual time series are relatively short and single-source transfer learning models are less effective. Therefore, in this paper, we investigate multi-source deep transfer learning for financial time series. We propose two multi-source transfer learning methods namely Weighted Average Ensemble for Transfer Learning (WAETL) and Tree-structured Parzen Estimator Ensemble Selection (TPEES). The effectiveness of our approach is evaluated on financial time series extracted from stock markets. Experiment results reveal that TPEES outperforms other baseline methods on majority of multi-source transfer tasks.