 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttFC: Attention Fully-Connected Layer for Large-Scale Face Recognition with One GPU
Mar 10, 2025Nowadays, with the advancement of deep neural networks (DNNs) and the availability of large-scale datasets, the face recognition (FR) model has achieved exceptional performance. However, since the parameter magnitude of the fully connected (FC) layer directly depends on the number of identities in the dataset. If training the FR model on large-scale datasets, the size of the model parameter will be excessively huge, leading to substantial demand for computational resources, such as time and memory. This paper proposes the attention fully connected (AttFC) layer, which could significantly reduce computational resources. AttFC employs an attention loader to generate the generative class center (GCC), and dynamically store the class center with Dynamic Class Container (DCC). DCC only stores a small subset of all class centers in FC, thus its parameter count is substantially less than the FC layer. Also, training face recognition models on large-scale datasets with one GPU often encounter out-of-memory (OOM) issues. AttFC overcomes this and achieves comparable performance to state-of-the-art methods.
MSConv: Multiplicative and Subtractive Convolution for Face Recognition
Mar 08, 2025In Neural Networks, there are various methods of feature fusion. Different strategies can significantly affect the effectiveness of feature representation, consequently influencing the ability of model to extract representative and discriminative features. In the field of face recognition, traditional feature fusion methods include feature concatenation and feature addition. Recently, various attention mechanism-based fusion strategies have emerged. However, we found that these methods primarily focus on the important features in the image, referred to as salient features in this paper, while neglecting another equally important set of features for image recognition tasks, which we term differential features. This may cause the model to overlook critical local differences when dealing with complex facial samples. Therefore, in this paper, we propose an efficient convolution module called MSConv (Multiplicative and Subtractive Convolution), designed to balance the learning of model about salient and differential features. Specifically, we employ multi-scale mixed convolution to capture both local and broader contextual information from face images, and then utilize Multiplication Operation (MO) and Subtraction Operation (SO) to extract salient and differential features, respectively. Experimental results demonstrate that by integrating both salient and differential features, MSConv outperforms models that only focus on salient features.
AdaSin: Enhancing Hard Sample Metrics with Dual Adaptive Penalty for Face Recognition
Mar 05, 2025In recent years, the emergence of deep convolutional neural networks has positioned face recognition as a prominent research focus in computer vision. Traditional loss functions, such as margin-based, hard-sample mining-based, and hybrid approaches, have achieved notable performance improvements, with some leveraging curriculum learning to optimize training. However, these methods often fall short in effectively quantifying the difficulty of hard samples. To address this, we propose Adaptive Sine (AdaSin) loss function, which introduces the sine of the angle between a sample's embedding feature and its ground-truth class center as a novel difficulty metric. This metric enables precise and effective penalization of hard samples. By incorporating curriculum learning, the model dynamically adjusts classification boundaries across different training stages. Unlike previous adaptive-margin loss functions, AdaSin introduce a dual adaptive penalty, applied to both the positive and negative cosine similarities of hard samples. This design imposes stronger constraints, enhancing intra-class compactness and inter-class separability. The combination of the dual adaptive penalty and curriculum learning is guided by a well-designed difficulty metric. It enables the model to focus more effectively on hard samples in later training stages, and lead to the extraction of highly discriminative face features. Extensive experiments across eight benchmarks demonstrate that AdaSin achieves superior accuracy compared to other state-of-the-art methods.
RVAFM: Re-parameterizing Vertical Attention Fusion Module for Handwritten Paragraph Text Recognition
Mar 05, 2025



Handwritten Paragraph Text Recognition (HPTR) is a challenging task in Computer Vision, requiring the transformation of a paragraph text image, rich in handwritten text, into text encoding sequences. One of the most advanced models for this task is Vertical Attention Network (VAN), which utilizes a Vertical Attention Module (VAM) to implicitly segment paragraph text images into text lines, thereby reducing the difficulty of the recognition task. However, from a network structure perspective, VAM is a single-branch module, which is less effective in learning compared to multi-branch modules. In this paper, we propose a new module, named Re-parameterizing Vertical Attention Fusion Module (RVAFM), which incorporates structural re-parameterization techniques. RVAFM decouples the structure of the module during training and inference stages. During training, it uses a multi-branch structure for more effective learning, and during inference, it uses a single-branch structure for faster processing. The features learned by the multi-branch structure are fused into the single-branch structure through a special fusion method named Re-parameterization Fusion (RF) without any loss of information. As a result, we achieve a Character Error Rate (CER) of 4.44% and a Word Error Rate (WER) of 14.37% on the IAM paragraph-level test set. Additionally, the inference speed is slightly faster than VAN.
MHLR: Moving Haar Learning Rate Scheduler for Large-scale Face Recognition Training with One GPU
Apr 17, 2024



Face recognition (FR) has seen significant advancements due to the utilization of large-scale datasets. Training deep FR models on large-scale datasets with multiple GPUs is now a common practice. In fact, computing power has evolved into a foundational and indispensable resource in the area of deep learning. It is nearly impossible to train a deep FR model without holding adequate hardware resources. Recognizing this challenge, some FR approaches have started exploring ways to reduce the time complexity of the fully-connected layer in FR models. Unlike other approaches, this paper introduces a simple yet highly effective approach, Moving Haar Learning Rate (MHLR) scheduler, for scheduling the learning rate promptly and accurately in the training process. MHLR supports large-scale FR training with only one GPU, which is able to accelerate the model to 1/4 of its original training time without sacrificing more than 1% accuracy. More specifically, MHLR only needs $30$ hours to train the model ResNet100 on the dataset WebFace12M containing more than 12M face images with 0.6M identities. Extensive experiments validate the efficiency and effectiveness of MHLR.
X2-Softmax: Margin Adaptive Loss Function for Face Recognition
Dec 19, 2023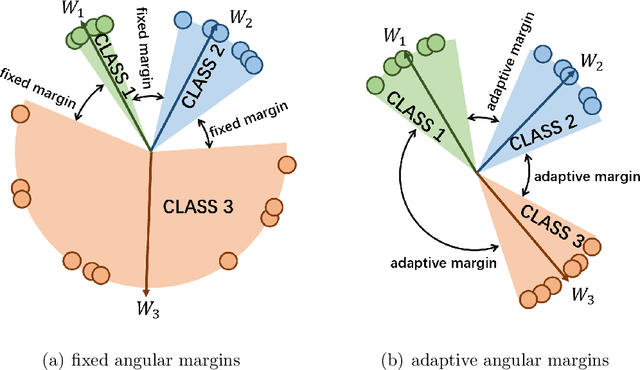

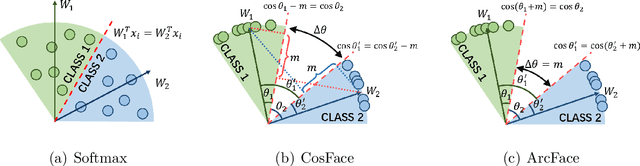

Learning the discriminative features of different faces is an important task in face recognition. By extracting face features in neural networks, it becomes easy to measure the similarity of different face images, which makes face recognition possible. To enhance the neural network's face feature separability, incorporating an angular margin during training is common practice. State-of-the-art loss functions CosFace and ArcFace apply fixed margins between weights of classes to enhance the inter-class separation of face features. Since the distribution of samples in the training set is imbalanced, similarities between different identities are unequal. Therefore, using an inappropriately fixed angular margin may lead to the problem that the model is difficult to converge or the face features are not discriminative enough. It is more in line with our intuition that the margins are angular adaptive, which could increase with the angles between classes growing. In this paper, we propose a new angular margin loss named X2-Softmax. X2-Softmax loss has adaptive angular margins, which provide the margin that increases with the angle between different classes growing. The angular adaptive margin ensures model flexibility and effectively improves the effect of face recognition. We have trained the neural network with X2-Softmax loss on the MS1Mv3 dataset and tested it on several evaluation benchmarks to demonstrate the effectiveness and superiority of our loss function.
GIU-GANs: Global Information Utilization for Generative Adversarial Networks
Jan 25, 2022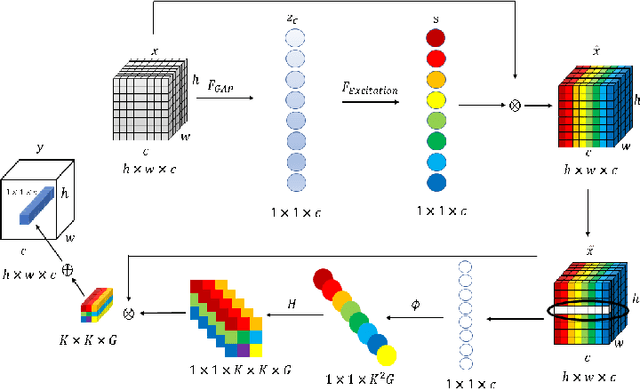

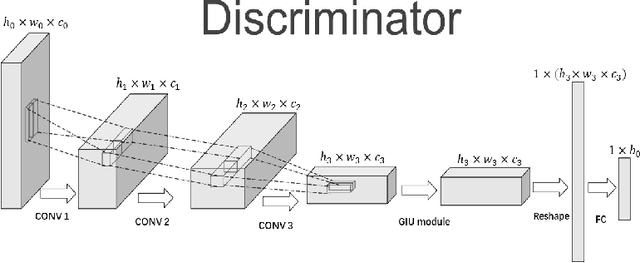

In recent years, with the rapid development of artificial intelligence, image generation based on deep learning has dramatically advanced. Image generation based on Generative Adversarial Networks (GANs) is a promising study. However, since convolutions are limited by spatial-agnostic and channel-specific, features extracted by traditional GANs based on convolution are constrained. Therefore, GANs are unable to capture any more details per image. On the other hand, straightforwardly stacking of convolutions causes too many parameters and layers in GANs, which will lead to a high risk of overfitting. To overcome the aforementioned limitations, in this paper, we propose a new GANs called Involution Generative Adversarial Networks (GIU-GANs). GIU-GANs leverages a brand new module called the Global Information Utilization (GIU) module, which integrates Squeeze-and-Excitation Networks (SENet) and involution to focus on global information by channel attention mechanism, leading to a higher quality of generated images. Meanwhile, Batch Normalization(BN) inevitably ignores the representation differences among noise sampled by the generator, and thus degrade the generated image quality. Thus we introduce Representative Batch Normalization(RBN) to the GANs architecture for this issue. The CIFAR-10 and CelebA datasets are employed to demonstrate the effectiveness of our proposed model. A large number of experiments prove that our model achieves state-of-the-art competitive performance.
KDCTime: Knowledge Distillation with Calibration on InceptionTime for Time-series Classification
Dec 04, 2021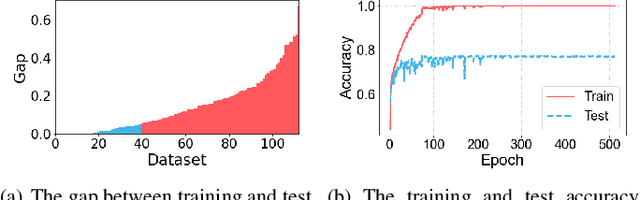


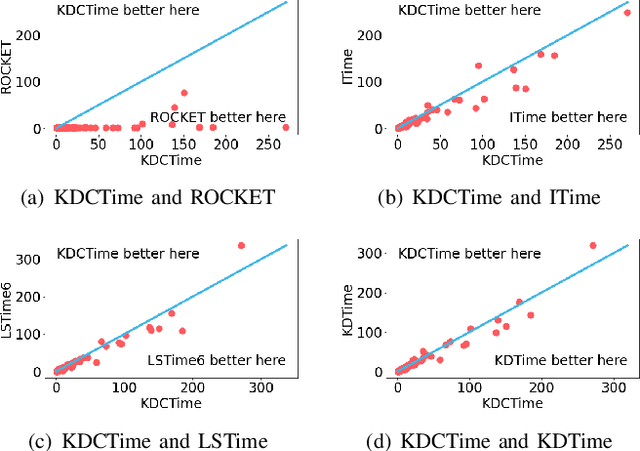
Time-series classification approaches based on deep neural networks are easy to be overfitting on UCR datasets, which is caused by the few-shot problem of those datasets. Therefore, in order to alleviate the overfitting phenomenon for further improving the accuracy, we first propose Label Smoothing for InceptionTime (LSTime), which adopts the information of soft labels compared to just hard labels. Next, instead of manually adjusting soft labels by LSTime, Knowledge Distillation for InceptionTime (KDTime) is proposed in order to automatically generate soft labels by the teacher model. At last, in order to rectify the incorrect predicted soft labels from the teacher model, Knowledge Distillation with Calibration for InceptionTime (KDCTime) is proposed, where it contains two optional calibrating strategies, i.e. KDC by Translating (KDCT) and KDC by Reordering (KDCR). The experimental results show that the accuracy of KDCTime is promising, while its inference time is two orders of magnitude faster than ROCKET with an acceptable training time overhead.