 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Semantic 3D Hand-Object Interaction Generation via Functional Text Guidance
Feb 28, 2025Hand-object interaction(HOI) is the fundamental link between human and environment, yet its dexterous and complex pose significantly challenges for gesture control. Despite significant advances in AI and robotics, enabling machines to understand and simulate hand-object interactions, capturing the semantics of functional grasping tasks remains a considerable challenge. While previous work can generate stable and correct 3D grasps, they are still far from achieving functional grasps due to unconsidered grasp semantics. To address this challenge, we propose an innovative two-stage framework, Functional Grasp Synthesis Net (FGS-Net), for generating 3D HOI driven by functional text. This framework consists of a text-guided 3D model generator, Functional Grasp Generator (FGG), and a pose optimization strategy, Functional Grasp Refiner (FGR). FGG generates 3D models of hands and objects based on text input, while FGR fine-tunes the poses using Object Pose Approximator and energy functions to ensure the relative position between the hand and object aligns with human intent and remains physically plausible. Extensive experiments demonstrate that our approach achieves precise and high-quality HOI generation without requiring additional 3D annotation data.
GIU-GANs: Global Information Utilization for Generative Adversarial Networks
Jan 25, 2022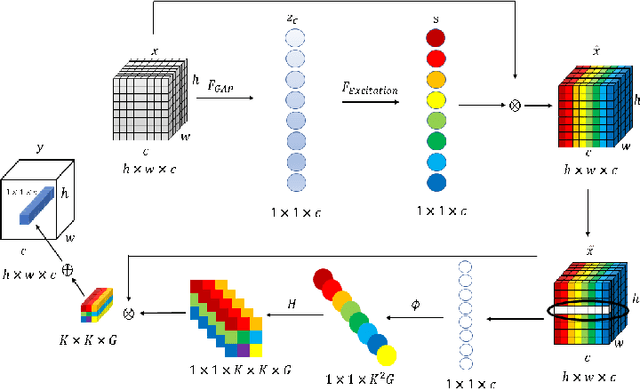

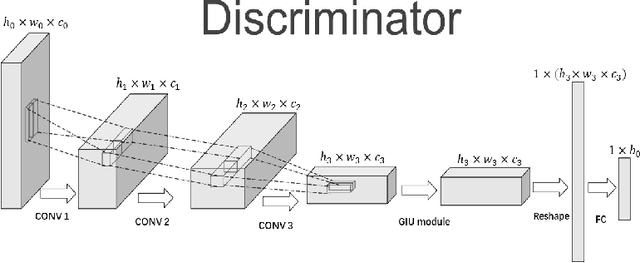

In recent years, with the rapid development of artificial intelligence, image generation based on deep learning has dramatically advanced. Image generation based on Generative Adversarial Networks (GANs) is a promising study. However, since convolutions are limited by spatial-agnostic and channel-specific, features extracted by traditional GANs based on convolution are constrained. Therefore, GANs are unable to capture any more details per image. On the other hand, straightforwardly stacking of convolutions causes too many parameters and layers in GANs, which will lead to a high risk of overfitting. To overcome the aforementioned limitations, in this paper, we propose a new GANs called Involution Generative Adversarial Networks (GIU-GANs). GIU-GANs leverages a brand new module called the Global Information Utilization (GIU) module, which integrates Squeeze-and-Excitation Networks (SENet) and involution to focus on global information by channel attention mechanism, leading to a higher quality of generated images. Meanwhile, Batch Normalization(BN) inevitably ignores the representation differences among noise sampled by the generator, and thus degrade the generated image quality. Thus we introduce Representative Batch Normalization(RBN) to the GANs architecture for this issue. The CIFAR-10 and CelebA datasets are employed to demonstrate the effectiveness of our proposed model. A large number of experiments prove that our model achieves state-of-the-art competitive performance.
KDCTime: Knowledge Distillation with Calibration on InceptionTime for Time-series Classification
Dec 04, 2021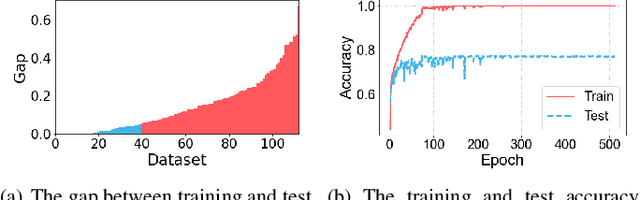


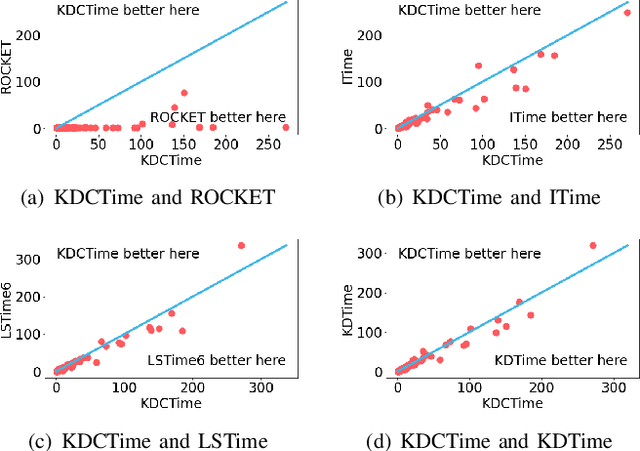
Time-series classification approaches based on deep neural networks are easy to be overfitting on UCR datasets, which is caused by the few-shot problem of those datasets. Therefore, in order to alleviate the overfitting phenomenon for further improving the accuracy, we first propose Label Smoothing for InceptionTime (LSTime), which adopts the information of soft labels compared to just hard labels. Next, instead of manually adjusting soft labels by LSTime, Knowledge Distillation for InceptionTime (KDTime) is proposed in order to automatically generate soft labels by the teacher model. At last, in order to rectify the incorrect predicted soft labels from the teacher model, Knowledge Distillation with Calibration for InceptionTime (KDCTime) is proposed, where it contains two optional calibrating strategies, i.e. KDC by Translating (KDCT) and KDC by Reordering (KDCR). The experimental results show that the accuracy of KDCTime is promising, while its inference time is two orders of magnitude faster than ROCKET with an acceptable training time overhead.