 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShotFinder: Imagination-Driven Open-Domain Video Shot Retrieval via Web Search
Jan 30, 2026In recent years, large language models (LLMs) have made rapid progress in information retrieval, yet existing research has mainly focused on text or static multimodal settings. Open-domain video shot retrieval, which involves richer temporal structure and more complex semantics, still lacks systematic benchmarks and analysis. To fill this gap, we introduce ShotFinder, a benchmark that formalizes editing requirements as keyframe-oriented shot descriptions and introduces five types of controllable single-factor constraints: Temporal order, Color, Visual style, Audio, and Resolution. We curate 1,210 high-quality samples from YouTube across 20 thematic categories, using large models for generation with human verification. Based on the benchmark, we propose ShotFinder, a text-driven three-stage retrieval and localization pipeline: (1) query expansion via video imagination, (2) candidate video retrieval with a search engine, and (3) description-guided temporal localization. Experiments on multiple closed-source and open-source models reveal a significant gap to human performance, with clear imbalance across constraints: temporal localization is relatively tractable, while color and visual style remain major challenges. These results reveal that open-domain video shot retrieval is still a critical capability that multimodal large models have yet to overcome.
Unified Multimodal and Multilingual Retrieval via Multi-Task Learning with NLU Integration
Jan 21, 2026Multimodal retrieval systems typically employ Vision Language Models (VLMs) that encode images and text independently into vectors within a shared embedding space. Despite incorporating text encoders, VLMs consistently underperform specialized text models on text-only retrieval tasks. Moreover, introducing additional text encoders increases storage, inference overhead, and exacerbates retrieval inefficiencies, especially in multilingual settings. To address these limitations, we propose a multi-task learning framework that unifies the feature representation across images, long and short texts, and intent-rich queries. To our knowledge, this is the first work to jointly optimize multilingual image retrieval, text retrieval, and natural language understanding (NLU) tasks within a single framework. Our approach integrates image and text retrieval with a shared text encoder that is enhanced by NLU features for intent understanding and retrieval accuracy.
SCRIBES: Web-Scale Script-Based Semi-Structured Data Extraction with Reinforcement Learning
Oct 02, 2025
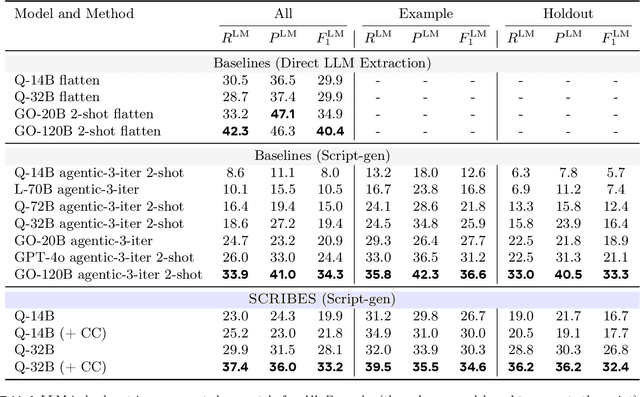


Semi-structured content in HTML tables, lists, and infoboxes accounts for a substantial share of factual data on the web, yet the formatting complicates usage, and reliably extracting structured information from them remains challenging. Existing methods either lack generalization or are resource-intensive due to per-page LLM inference. In this paper, we introduce SCRIBES (SCRIpt-Based Semi-Structured Content Extraction at Web-Scale), a novel reinforcement learning framework that leverages layout similarity across webpages within the same site as a reward signal. Instead of processing each page individually, SCRIBES generates reusable extraction scripts that can be applied to groups of structurally similar webpages. Our approach further improves by iteratively training on synthetic annotations from in-the-wild CommonCrawl data. Experiments show that our approach outperforms strong baselines by over 13% in script quality and boosts downstream question answering accuracy by more than 4% for GPT-4o, enabling scalable and resource-efficient web information extraction.
Stream RAG: Instant and Accurate Spoken Dialogue Systems with Streaming Tool Usage
Oct 02, 2025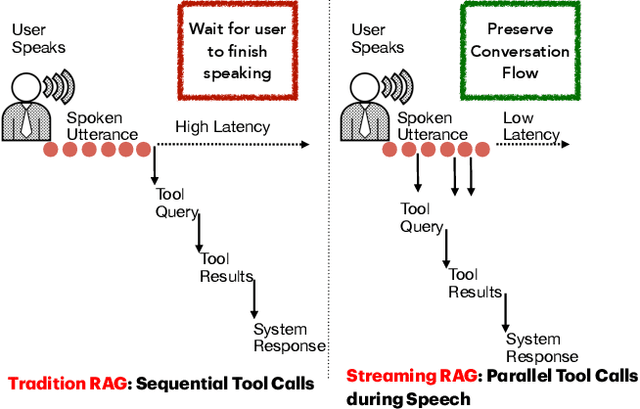
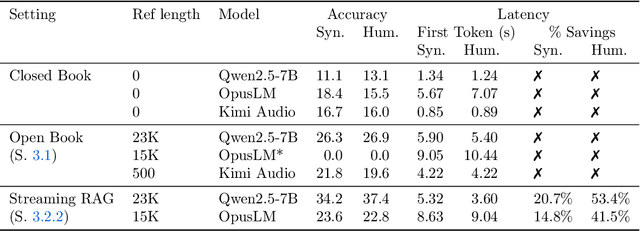
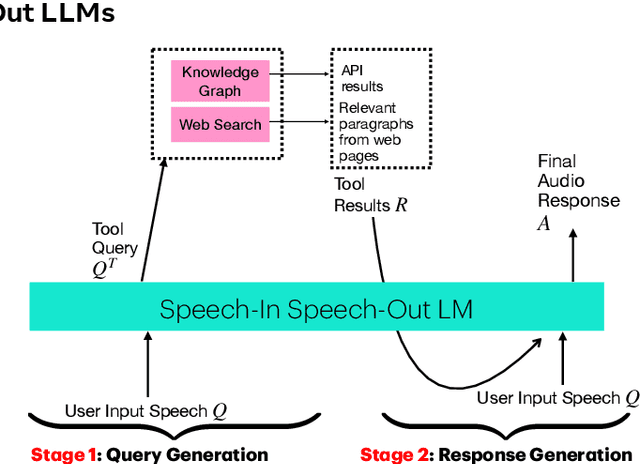
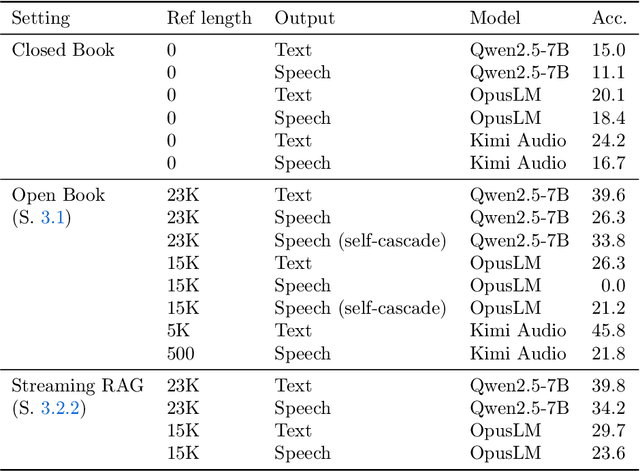
End-to-end speech-in speech-out dialogue systems are emerging as a powerful alternative to traditional ASR-LLM-TTS pipelines, generating more natural, expressive responses with significantly lower latency. However, these systems remain prone to hallucinations due to limited factual grounding. While text-based dialogue systems address this challenge by integrating tools such as web search and knowledge graph APIs, we introduce the first approach to extend tool use directly into speech-in speech-out systems. A key challenge is that tool integration substantially increases response latency, disrupting conversational flow. To mitigate this, we propose Streaming Retrieval-Augmented Generation (Streaming RAG), a novel framework that reduces user-perceived latency by predicting tool queries in parallel with user speech, even before the user finishes speaking. Specifically, we develop a post-training pipeline that teaches the model when to issue tool calls during ongoing speech and how to generate spoken summaries that fuse audio queries with retrieved text results, thereby improving both accuracy and responsiveness. To evaluate our approach, we construct AudioCRAG, a benchmark created by converting queries from the publicly available CRAG dataset into speech form. Experimental results demonstrate that our streaming RAG approach increases QA accuracy by up to 200% relative (from 11.1% to 34.2% absolute) and further enhances user experience by reducing tool use latency by 20%. Importantly, our streaming RAG approach is modality-agnostic and can be applied equally to typed input, paving the way for more agentic, real-time AI assistants.
GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
Aug 08, 2025We present GLM-4.5, an open-source Mixture-of-Experts (MoE) large language model with 355B total parameters and 32B activated parameters, featuring a hybrid reasoning method that supports both thinking and direct response modes. Through multi-stage training on 23T tokens and comprehensive post-training with expert model iteration and reinforcement learning, GLM-4.5 achieves strong performance across agentic, reasoning, and coding (ARC) tasks, scoring 70.1% on TAU-Bench, 91.0% on AIME 24, and 64.2% on SWE-bench Verified. With much fewer parameters than several competitors, GLM-4.5 ranks 3rd overall among all evaluated models and 2nd on agentic benchmarks. We release both GLM-4.5 (355B parameters) and a compact version, GLM-4.5-Air (106B parameters), to advance research in reasoning and agentic AI systems. Code, models, and more information are available at https://github.com/zai-org/GLM-4.5.
LogisticsVLN: Vision-Language Navigation For Low-Altitude Terminal Delivery Based on Agentic UAVs
May 06, 2025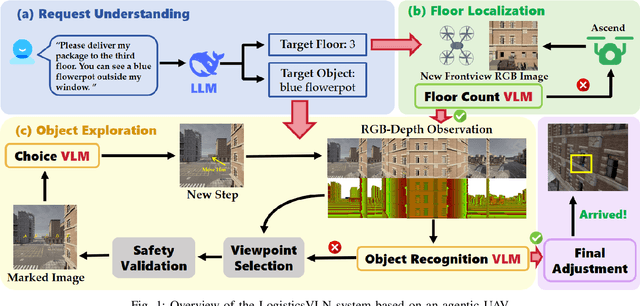
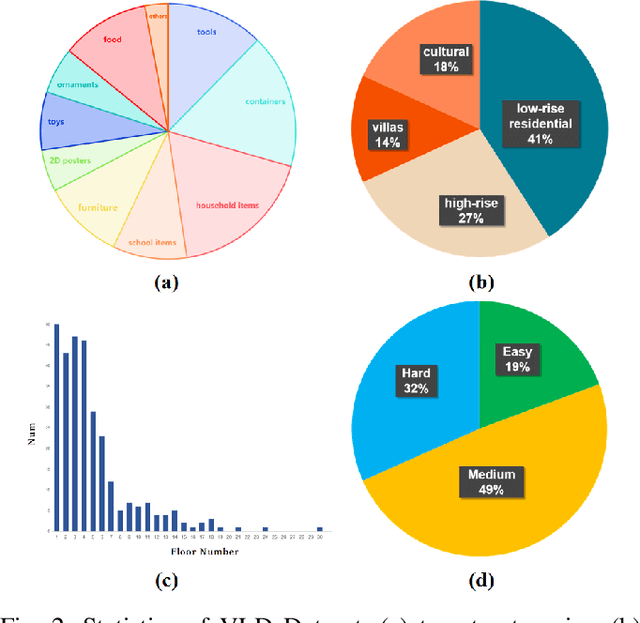

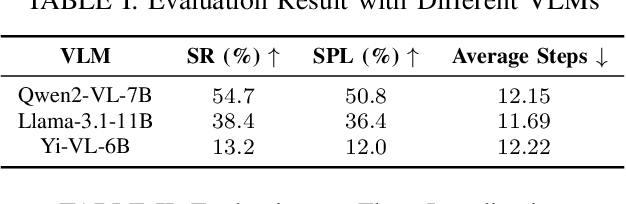
The growing demand for intelligent logistics, particularly fine-grained terminal delivery, underscores the need for autonomous UAV (Unmanned Aerial Vehicle)-based delivery systems. However, most existing last-mile delivery studies rely on ground robots, while current UAV-based Vision-Language Navigation (VLN) tasks primarily focus on coarse-grained, long-range goals, making them unsuitable for precise terminal delivery. To bridge this gap, we propose LogisticsVLN, a scalable aerial delivery system built on multimodal large language models (MLLMs) for autonomous terminal delivery. LogisticsVLN integrates lightweight Large Language Models (LLMs) and Visual-Language Models (VLMs) in a modular pipeline for request understanding, floor localization, object detection, and action-decision making. To support research and evaluation in this new setting, we construct the Vision-Language Delivery (VLD) dataset within the CARLA simulator. Experimental results on the VLD dataset showcase the feasibility of the LogisticsVLN system. In addition, we conduct subtask-level evaluations of each module of our system, offering valuable insights for improving the robustness and real-world deployment of foundation model-based vision-language delivery systems.
AttFC: Attention Fully-Connected Layer for Large-Scale Face Recognition with One GPU
Mar 10, 2025Nowadays, with the advancement of deep neural networks (DNNs) and the availability of large-scale datasets, the face recognition (FR) model has achieved exceptional performance. However, since the parameter magnitude of the fully connected (FC) layer directly depends on the number of identities in the dataset. If training the FR model on large-scale datasets, the size of the model parameter will be excessively huge, leading to substantial demand for computational resources, such as time and memory. This paper proposes the attention fully connected (AttFC) layer, which could significantly reduce computational resources. AttFC employs an attention loader to generate the generative class center (GCC), and dynamically store the class center with Dynamic Class Container (DCC). DCC only stores a small subset of all class centers in FC, thus its parameter count is substantially less than the FC layer. Also, training face recognition models on large-scale datasets with one GPU often encounter out-of-memory (OOM) issues. AttFC overcomes this and achieves comparable performance to state-of-the-art methods.
MSConv: Multiplicative and Subtractive Convolution for Face Recognition
Mar 08, 2025In Neural Networks, there are various methods of feature fusion. Different strategies can significantly affect the effectiveness of feature representation, consequently influencing the ability of model to extract representative and discriminative features. In the field of face recognition, traditional feature fusion methods include feature concatenation and feature addition. Recently, various attention mechanism-based fusion strategies have emerged. However, we found that these methods primarily focus on the important features in the image, referred to as salient features in this paper, while neglecting another equally important set of features for image recognition tasks, which we term differential features. This may cause the model to overlook critical local differences when dealing with complex facial samples. Therefore, in this paper, we propose an efficient convolution module called MSConv (Multiplicative and Subtractive Convolution), designed to balance the learning of model about salient and differential features. Specifically, we employ multi-scale mixed convolution to capture both local and broader contextual information from face images, and then utilize Multiplication Operation (MO) and Subtraction Operation (SO) to extract salient and differential features, respectively. Experimental results demonstrate that by integrating both salient and differential features, MSConv outperforms models that only focus on salient features.
RVAFM: Re-parameterizing Vertical Attention Fusion Module for Handwritten Paragraph Text Recognition
Mar 05, 2025



Handwritten Paragraph Text Recognition (HPTR) is a challenging task in Computer Vision, requiring the transformation of a paragraph text image, rich in handwritten text, into text encoding sequences. One of the most advanced models for this task is Vertical Attention Network (VAN), which utilizes a Vertical Attention Module (VAM) to implicitly segment paragraph text images into text lines, thereby reducing the difficulty of the recognition task. However, from a network structure perspective, VAM is a single-branch module, which is less effective in learning compared to multi-branch modules. In this paper, we propose a new module, named Re-parameterizing Vertical Attention Fusion Module (RVAFM), which incorporates structural re-parameterization techniques. RVAFM decouples the structure of the module during training and inference stages. During training, it uses a multi-branch structure for more effective learning, and during inference, it uses a single-branch structure for faster processing. The features learned by the multi-branch structure are fused into the single-branch structure through a special fusion method named Re-parameterization Fusion (RF) without any loss of information. As a result, we achieve a Character Error Rate (CER) of 4.44% and a Word Error Rate (WER) of 14.37% on the IAM paragraph-level test set. Additionally, the inference speed is slightly faster than VAN.
Deep Learning-Based Diffusion MRI Tractography: Integrating Spatial and Anatomical Information
Mar 05, 2025Diffusion MRI tractography technique enables non-invasive visualization of the white matter pathways in the brain. It plays a crucial role in neuroscience and clinical fields by facilitating the study of brain connectivity and neurological disorders. However, the accuracy of reconstructed tractograms has been a longstanding challenge. Recently, deep learning methods have been applied to improve tractograms for better white matter coverage, but often comes at the expense of generating excessive false-positive connections. This is largely due to their reliance on local information to predict long range streamlines. To improve the accuracy of streamline propagation predictions, we introduce a novel deep learning framework that integrates image-domain spatial information and anatomical information along tracts, with the former extracted through convolutional layers and the later modeled via a Transformer-decoder. Additionally, we employ a weighted loss function to address fiber class imbalance encountered during training. We evaluate the proposed method on the simulated ISMRM 2015 Tractography Challenge dataset, achieving a valid streamline rate of 66.2%, white matter coverage of 63.8%, and successfully reconstructing 24 out of 25 bundles. Furthermore, on the multi-site Tractoinferno dataset, the proposed method demonstrates its ability to handle various diffusion MRI acquisition schemes, achieving a 5.7% increase in white matter coverage and a 4.1% decrease in overreach compared to RNN-based methods.