 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient lattice field theory simulation using adaptive normalizing flow on a resistive memory-based neural differential equation solver
Sep 16, 2025Lattice field theory (LFT) simulations underpin advances in classical statistical mechanics and quantum field theory, providing a unified computational framework across particle, nuclear, and condensed matter physics. However, the application of these methods to high-dimensional systems remains severely constrained by several challenges, including the prohibitive computational cost and limited parallelizability of conventional sampling algorithms such as hybrid Monte Carlo (HMC), the substantial training expense associated with traditional normalizing flow models, and the inherent energy inefficiency of digital hardware architectures. Here, we introduce a software-hardware co-design that integrates an adaptive normalizing flow (ANF) model with a resistive memory-based neural differential equation solver, enabling efficient generation of LFT configurations. Software-wise, ANF enables efficient parallel generation of statistically independent configurations, thereby reducing computational costs, while low-rank adaptation (LoRA) allows cost-effective fine-tuning across diverse simulation parameters. Hardware-wise, in-memory computing with resistive memory substantially enhances both parallelism and energy efficiency. We validate our approach on the scalar phi4 theory and the effective field theory of graphene wires, using a hybrid analog-digital neural differential equation solver equipped with a 180 nm resistive memory in-memory computing macro. Our co-design enables low-cost computation, achieving approximately 8.2-fold and 13.9-fold reductions in integrated autocorrelation time over HMC, while requiring fine-tuning of less than 8% of the weights via LoRA. Compared to state-of-the-art GPUs, our co-design achieves up to approximately 16.1- and 17.0-fold speedups for the two tasks, as well as 73.7- and 138.0-fold improvements in energy efficiency.
Topology Optimization of Random Memristors for Input-Aware Dynamic SNN
Jul 26, 2024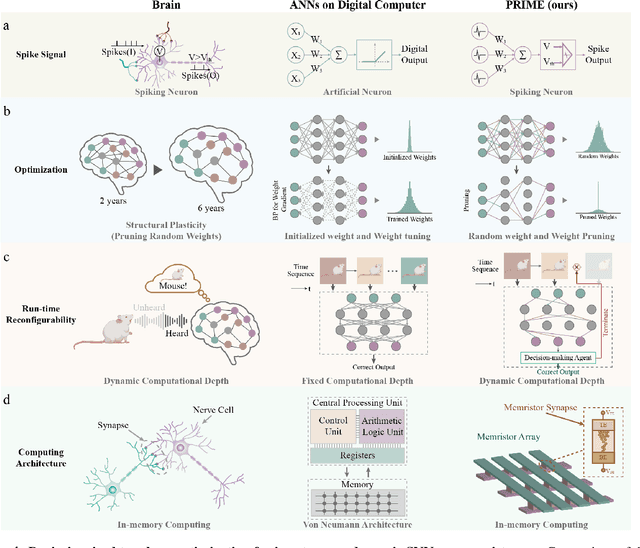
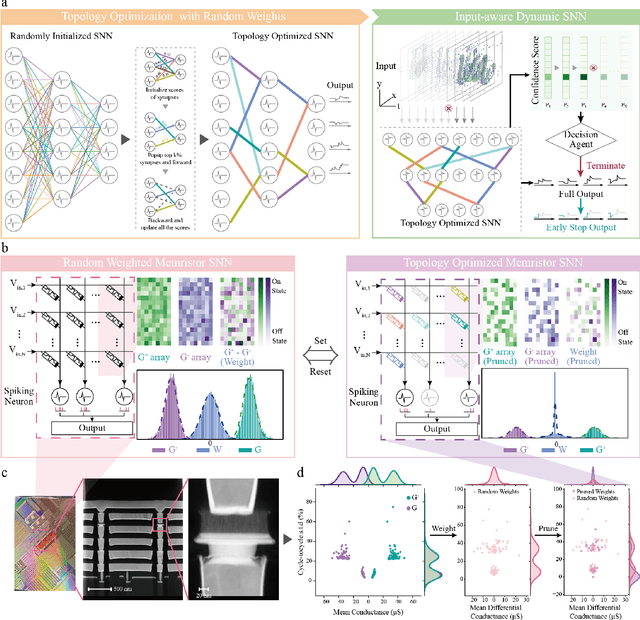
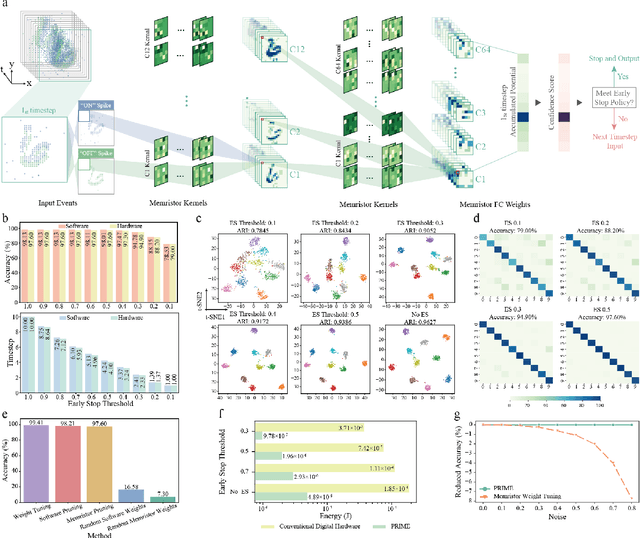
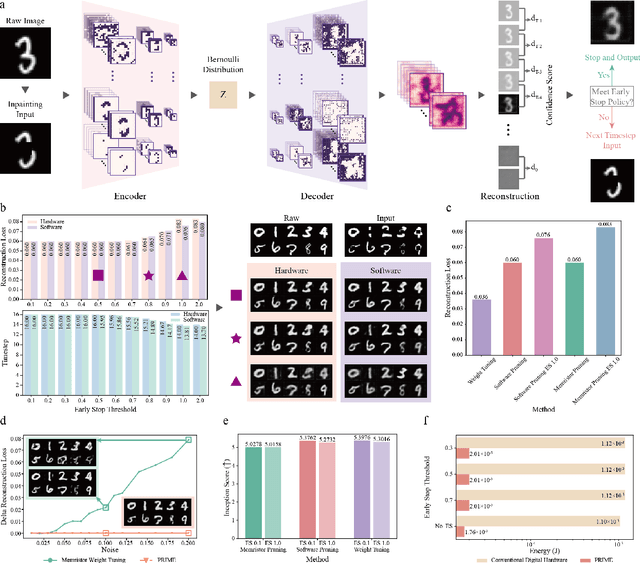
There is unprecedented development in machine learning, exemplified by recent large language models and world simulators, which are artificial neural networks running on digital computers. However, they still cannot parallel human brains in terms of energy efficiency and the streamlined adaptability to inputs of different difficulties, due to differences in signal representation, optimization, run-time reconfigurability, and hardware architecture. To address these fundamental challenges, we introduce pruning optimization for input-aware dynamic memristive spiking neural network (PRIME). Signal representation-wise, PRIME employs leaky integrate-and-fire neurons to emulate the brain's inherent spiking mechanism. Drawing inspiration from the brain's structural plasticity, PRIME optimizes the topology of a random memristive spiking neural network without expensive memristor conductance fine-tuning. For runtime reconfigurability, inspired by the brain's dynamic adjustment of computational depth, PRIME employs an input-aware dynamic early stop policy to minimize latency during inference, thereby boosting energy efficiency without compromising performance. Architecture-wise, PRIME leverages memristive in-memory computing, mirroring the brain and mitigating the von Neumann bottleneck. We validated our system using a 40 nm 256 Kb memristor-based in-memory computing macro on neuromorphic image classification and image inpainting. Our results demonstrate the classification accuracy and Inception Score are comparable to the software baseline, while achieving maximal 62.50-fold improvements in energy efficiency, and maximal 77.0% computational load savings. The system also exhibits robustness against stochastic synaptic noise of analogue memristors. Our software-hardware co-designed model paves the way to future brain-inspired neuromorphic computing with brain-like energy efficiency and adaptivity.
Continuous-Time Digital Twin with Analogue Memristive Neural Ordinary Differential Equation Solver
Jun 12, 2024Digital twins, the cornerstone of Industry 4.0, replicate real-world entities through computer models, revolutionising fields such as manufacturing management and industrial automation. Recent advances in machine learning provide data-driven methods for developing digital twins using discrete-time data and finite-depth models on digital computers. However, this approach fails to capture the underlying continuous dynamics and struggles with modelling complex system behaviour. Additionally, the architecture of digital computers, with separate storage and processing units, necessitates frequent data transfers and Analogue-Digital (A/D) conversion, thereby significantly increasing both time and energy costs. Here, we introduce a memristive neural ordinary differential equation (ODE) solver for digital twins, which is capable of capturing continuous-time dynamics and facilitates the modelling of complex systems using an infinite-depth model. By integrating storage and computation within analogue memristor arrays, we circumvent the von Neumann bottleneck, thus enhancing both speed and energy efficiency. We experimentally validate our approach by developing a digital twin of the HP memristor, which accurately extrapolates its nonlinear dynamics, achieving a 4.2-fold projected speedup and a 41.4-fold projected decrease in energy consumption compared to state-of-the-art digital hardware, while maintaining an acceptable error margin. Additionally, we demonstrate scalability through experimentally grounded simulations of Lorenz96 dynamics, exhibiting projected performance improvements of 12.6-fold in speed and 189.7-fold in energy efficiency relative to traditional digital approaches. By harnessing the capabilities of fully analogue computing, our breakthrough accelerates the development of digital twins, offering an efficient and rapid solution to meet the demands of Industry 4.0.
Efficient and accurate neural field reconstruction using resistive memory
Apr 15, 2024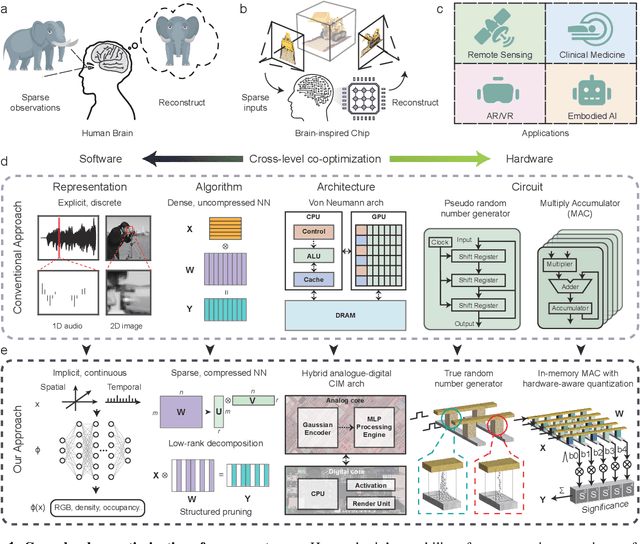
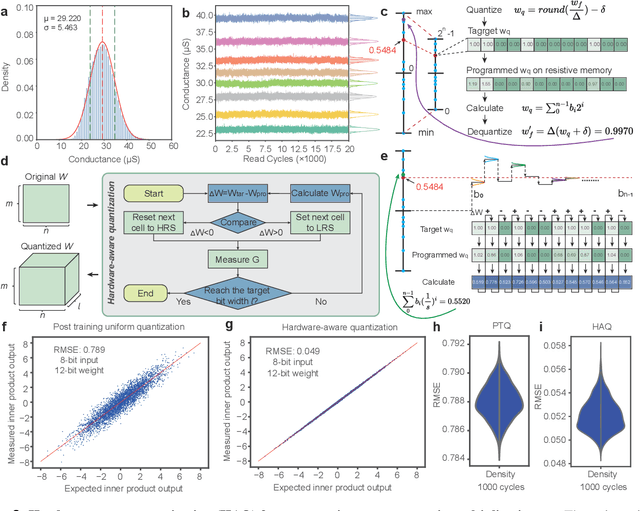
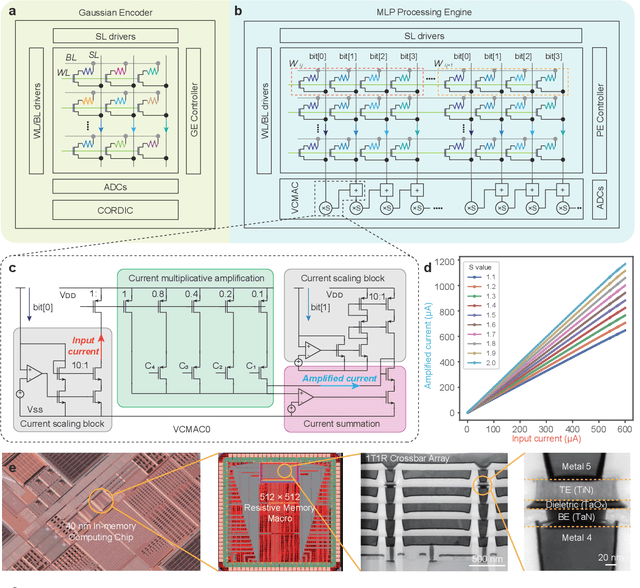
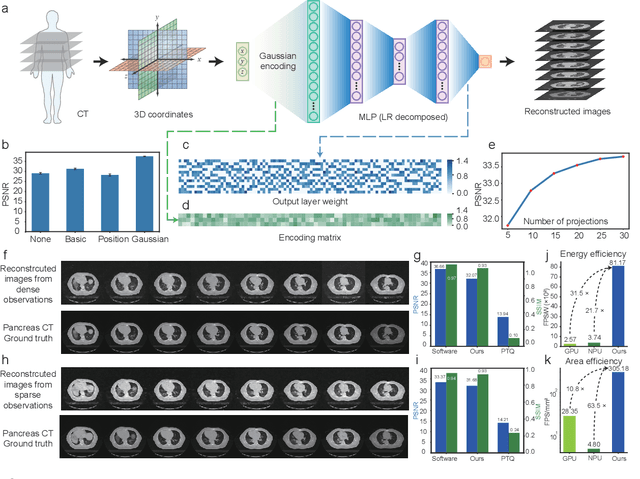
Human beings construct perception of space by integrating sparse observations into massively interconnected synapses and neurons, offering a superior parallelism and efficiency. Replicating this capability in AI finds wide applications in medical imaging, AR/VR, and embodied AI, where input data is often sparse and computing resources are limited. However, traditional signal reconstruction methods on digital computers face both software and hardware challenges. On the software front, difficulties arise from storage inefficiencies in conventional explicit signal representation. Hardware obstacles include the von Neumann bottleneck, which limits data transfer between the CPU and memory, and the limitations of CMOS circuits in supporting parallel processing. We propose a systematic approach with software-hardware co-optimizations for signal reconstruction from sparse inputs. Software-wise, we employ neural field to implicitly represent signals via neural networks, which is further compressed using low-rank decomposition and structured pruning. Hardware-wise, we design a resistive memory-based computing-in-memory (CIM) platform, featuring a Gaussian Encoder (GE) and an MLP Processing Engine (PE). The GE harnesses the intrinsic stochasticity of resistive memory for efficient input encoding, while the PE achieves precise weight mapping through a Hardware-Aware Quantization (HAQ) circuit. We demonstrate the system's efficacy on a 40nm 256Kb resistive memory-based in-memory computing macro, achieving huge energy efficiency and parallelism improvements without compromising reconstruction quality in tasks like 3D CT sparse reconstruction, novel view synthesis, and novel view synthesis for dynamic scenes. This work advances the AI-driven signal restoration technology and paves the way for future efficient and robust medical AI and 3D vision applications.
Resistive Memory-based Neural Differential Equation Solver for Score-based Diffusion Model
Apr 08, 2024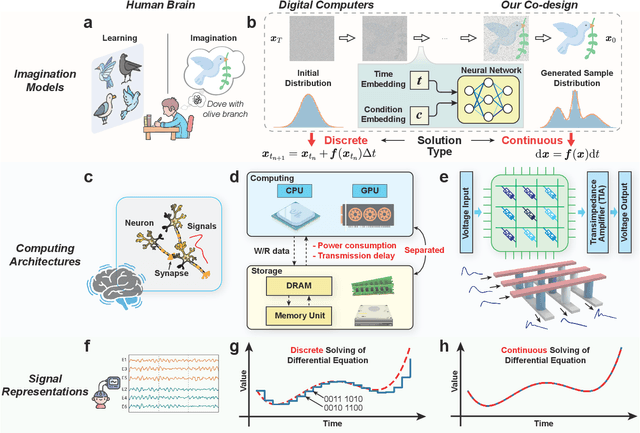
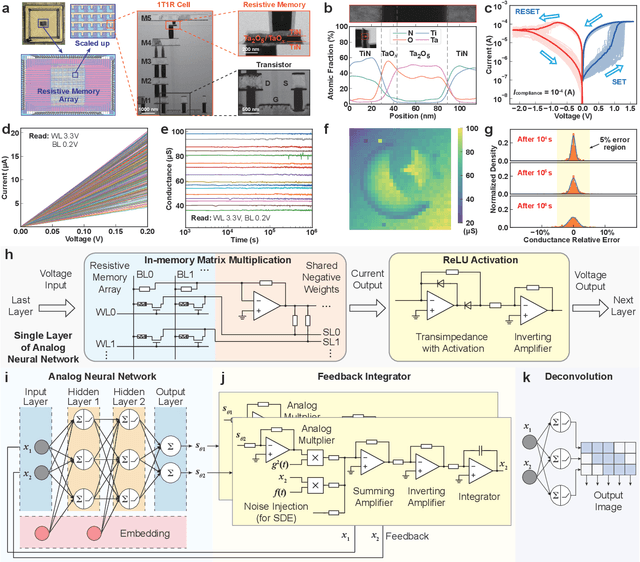
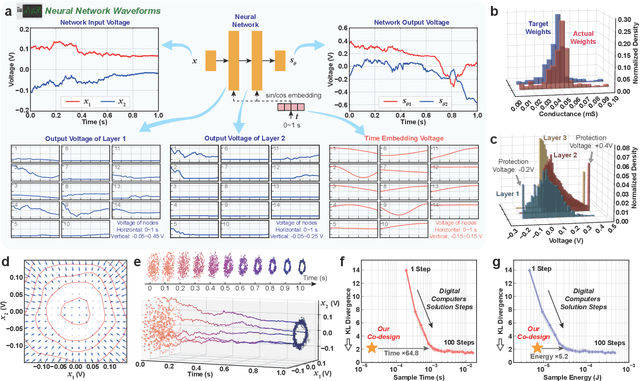
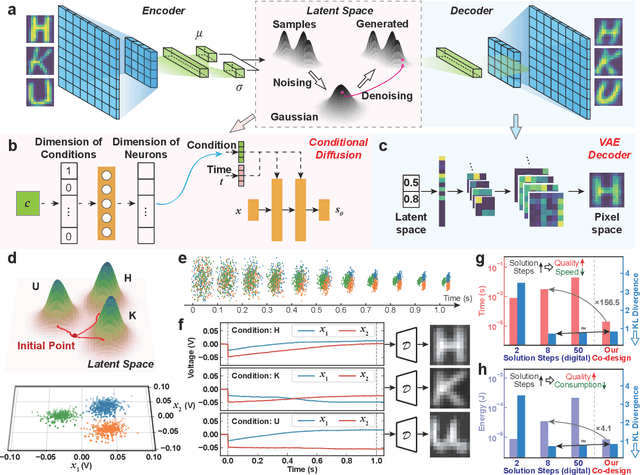
Human brains image complicated scenes when reading a novel. Replicating this imagination is one of the ultimate goals of AI-Generated Content (AIGC). However, current AIGC methods, such as score-based diffusion, are still deficient in terms of rapidity and efficiency. This deficiency is rooted in the difference between the brain and digital computers. Digital computers have physically separated storage and processing units, resulting in frequent data transfers during iterative calculations, incurring large time and energy overheads. This issue is further intensified by the conversion of inherently continuous and analog generation dynamics, which can be formulated by neural differential equations, into discrete and digital operations. Inspired by the brain, we propose a time-continuous and analog in-memory neural differential equation solver for score-based diffusion, employing emerging resistive memory. The integration of storage and computation within resistive memory synapses surmount the von Neumann bottleneck, benefiting the generative speed and energy efficiency. The closed-loop feedback integrator is time-continuous, analog, and compact, physically implementing an infinite-depth neural network. Moreover, the software-hardware co-design is intrinsically robust to analog noise. We experimentally validate our solution with 180 nm resistive memory in-memory computing macros. Demonstrating equivalent generative quality to the software baseline, our system achieved remarkable enhancements in generative speed for both unconditional and conditional generation tasks, by factors of 64.8 and 156.5, respectively. Moreover, it accomplished reductions in energy consumption by factors of 5.2 and 4.1. Our approach heralds a new horizon for hardware solutions in edge computing for generative AI applications.