 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopology Optimization of Random Memristors for Input-Aware Dynamic SNN
Jul 26, 2024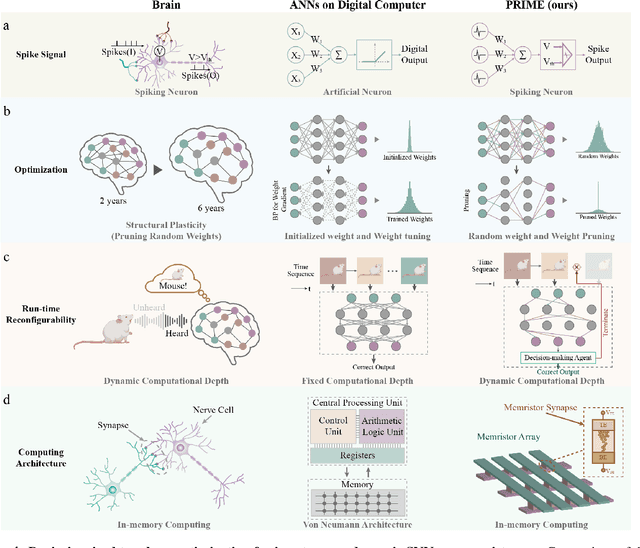
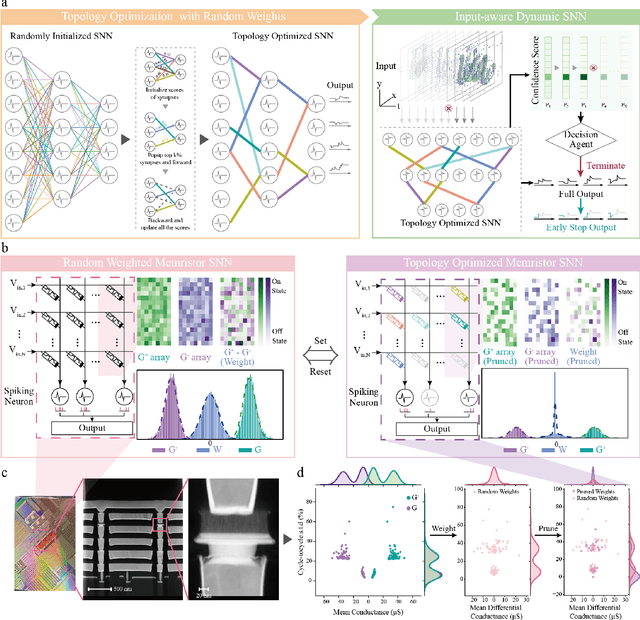
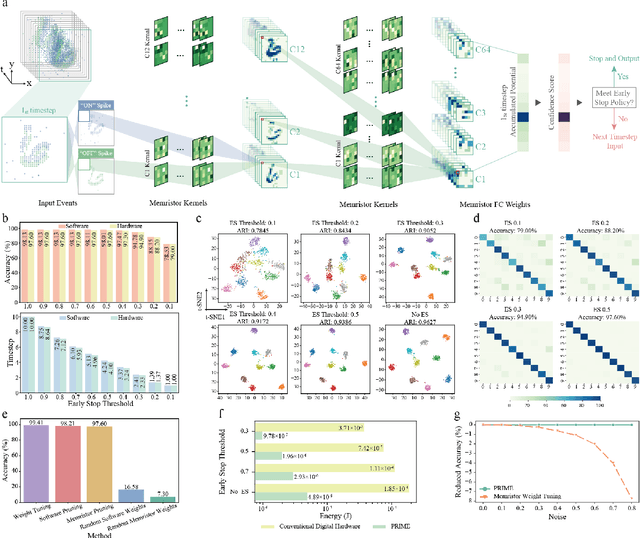
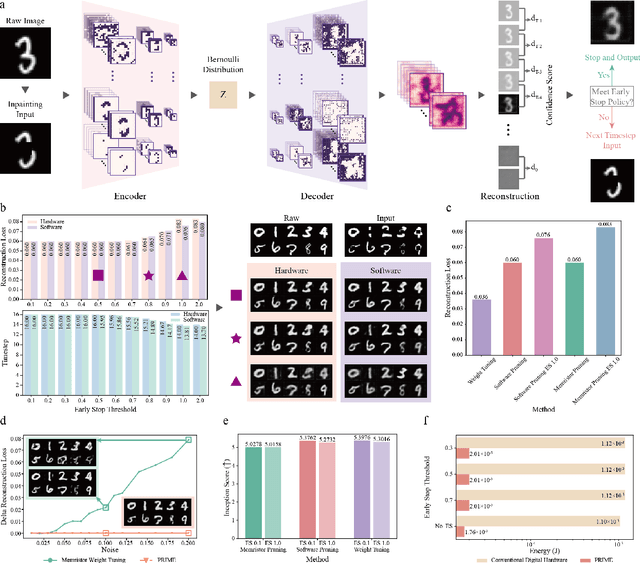
There is unprecedented development in machine learning, exemplified by recent large language models and world simulators, which are artificial neural networks running on digital computers. However, they still cannot parallel human brains in terms of energy efficiency and the streamlined adaptability to inputs of different difficulties, due to differences in signal representation, optimization, run-time reconfigurability, and hardware architecture. To address these fundamental challenges, we introduce pruning optimization for input-aware dynamic memristive spiking neural network (PRIME). Signal representation-wise, PRIME employs leaky integrate-and-fire neurons to emulate the brain's inherent spiking mechanism. Drawing inspiration from the brain's structural plasticity, PRIME optimizes the topology of a random memristive spiking neural network without expensive memristor conductance fine-tuning. For runtime reconfigurability, inspired by the brain's dynamic adjustment of computational depth, PRIME employs an input-aware dynamic early stop policy to minimize latency during inference, thereby boosting energy efficiency without compromising performance. Architecture-wise, PRIME leverages memristive in-memory computing, mirroring the brain and mitigating the von Neumann bottleneck. We validated our system using a 40 nm 256 Kb memristor-based in-memory computing macro on neuromorphic image classification and image inpainting. Our results demonstrate the classification accuracy and Inception Score are comparable to the software baseline, while achieving maximal 62.50-fold improvements in energy efficiency, and maximal 77.0% computational load savings. The system also exhibits robustness against stochastic synaptic noise of analogue memristors. Our software-hardware co-designed model paves the way to future brain-inspired neuromorphic computing with brain-like energy efficiency and adaptivity.
Dynamic neural network with memristive CIM and CAM for 2D and 3D vision
Jul 12, 2024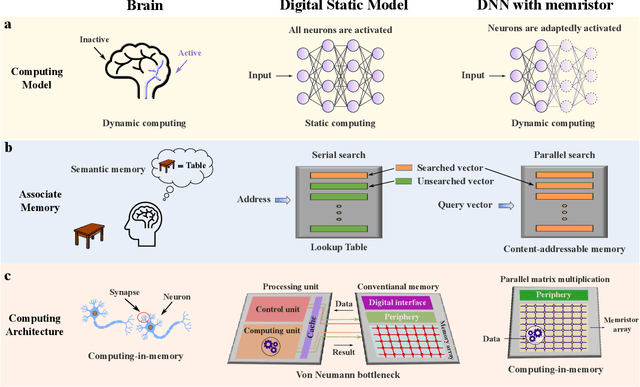
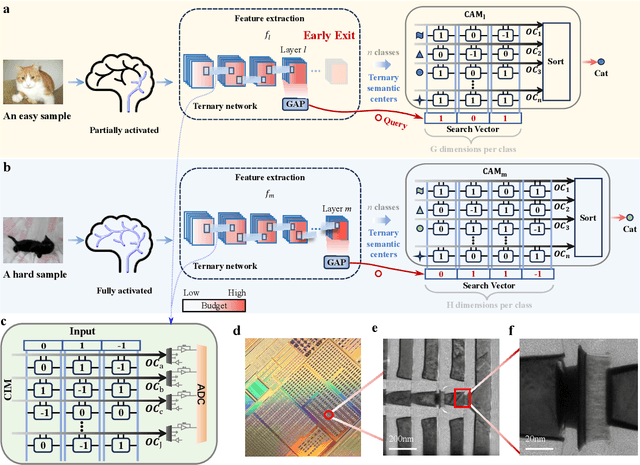
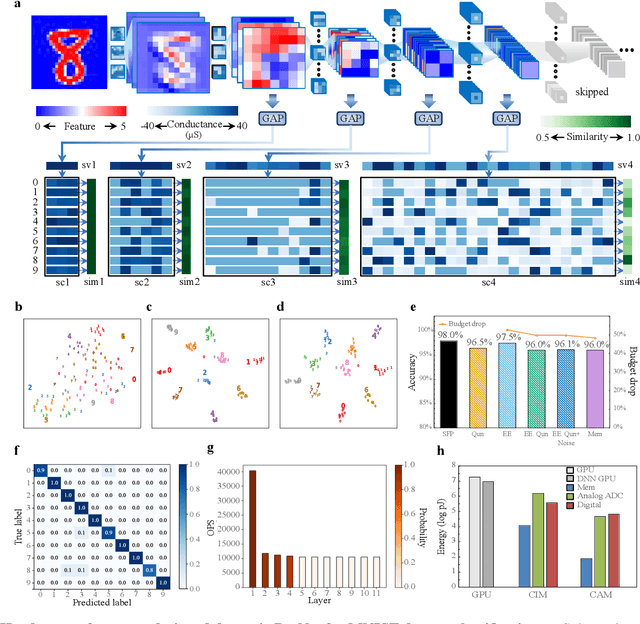
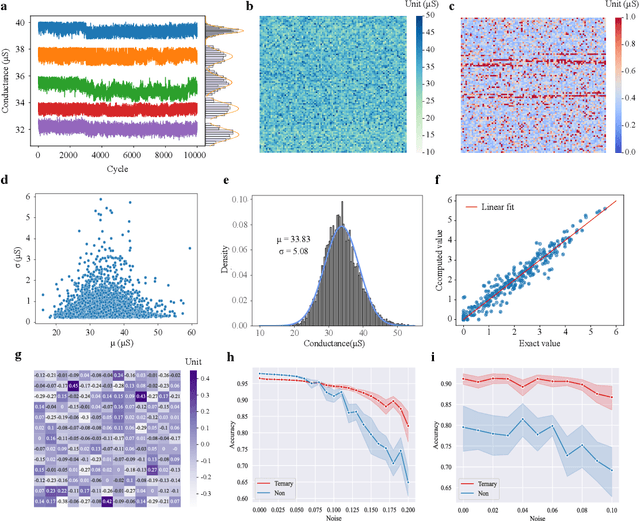
The brain is dynamic, associative and efficient. It reconfigures by associating the inputs with past experiences, with fused memory and processing. In contrast, AI models are static, unable to associate inputs with past experiences, and run on digital computers with physically separated memory and processing. We propose a hardware-software co-design, a semantic memory-based dynamic neural network (DNN) using memristor. The network associates incoming data with the past experience stored as semantic vectors. The network and the semantic memory are physically implemented on noise-robust ternary memristor-based Computing-In-Memory (CIM) and Content-Addressable Memory (CAM) circuits, respectively. We validate our co-designs, using a 40nm memristor macro, on ResNet and PointNet++ for classifying images and 3D points from the MNIST and ModelNet datasets, which not only achieves accuracy on par with software but also a 48.1% and 15.9% reduction in computational budget. Moreover, it delivers a 77.6% and 93.3% reduction in energy consumption.
Continuous-Time Digital Twin with Analogue Memristive Neural Ordinary Differential Equation Solver
Jun 12, 2024Digital twins, the cornerstone of Industry 4.0, replicate real-world entities through computer models, revolutionising fields such as manufacturing management and industrial automation. Recent advances in machine learning provide data-driven methods for developing digital twins using discrete-time data and finite-depth models on digital computers. However, this approach fails to capture the underlying continuous dynamics and struggles with modelling complex system behaviour. Additionally, the architecture of digital computers, with separate storage and processing units, necessitates frequent data transfers and Analogue-Digital (A/D) conversion, thereby significantly increasing both time and energy costs. Here, we introduce a memristive neural ordinary differential equation (ODE) solver for digital twins, which is capable of capturing continuous-time dynamics and facilitates the modelling of complex systems using an infinite-depth model. By integrating storage and computation within analogue memristor arrays, we circumvent the von Neumann bottleneck, thus enhancing both speed and energy efficiency. We experimentally validate our approach by developing a digital twin of the HP memristor, which accurately extrapolates its nonlinear dynamics, achieving a 4.2-fold projected speedup and a 41.4-fold projected decrease in energy consumption compared to state-of-the-art digital hardware, while maintaining an acceptable error margin. Additionally, we demonstrate scalability through experimentally grounded simulations of Lorenz96 dynamics, exhibiting projected performance improvements of 12.6-fold in speed and 189.7-fold in energy efficiency relative to traditional digital approaches. By harnessing the capabilities of fully analogue computing, our breakthrough accelerates the development of digital twins, offering an efficient and rapid solution to meet the demands of Industry 4.0.
Efficient and accurate neural field reconstruction using resistive memory
Apr 15, 2024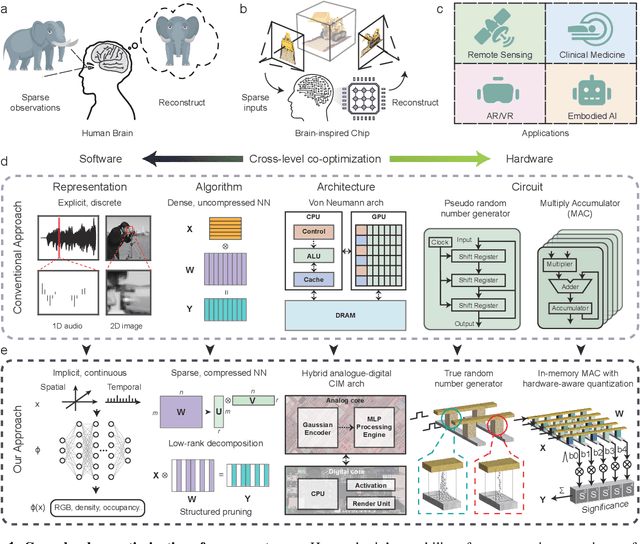
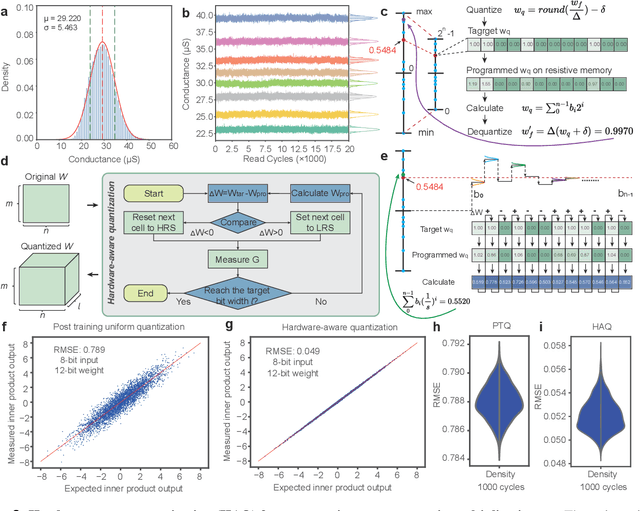
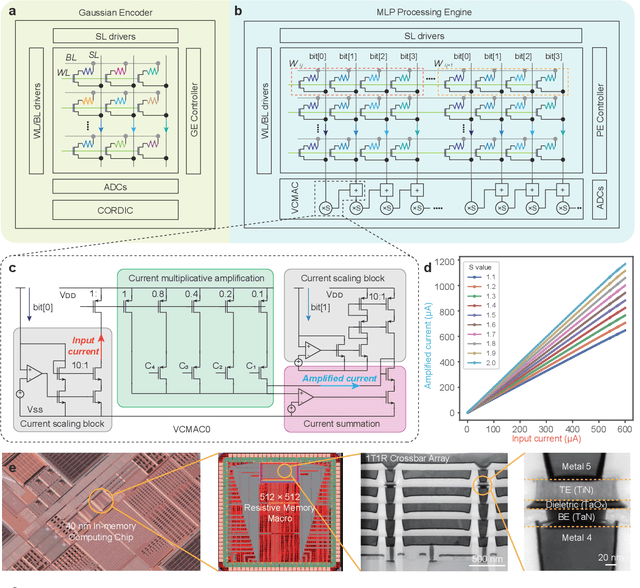
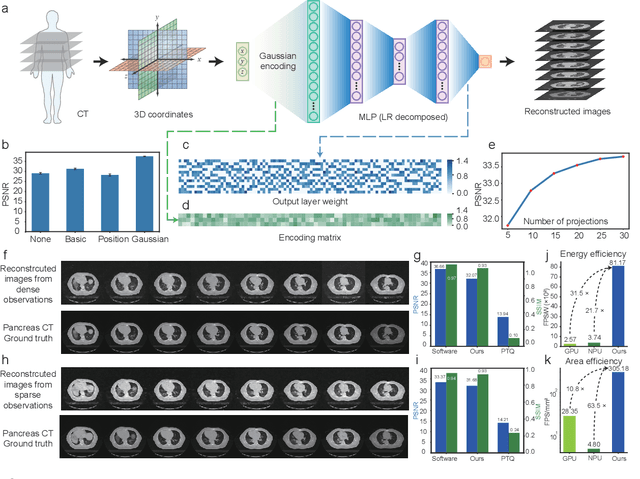
Human beings construct perception of space by integrating sparse observations into massively interconnected synapses and neurons, offering a superior parallelism and efficiency. Replicating this capability in AI finds wide applications in medical imaging, AR/VR, and embodied AI, where input data is often sparse and computing resources are limited. However, traditional signal reconstruction methods on digital computers face both software and hardware challenges. On the software front, difficulties arise from storage inefficiencies in conventional explicit signal representation. Hardware obstacles include the von Neumann bottleneck, which limits data transfer between the CPU and memory, and the limitations of CMOS circuits in supporting parallel processing. We propose a systematic approach with software-hardware co-optimizations for signal reconstruction from sparse inputs. Software-wise, we employ neural field to implicitly represent signals via neural networks, which is further compressed using low-rank decomposition and structured pruning. Hardware-wise, we design a resistive memory-based computing-in-memory (CIM) platform, featuring a Gaussian Encoder (GE) and an MLP Processing Engine (PE). The GE harnesses the intrinsic stochasticity of resistive memory for efficient input encoding, while the PE achieves precise weight mapping through a Hardware-Aware Quantization (HAQ) circuit. We demonstrate the system's efficacy on a 40nm 256Kb resistive memory-based in-memory computing macro, achieving huge energy efficiency and parallelism improvements without compromising reconstruction quality in tasks like 3D CT sparse reconstruction, novel view synthesis, and novel view synthesis for dynamic scenes. This work advances the AI-driven signal restoration technology and paves the way for future efficient and robust medical AI and 3D vision applications.
Pruning random resistive memory for optimizing analogue AI
Nov 13, 2023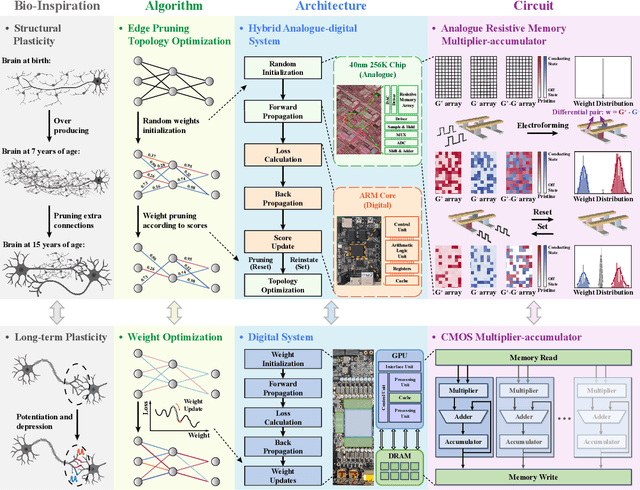
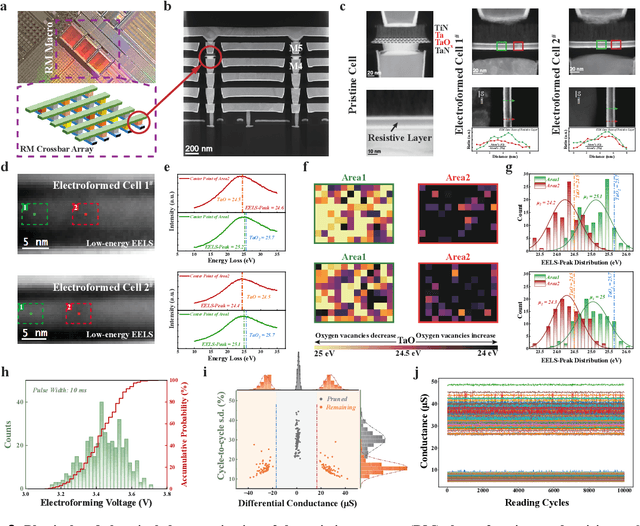
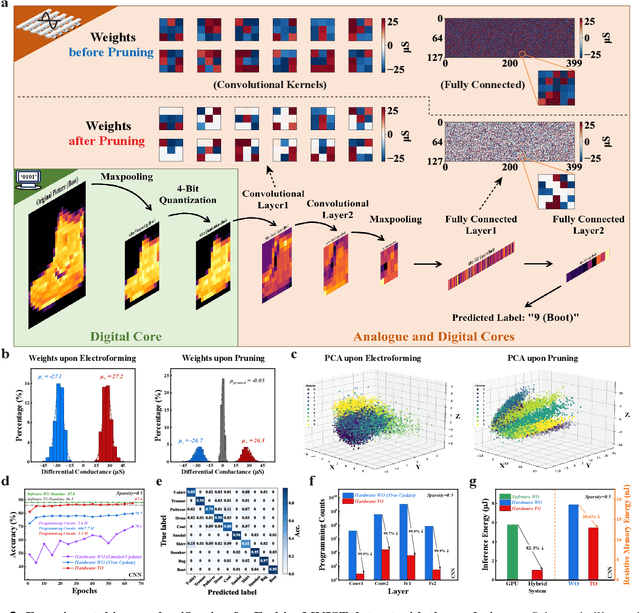
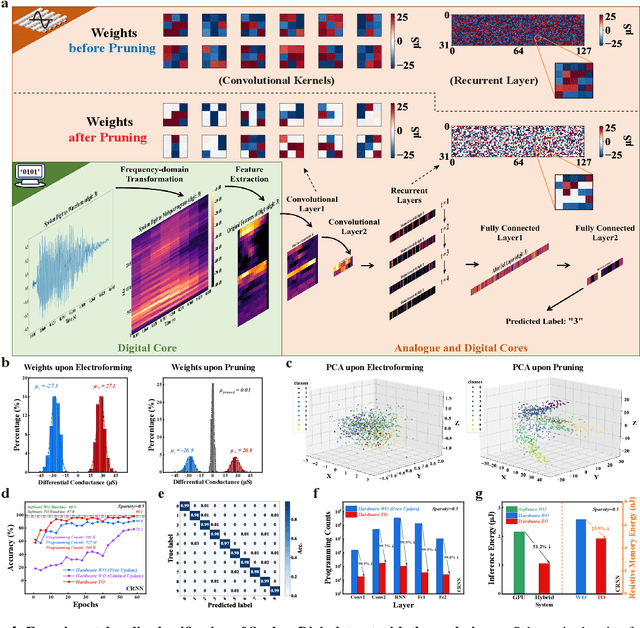
The rapid advancement of artificial intelligence (AI) has been marked by the large language models exhibiting human-like intelligence. However, these models also present unprecedented challenges to energy consumption and environmental sustainability. One promising solution is to revisit analogue computing, a technique that predates digital computing and exploits emerging analogue electronic devices, such as resistive memory, which features in-memory computing, high scalability, and nonvolatility. However, analogue computing still faces the same challenges as before: programming nonidealities and expensive programming due to the underlying devices physics. Here, we report a universal solution, software-hardware co-design using structural plasticity-inspired edge pruning to optimize the topology of a randomly weighted analogue resistive memory neural network. Software-wise, the topology of a randomly weighted neural network is optimized by pruning connections rather than precisely tuning resistive memory weights. Hardware-wise, we reveal the physical origin of the programming stochasticity using transmission electron microscopy, which is leveraged for large-scale and low-cost implementation of an overparameterized random neural network containing high-performance sub-networks. We implemented the co-design on a 40nm 256K resistive memory macro, observing 17.3% and 19.9% accuracy improvements in image and audio classification on FashionMNIST and Spoken digits datasets, as well as 9.8% (2%) improvement in PR (ROC) in image segmentation on DRIVE datasets, respectively. This is accompanied by 82.1%, 51.2%, and 99.8% improvement in energy efficiency thanks to analogue in-memory computing. By embracing the intrinsic stochasticity and in-memory computing, this work may solve the biggest obstacle of analogue computing systems and thus unleash their immense potential for next-generation AI hardware.