 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobal Universal Scaling and Ultra-Small Parameterization in Machine Learning Interatomic Potentials with Super-Linearity
Feb 11, 2025



Using machine learning (ML) to construct interatomic interactions and thus potential energy surface (PES) has become a common strategy for materials design and simulations. However, those current models of machine learning interatomic potential (MLIP) provide no relevant physical constrains, and thus may owe intrinsic out-of-domain difficulty which underlies the challenges of model generalizability and physical scalability. Here, by incorporating physics-informed Universal-Scaling law and nonlinearity-embedded interaction function, we develop a Super-linear MLIP with both Ultra-Small parameterization and greatly expanded expressive capability, named SUS2-MLIP. Due to the global scaling rooting in universal equation of state (UEOS), SUS2-MLIP not only has significantly-reduced parameters by decoupling the element space from coordinate space, but also naturally outcomes the out-of-domain difficulty and endows the potentials with inherent generalizability and scalability even with relatively small training dataset. The nonlinearity-enbeding transformation for interaction function expands the expressive capability and make the potentials super-linear. The SUS2-MLIP outperforms the state-of-the-art MLIP models with its exceptional computational efficiency especially for multiple-element materials and physical scalability in property prediction. This work not only presents a highly-efficient universal MLIP model but also sheds light on incorporating physical constraints into artificial-intelligence-aided materials simulation.
Dynamic neural network with memristive CIM and CAM for 2D and 3D vision
Jul 12, 2024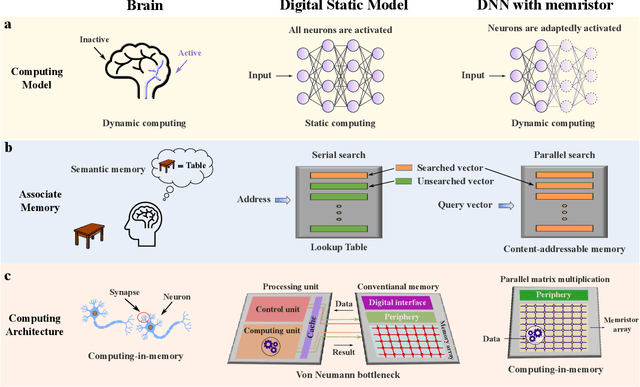
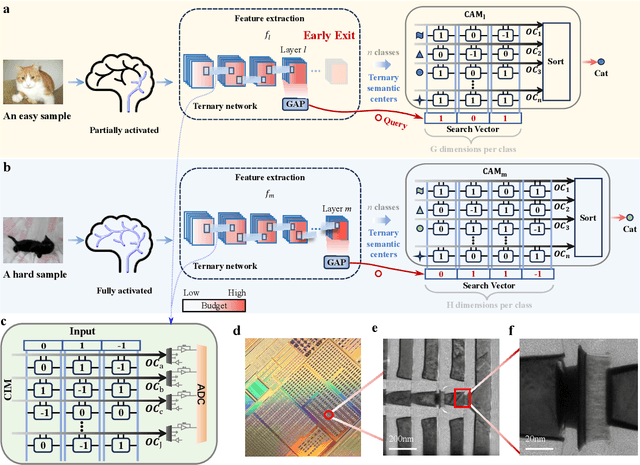
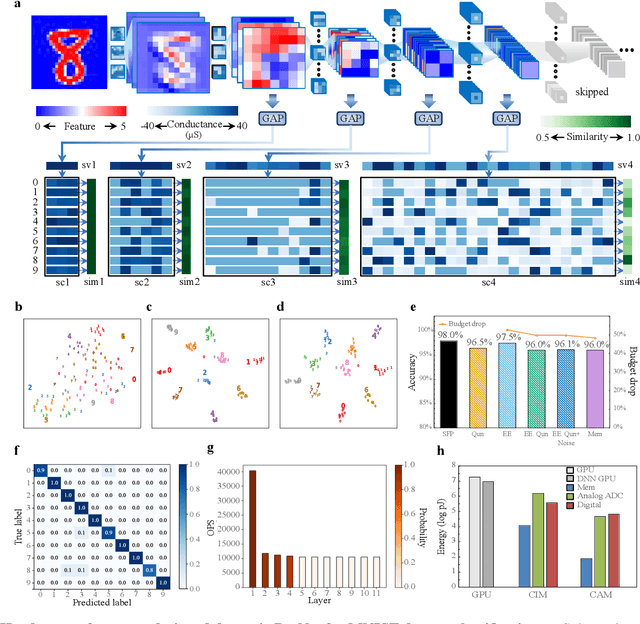
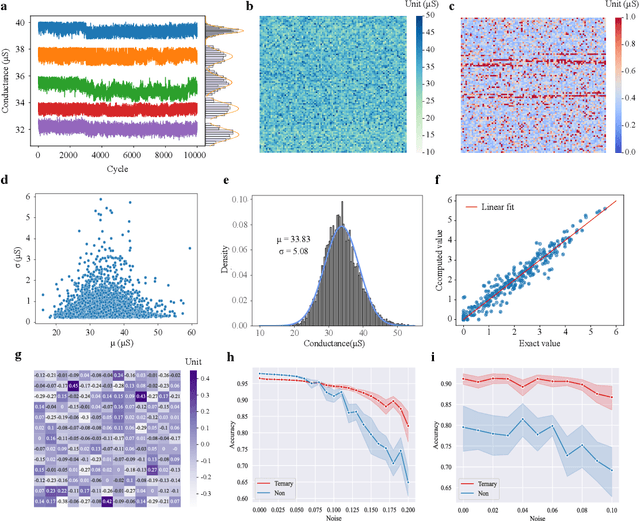
The brain is dynamic, associative and efficient. It reconfigures by associating the inputs with past experiences, with fused memory and processing. In contrast, AI models are static, unable to associate inputs with past experiences, and run on digital computers with physically separated memory and processing. We propose a hardware-software co-design, a semantic memory-based dynamic neural network (DNN) using memristor. The network associates incoming data with the past experience stored as semantic vectors. The network and the semantic memory are physically implemented on noise-robust ternary memristor-based Computing-In-Memory (CIM) and Content-Addressable Memory (CAM) circuits, respectively. We validate our co-designs, using a 40nm memristor macro, on ResNet and PointNet++ for classifying images and 3D points from the MNIST and ModelNet datasets, which not only achieves accuracy on par with software but also a 48.1% and 15.9% reduction in computational budget. Moreover, it delivers a 77.6% and 93.3% reduction in energy consumption.
Resistive Memory-based Neural Differential Equation Solver for Score-based Diffusion Model
Apr 08, 2024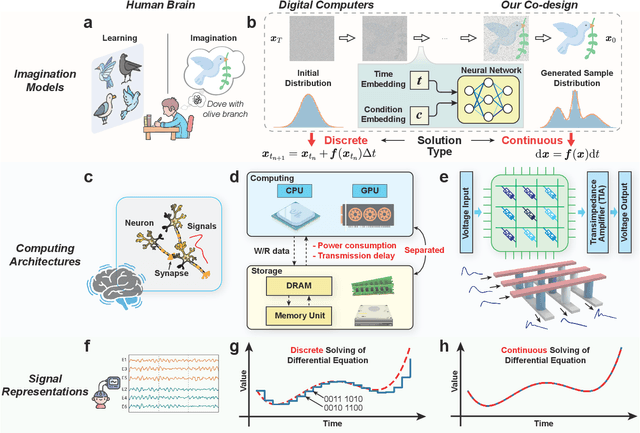
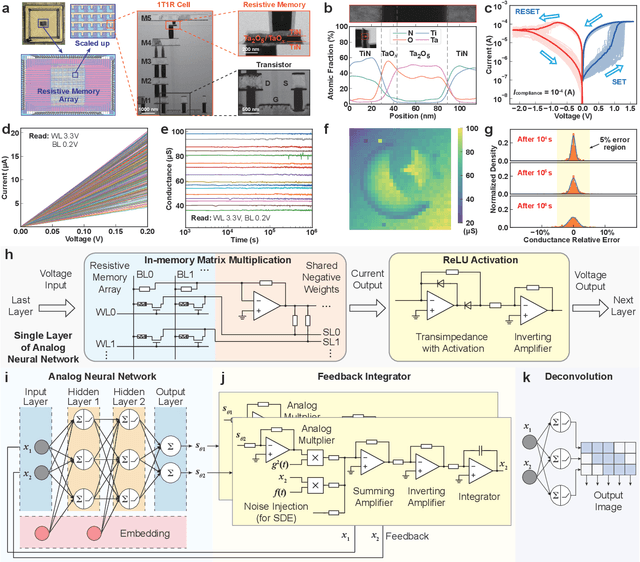
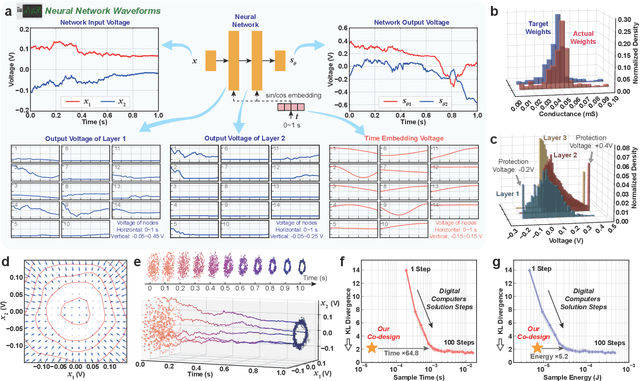
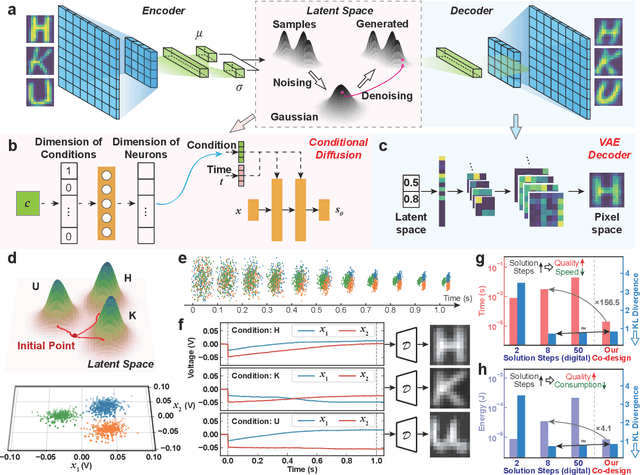
Human brains image complicated scenes when reading a novel. Replicating this imagination is one of the ultimate goals of AI-Generated Content (AIGC). However, current AIGC methods, such as score-based diffusion, are still deficient in terms of rapidity and efficiency. This deficiency is rooted in the difference between the brain and digital computers. Digital computers have physically separated storage and processing units, resulting in frequent data transfers during iterative calculations, incurring large time and energy overheads. This issue is further intensified by the conversion of inherently continuous and analog generation dynamics, which can be formulated by neural differential equations, into discrete and digital operations. Inspired by the brain, we propose a time-continuous and analog in-memory neural differential equation solver for score-based diffusion, employing emerging resistive memory. The integration of storage and computation within resistive memory synapses surmount the von Neumann bottleneck, benefiting the generative speed and energy efficiency. The closed-loop feedback integrator is time-continuous, analog, and compact, physically implementing an infinite-depth neural network. Moreover, the software-hardware co-design is intrinsically robust to analog noise. We experimentally validate our solution with 180 nm resistive memory in-memory computing macros. Demonstrating equivalent generative quality to the software baseline, our system achieved remarkable enhancements in generative speed for both unconditional and conditional generation tasks, by factors of 64.8 and 156.5, respectively. Moreover, it accomplished reductions in energy consumption by factors of 5.2 and 4.1. Our approach heralds a new horizon for hardware solutions in edge computing for generative AI applications.
Random resistive memory-based deep extreme point learning machine for unified visual processing
Dec 14, 2023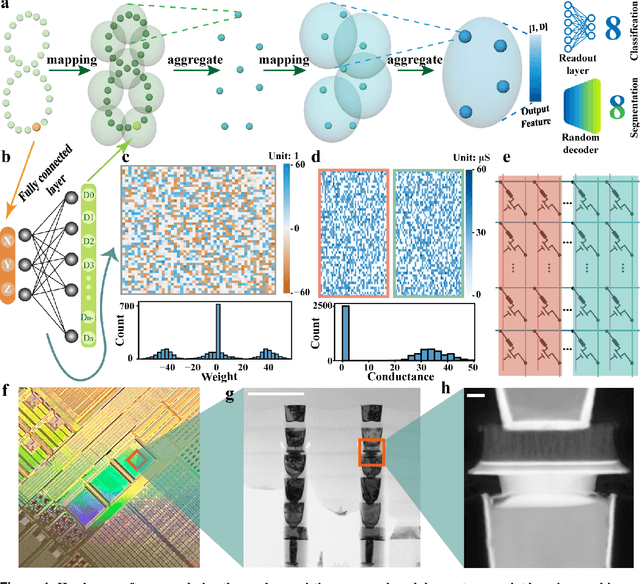
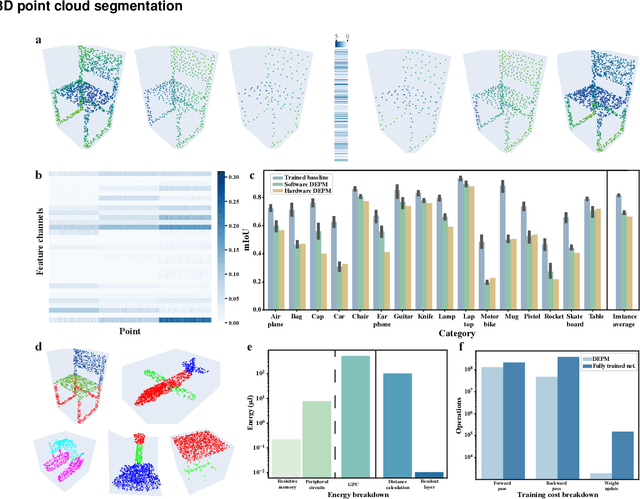
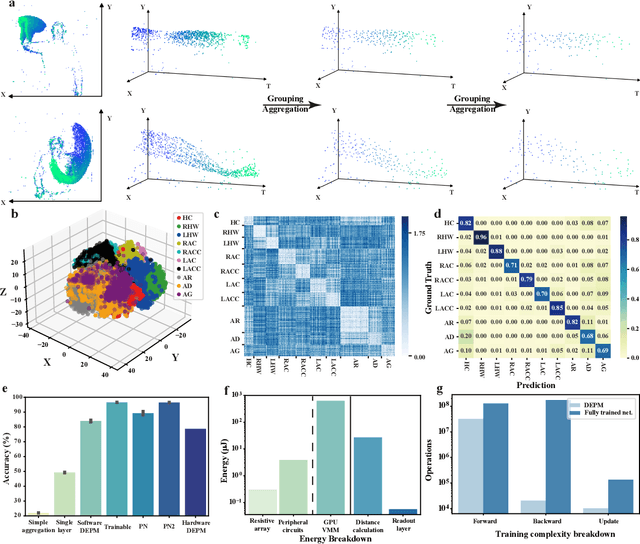
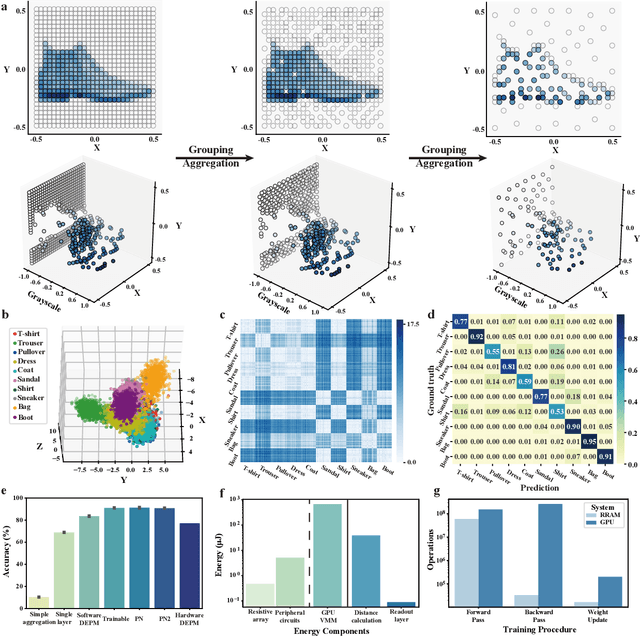
Visual sensors, including 3D LiDAR, neuromorphic DVS sensors, and conventional frame cameras, are increasingly integrated into edge-side intelligent machines. Realizing intensive multi-sensory data analysis directly on edge intelligent machines is crucial for numerous emerging edge applications, such as augmented and virtual reality and unmanned aerial vehicles, which necessitates unified data representation, unprecedented hardware energy efficiency and rapid model training. However, multi-sensory data are intrinsically heterogeneous, causing significant complexity in the system development for edge-side intelligent machines. In addition, the performance of conventional digital hardware is limited by the physically separated processing and memory units, known as the von Neumann bottleneck, and the physical limit of transistor scaling, which contributes to the slowdown of Moore's law. These limitations are further intensified by the tedious training of models with ever-increasing sizes. We propose a novel hardware-software co-design, random resistive memory-based deep extreme point learning machine (DEPLM), that offers efficient unified point set analysis. We show the system's versatility across various data modalities and two different learning tasks. Compared to a conventional digital hardware-based system, our co-design system achieves huge energy efficiency improvements and training cost reduction when compared to conventional systems. Our random resistive memory-based deep extreme point learning machine may pave the way for energy-efficient and training-friendly edge AI across various data modalities and tasks.
Pruning random resistive memory for optimizing analogue AI
Nov 13, 2023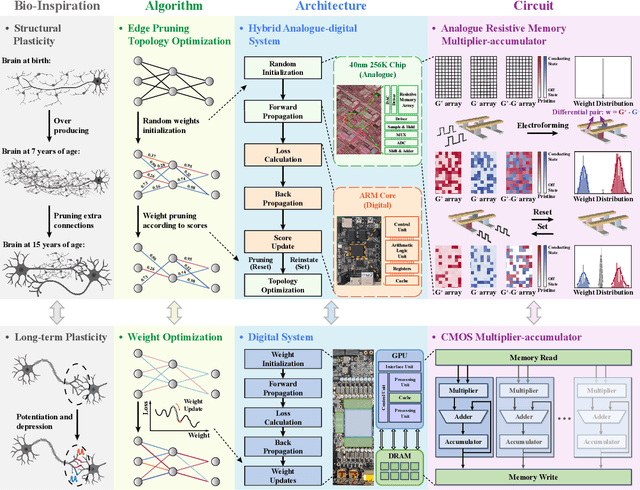
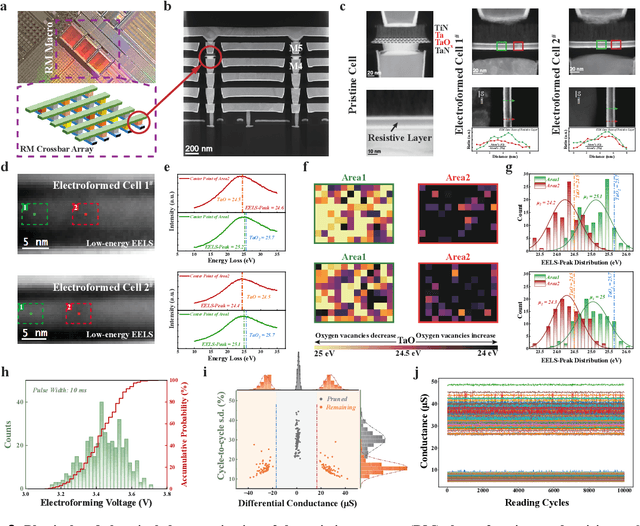
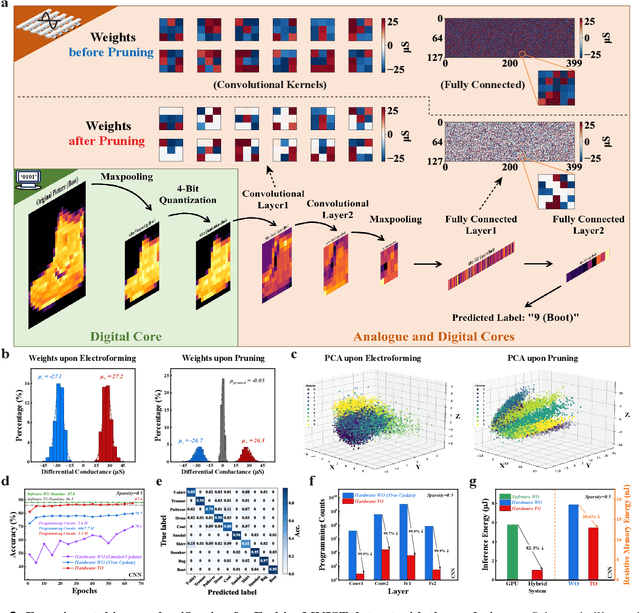
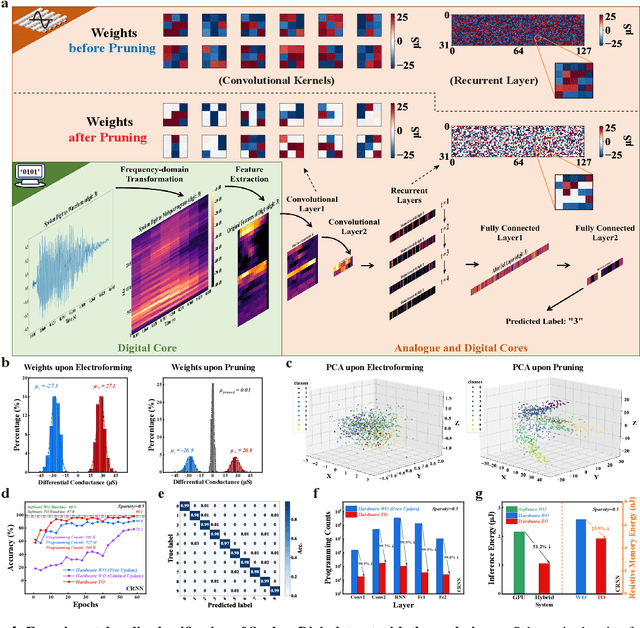
The rapid advancement of artificial intelligence (AI) has been marked by the large language models exhibiting human-like intelligence. However, these models also present unprecedented challenges to energy consumption and environmental sustainability. One promising solution is to revisit analogue computing, a technique that predates digital computing and exploits emerging analogue electronic devices, such as resistive memory, which features in-memory computing, high scalability, and nonvolatility. However, analogue computing still faces the same challenges as before: programming nonidealities and expensive programming due to the underlying devices physics. Here, we report a universal solution, software-hardware co-design using structural plasticity-inspired edge pruning to optimize the topology of a randomly weighted analogue resistive memory neural network. Software-wise, the topology of a randomly weighted neural network is optimized by pruning connections rather than precisely tuning resistive memory weights. Hardware-wise, we reveal the physical origin of the programming stochasticity using transmission electron microscopy, which is leveraged for large-scale and low-cost implementation of an overparameterized random neural network containing high-performance sub-networks. We implemented the co-design on a 40nm 256K resistive memory macro, observing 17.3% and 19.9% accuracy improvements in image and audio classification on FashionMNIST and Spoken digits datasets, as well as 9.8% (2%) improvement in PR (ROC) in image segmentation on DRIVE datasets, respectively. This is accompanied by 82.1%, 51.2%, and 99.8% improvement in energy efficiency thanks to analogue in-memory computing. By embracing the intrinsic stochasticity and in-memory computing, this work may solve the biggest obstacle of analogue computing systems and thus unleash their immense potential for next-generation AI hardware.
Binary stochasticity enabled highly efficient neuromorphic deep learning achieves better-than-software accuracy
Apr 25, 2023Deep learning needs high-precision handling of forwarding signals, backpropagating errors, and updating weights. This is inherently required by the learning algorithm since the gradient descent learning rule relies on the chain product of partial derivatives. However, it is challenging to implement deep learning in hardware systems that use noisy analog memristors as artificial synapses, as well as not being biologically plausible. Memristor-based implementations generally result in an excessive cost of neuronal circuits and stringent demands for idealized synaptic devices. Here, we demonstrate that the requirement for high precision is not necessary and that more efficient deep learning can be achieved when this requirement is lifted. We propose a binary stochastic learning algorithm that modifies all elementary neural network operations, by introducing (i) stochastic binarization of both the forwarding signals and the activation function derivatives, (ii) signed binarization of the backpropagating errors, and (iii) step-wised weight updates. Through an extensive hybrid approach of software simulation and hardware experiments, we find that binary stochastic deep learning systems can provide better performance than the software-based benchmarks using the high-precision learning algorithm. Also, the binary stochastic algorithm strongly simplifies the neural network operations in hardware, resulting in an improvement of the energy efficiency for the multiply-and-accumulate operations by more than three orders of magnitudes.
Efficient Training of the Memristive Deep Belief Net Immune to Non-Idealities of the Synaptic Devices
Mar 15, 2022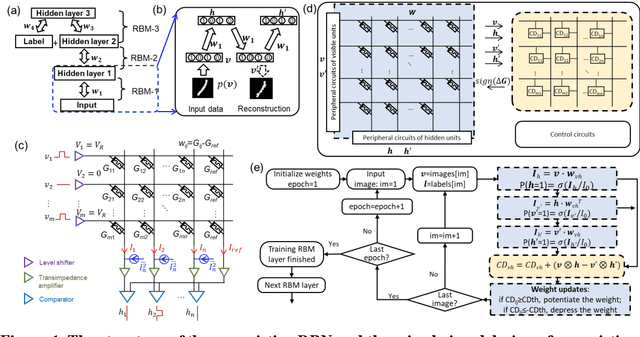
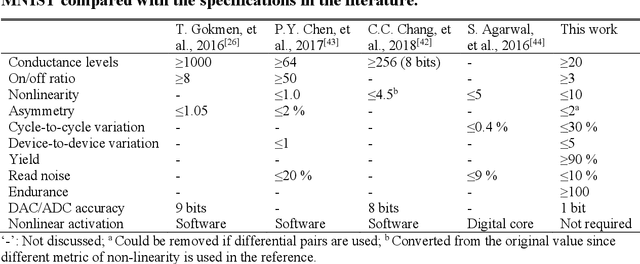
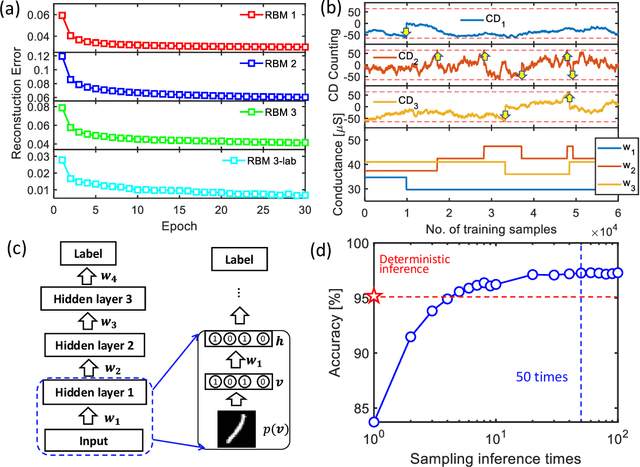
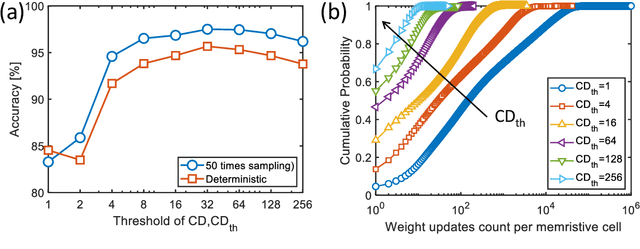
The tunability of conductance states of various emerging non-volatile memristive devices emulates the plasticity of biological synapses, making it promising in the hardware realization of large-scale neuromorphic systems. The inference of the neural network can be greatly accelerated by the vector-matrix multiplication (VMM) performed within a crossbar array of memristive devices in one step. Nevertheless, the implementation of the VMM needs complex peripheral circuits and the complexity further increases since non-idealities of memristive devices prevent precise conductance tuning (especially for the online training) and largely degrade the performance of the deep neural networks (DNNs). Here, we present an efficient online training method of the memristive deep belief net (DBN). The proposed memristive DBN uses stochastically binarized activations, reducing the complexity of peripheral circuits, and uses the contrastive divergence (CD) based gradient descent learning algorithm. The analog VMM and digital CD are performed separately in a mixed-signal hardware arrangement, making the memristive DBN high immune to non-idealities of synaptic devices. The number of write operations on memristive devices is reduced by two orders of magnitude. The recognition accuracy of 95%~97% can be achieved for the MNIST dataset using pulsed synaptic behaviors of various memristive synaptic devices.