 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Effective and General Graph Unlearning via Mutual Evolution
Jan 22, 2024
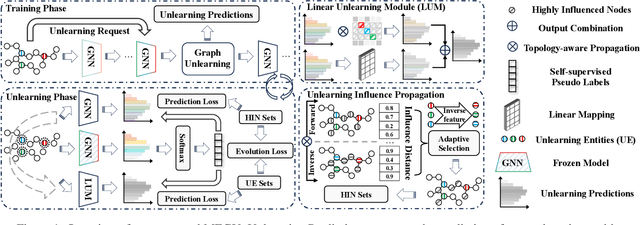

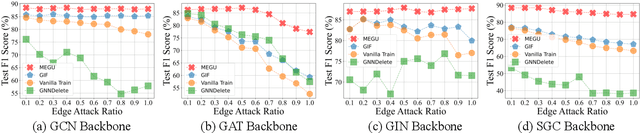
With the rapid advancement of AI applications, the growing needs for data privacy and model robustness have highlighted the importance of machine unlearning, especially in thriving graph-based scenarios. However, most existing graph unlearning strategies primarily rely on well-designed architectures or manual process, rendering them less user-friendly and posing challenges in terms of deployment efficiency. Furthermore, striking a balance between unlearning performance and framework generalization is also a pivotal concern. To address the above issues, we propose \underline{\textbf{M}}utual \underline{\textbf{E}}volution \underline{\textbf{G}}raph \underline{\textbf{U}}nlearning (MEGU), a new mutual evolution paradigm that simultaneously evolves the predictive and unlearning capacities of graph unlearning. By incorporating aforementioned two components, MEGU ensures complementary optimization in a unified training framework that aligns with the prediction and unlearning requirements. Extensive experiments on 9 graph benchmark datasets demonstrate the superior performance of MEGU in addressing unlearning requirements at the feature, node, and edge levels. Specifically, MEGU achieves average performance improvements of 2.7\%, 2.5\%, and 3.2\% across these three levels of unlearning tasks when compared to state-of-the-art baselines. Furthermore, MEGU exhibits satisfactory training efficiency, reducing time and space overhead by an average of 159.8x and 9.6x, respectively, in comparison to retraining GNN from scratch.
Efficient Training of the Memristive Deep Belief Net Immune to Non-Idealities of the Synaptic Devices
Mar 15, 2022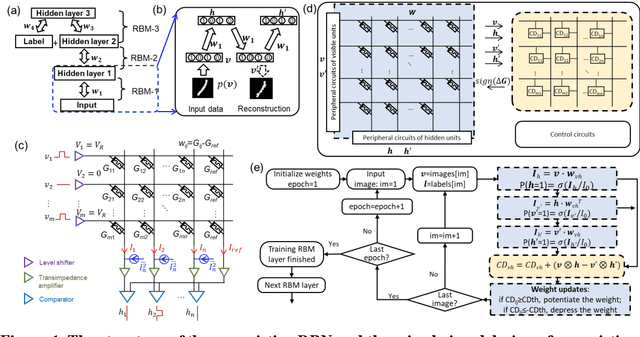
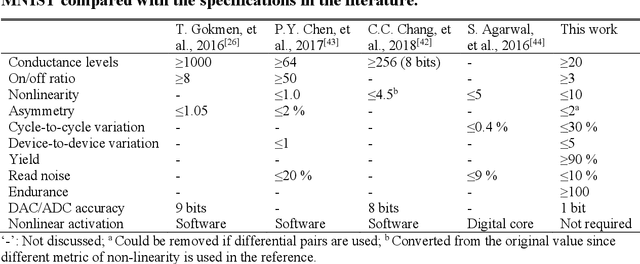
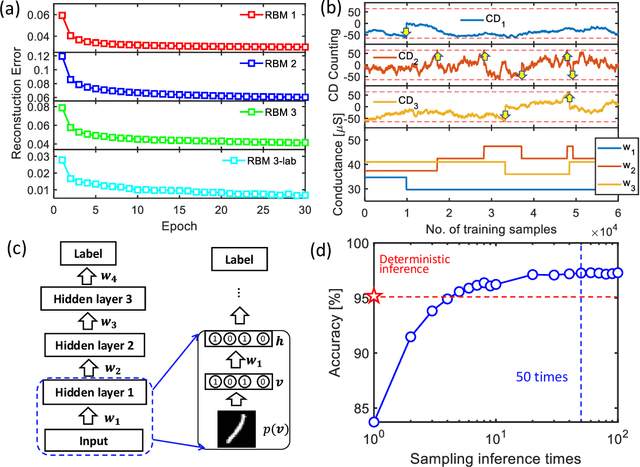
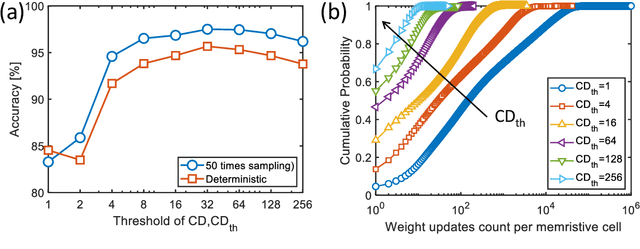
The tunability of conductance states of various emerging non-volatile memristive devices emulates the plasticity of biological synapses, making it promising in the hardware realization of large-scale neuromorphic systems. The inference of the neural network can be greatly accelerated by the vector-matrix multiplication (VMM) performed within a crossbar array of memristive devices in one step. Nevertheless, the implementation of the VMM needs complex peripheral circuits and the complexity further increases since non-idealities of memristive devices prevent precise conductance tuning (especially for the online training) and largely degrade the performance of the deep neural networks (DNNs). Here, we present an efficient online training method of the memristive deep belief net (DBN). The proposed memristive DBN uses stochastically binarized activations, reducing the complexity of peripheral circuits, and uses the contrastive divergence (CD) based gradient descent learning algorithm. The analog VMM and digital CD are performed separately in a mixed-signal hardware arrangement, making the memristive DBN high immune to non-idealities of synaptic devices. The number of write operations on memristive devices is reduced by two orders of magnitude. The recognition accuracy of 95%~97% can be achieved for the MNIST dataset using pulsed synaptic behaviors of various memristive synaptic devices.