 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Deep Semantic Segmentation Network with Semantic and Contextual Refinements
Dec 11, 2024



Semantic segmentation is a fundamental task in multimedia processing, which can be used for analyzing, understanding, editing contents of images and videos, among others. To accelerate the analysis of multimedia data, existing segmentation researches tend to extract semantic information by progressively reducing the spatial resolutions of feature maps. However, this approach introduces a misalignment problem when restoring the resolution of high-level feature maps. In this paper, we design a Semantic Refinement Module (SRM) to address this issue within the segmentation network. Specifically, SRM is designed to learn a transformation offset for each pixel in the upsampled feature maps, guided by high-resolution feature maps and neighboring offsets. By applying these offsets to the upsampled feature maps, SRM enhances the semantic representation of the segmentation network, particularly for pixels around object boundaries. Furthermore, a Contextual Refinement Module (CRM) is presented to capture global context information across both spatial and channel dimensions. To balance dimensions between channel and space, we aggregate the semantic maps from all four stages of the backbone to enrich channel context information. The efficacy of these proposed modules is validated on three widely used datasets-Cityscapes, Bdd100K, and ADE20K-demonstrating superior performance compared to state-of-the-art methods. Additionally, this paper extends these modules to a lightweight segmentation network, achieving an mIoU of 82.5% on the Cityscapes validation set with only 137.9 GFLOPs.
UIFormer: A Unified Transformer-based Framework for Incremental Few-Shot Object Detection and Instance Segmentation
Nov 13, 2024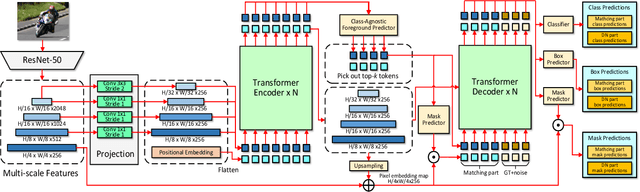



This paper introduces a novel framework for unified incremental few-shot object detection (iFSOD) and instance segmentation (iFSIS) using the Transformer architecture. Our goal is to create an optimal solution for situations where only a few examples of novel object classes are available, with no access to training data for base or old classes, while maintaining high performance across both base and novel classes. To achieve this, We extend Mask-DINO into a two-stage incremental learning framework. Stage 1 focuses on optimizing the model using the base dataset, while Stage 2 involves fine-tuning the model on novel classes. Besides, we incorporate a classifier selection strategy that assigns appropriate classifiers to the encoder and decoder according to their distinct functions. Empirical evidence indicates that this approach effectively mitigates the over-fitting on novel classes learning. Furthermore, we implement knowledge distillation to prevent catastrophic forgetting of base classes. Comprehensive evaluations on the COCO and LVIS datasets for both iFSIS and iFSOD tasks demonstrate that our method significantly outperforms state-of-the-art approaches.
Blended Latent Diffusion under Attention Control for Real-World Video Editing
Sep 05, 2024


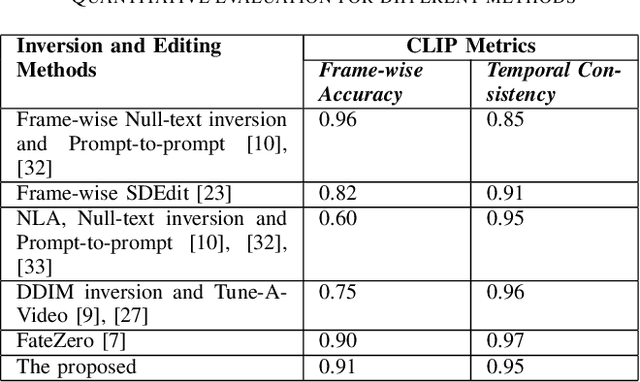
Due to lack of fully publicly available text-to-video models, current video editing methods tend to build on pre-trained text-to-image generation models, however, they still face grand challenges in dealing with the local editing of video with temporal information. First, although existing methods attempt to focus on local area editing by a pre-defined mask, the preservation of the outside-area background is non-ideal due to the spatially entire generation of each frame. In addition, specially providing a mask by user is an additional costly undertaking, so an autonomous masking strategy integrated into the editing process is desirable. Last but not least, image-level pretrained model hasn't learned temporal information across frames of a video which is vital for expressing the motion and dynamics. In this paper, we propose to adapt a image-level blended latent diffusion model to perform local video editing tasks. Specifically, we leverage DDIM inversion to acquire the latents as background latents instead of the randomly noised ones to better preserve the background information of the input video. We further introduce an autonomous mask manufacture mechanism derived from cross-attention maps in diffusion steps. Finally, we enhance the temporal consistency across video frames by transforming the self-attention blocks of U-Net into temporal-spatial blocks. Through extensive experiments, our proposed approach demonstrates effectiveness in different real-world video editing tasks.
Towards Efficient Pixel Labeling for Industrial Anomaly Detection and Localization
Jul 03, 2024



In the realm of practical Anomaly Detection (AD) tasks, manual labeling of anomalous pixels proves to be a costly endeavor. Consequently, many AD methods are crafted as one-class classifiers, tailored for training sets completely devoid of anomalies, ensuring a more cost-effective approach. While some pioneering work has demonstrated heightened AD accuracy by incorporating real anomaly samples in training, this enhancement comes at the price of labor-intensive labeling processes. This paper strikes the balance between AD accuracy and labeling expenses by introducing ADClick, a novel Interactive Image Segmentation (IIS) algorithm. ADClick efficiently generates "ground-truth" anomaly masks for real defective images, leveraging innovative residual features and meticulously crafted language prompts. Notably, ADClick showcases a significantly elevated generalization capacity compared to existing state-of-the-art IIS approaches. Functioning as an anomaly labeling tool, ADClick generates high-quality anomaly labels (AP $= 94.1\%$ on MVTec AD) based on only $3$ to $5$ manual click annotations per training image. Furthermore, we extend the capabilities of ADClick into ADClick-Seg, an enhanced model designed for anomaly detection and localization. By fine-tuning the ADClick-Seg model using the weak labels inferred by ADClick, we establish the state-of-the-art performances in supervised AD tasks (AP $= 86.4\%$ on MVTec AD and AP $= 78.4\%$, PRO $= 98.6\%$ on KSDD2).
A Novel Approach to Industrial Defect Generation through Blended Latent Diffusion Model with Online Adaptation
Feb 29, 2024

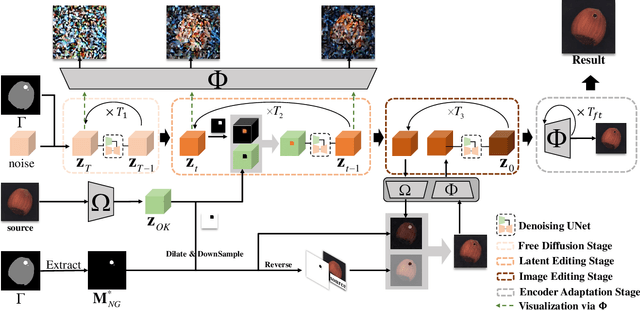

Effectively addressing the challenge of industrial Anomaly Detection (AD) necessitates an ample supply of defective samples, a constraint often hindered by their scarcity in industrial contexts. This paper introduces a novel algorithm designed to augment defective samples, thereby enhancing AD performance. The proposed method tailors the blended latent diffusion model for defect sample generation, employing a diffusion model to generate defective samples in the latent space. A feature editing process, controlled by a "trimap" mask and text prompts, refines the generated samples. The image generation inference process is structured into three stages: a free diffusion stage, an editing diffusion stage, and an online decoder adaptation stage. This sophisticated inference strategy yields high-quality synthetic defective samples with diverse pattern variations, leading to significantly improved AD accuracies based on the augmented training set. Specifically, on the widely recognized MVTec AD dataset, the proposed method elevates the state-of-the-art (SOTA) performance of AD with augmented data by 1.5%, 1.9%, and 3.1% for AD metrics AP, IAP, and IAP90, respectively. The implementation code of this work can be found at the GitHub repository https://github.com/GrandpaXun242/AdaBLDM.git
LipFormer: Learning to Lipread Unseen Speakers based on Visual-Landmark Transformers
Feb 04, 2023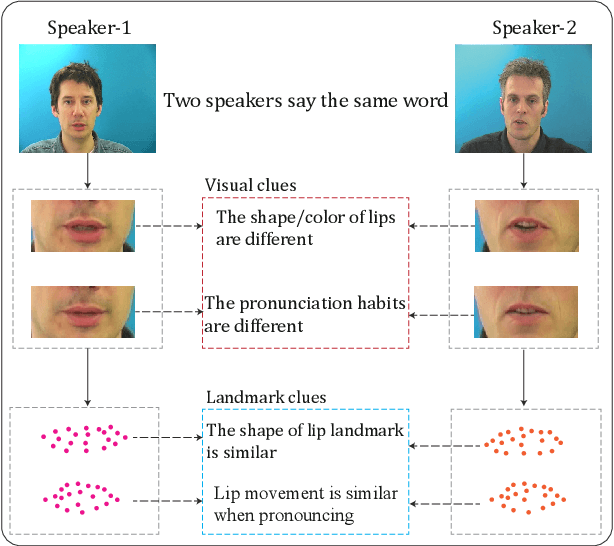



Lipreading refers to understanding and further translating the speech of a speaker in the video into natural language. State-of-the-art lipreading methods excel in interpreting overlap speakers, i.e., speakers appear in both training and inference sets. However, generalizing these methods to unseen speakers incurs catastrophic performance degradation due to the limited number of speakers in training bank and the evident visual variations caused by the shape/color of lips for different speakers. Therefore, merely depending on the visible changes of lips tends to cause model overfitting. To address this problem, we propose to use multi-modal features across visual and landmarks, which can describe the lip motion irrespective to the speaker identities. Then, we develop a sentence-level lipreading framework based on visual-landmark transformers, namely LipFormer. Specifically, LipFormer consists of a lip motion stream, a facial landmark stream, and a cross-modal fusion. The embeddings from the two streams are produced by self-attention, which are fed to the cross-attention module to achieve the alignment between visuals and landmarks. Finally, the resulting fused features can be decoded to output texts by a cascade seq2seq model. Experiments demonstrate that our method can effectively enhance the model generalization to unseen speakers.
Asymmetric Cross-Scale Alignment for Text-Based Person Search
Nov 26, 2022



Text-based person search (TBPS) is of significant importance in intelligent surveillance, which aims to retrieve pedestrian images with high semantic relevance to a given text description. This retrieval task is characterized with both modal heterogeneity and fine-grained matching. To implement this task, one needs to extract multi-scale features from both image and text domains, and then perform the cross-modal alignment. However, most existing approaches only consider the alignment confined at their individual scales, e.g., an image-sentence or a region-phrase scale. Such a strategy adopts the presumable alignment in feature extraction, while overlooking the cross-scale alignment, e.g., image-phrase. In this paper, we present a transformer-based model to extract multi-scale representations, and perform Asymmetric Cross-Scale Alignment (ACSA) to precisely align the two modalities. Specifically, ACSA consists of a global-level alignment module and an asymmetric cross-attention module, where the former aligns an image and texts on a global scale, and the latter applies the cross-attention mechanism to dynamically align the cross-modal entities in region/image-phrase scales. Extensive experiments on two benchmark datasets CUHK-PEDES and RSTPReid demonstrate the effectiveness of our approach. Codes are available at \href{url}{https://github.com/mul-hjh/ACSA}.
HierTrain: Fast Hierarchical Edge AI Learning with Hybrid Parallelism in Mobile-Edge-Cloud Computing
Mar 22, 2020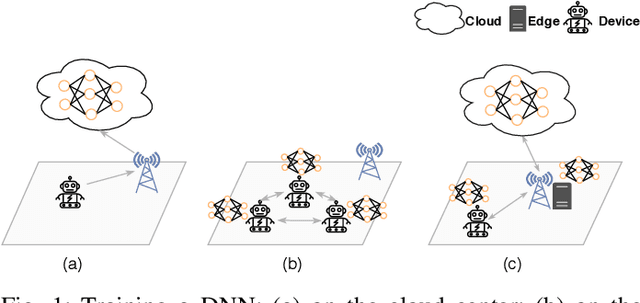
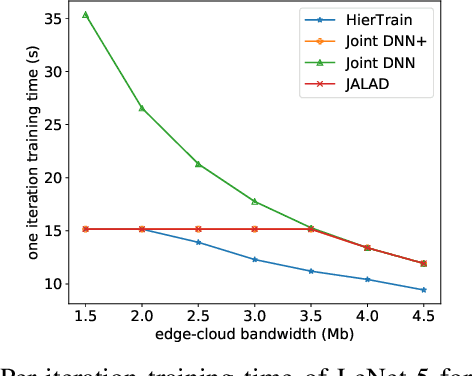
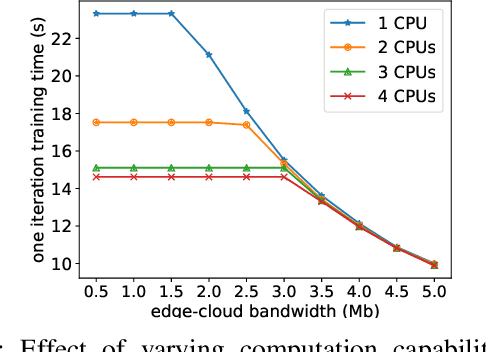
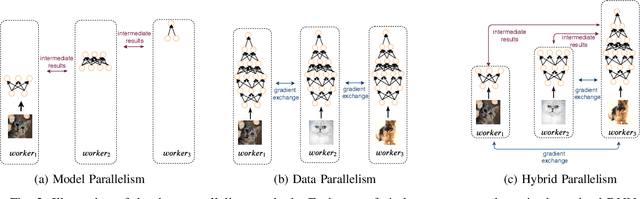
Nowadays, deep neural networks (DNNs) are the core enablers for many emerging edge AI applications. Conventional approaches to training DNNs are generally implemented at central servers or cloud centers for centralized learning, which is typically time-consuming and resource-demanding due to the transmission of a large amount of data samples from the device to the remote cloud. To overcome these disadvantages, we consider accelerating the learning process of DNNs on the Mobile-Edge-Cloud Computing (MECC) paradigm. In this paper, we propose HierTrain, a hierarchical edge AI learning framework, which efficiently deploys the DNN training task over the hierarchical MECC architecture. We develop a novel \textit{hybrid parallelism} method, which is the key to HierTrain, to adaptively assign the DNN model layers and the data samples across the three levels of edge device, edge server and cloud center. We then formulate the problem of scheduling the DNN training tasks at both layer-granularity and sample-granularity. Solving this optimization problem enables us to achieve the minimum training time. We further implement a hardware prototype consisting of an edge device, an edge server and a cloud server, and conduct extensive experiments on it. Experimental results demonstrate that HierTrain can achieve up to 6.9x speedup compared to the cloud-based hierarchical training approach.