 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Multimodal Misinformation Detection by Replaying the Whole Story from Image Modality Perspective
Nov 09, 2025
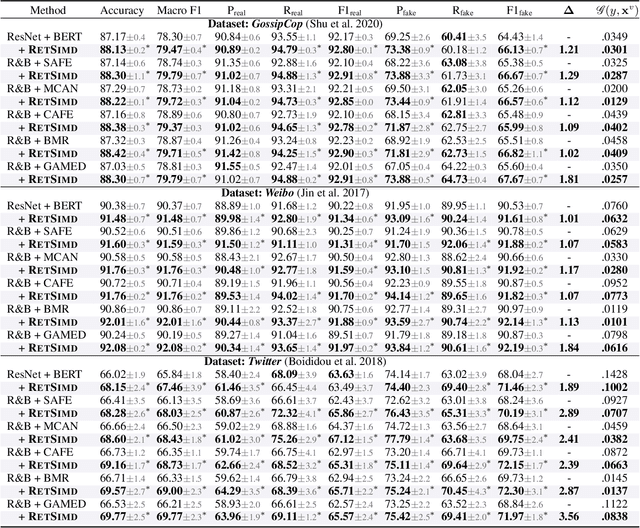
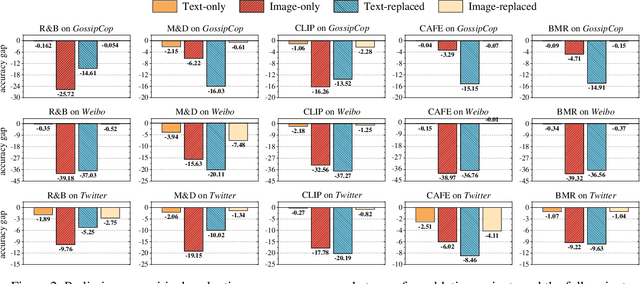
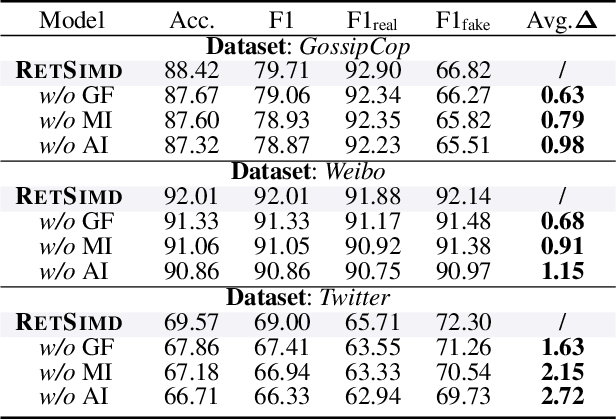
Multimodal Misinformation Detection (MMD) refers to the task of detecting social media posts involving misinformation, where the post often contains text and image modalities. However, by observing the MMD posts, we hold that the text modality may be much more informative than the image modality because the text generally describes the whole event/story of the current post but the image often presents partial scenes only. Our preliminary empirical results indicate that the image modality exactly contributes less to MMD. Upon this idea, we propose a new MMD method named RETSIMD. Specifically, we suppose that each text can be divided into several segments, and each text segment describes a partial scene that can be presented by an image. Accordingly, we split the text into a sequence of segments, and feed these segments into a pre-trained text-to-image generator to augment a sequence of images. We further incorporate two auxiliary objectives concerning text-image and image-label mutual information, and further post-train the generator over an auxiliary text-to-image generation benchmark dataset. Additionally, we propose a graph structure by defining three heuristic relationships between images, and use a graph neural network to generate the fused features. Extensive empirical results validate the effectiveness of RETSIMD.
A Novel Local Focusing Mechanism for Deepfake Detection Generalization
Aug 23, 2025The rapid advancement of deepfake generation techniques has intensified the need for robust and generalizable detection methods. Existing approaches based on reconstruction learning typically leverage deep convolutional networks to extract differential features. However, these methods show poor generalization across object categories (e.g., from faces to cars) and generation domains (e.g., from GANs to Stable Diffusion), due to intrinsic limitations of deep CNNs. First, models trained on a specific category tend to overfit to semantic feature distributions, making them less transferable to other categories, especially as network depth increases. Second, Global Average Pooling (GAP) compresses critical local forgery cues into a single vector, thus discarding discriminative patterns vital for real-fake classification. To address these issues, we propose a novel Local Focus Mechanism (LFM) that explicitly attends to discriminative local features for differentiating fake from real images. LFM integrates a Salience Network (SNet) with a task-specific Top-K Pooling (TKP) module to select the K most informative local patterns. To mitigate potential overfitting introduced by Top-K pooling, we introduce two regularization techniques: Rank-Based Linear Dropout (RBLD) and Random-K Sampling (RKS), which enhance the model's robustness. LFM achieves a 3.7 improvement in accuracy and a 2.8 increase in average precision over the state-of-the-art Neighboring Pixel Relationships (NPR) method, while maintaining exceptional efficiency at 1789 FPS on a single NVIDIA A6000 GPU. Our approach sets a new benchmark for cross-domain deepfake detection. The source code are available in https://github.com/lmlpy/LFM.git
Unlocking Generalization Power in LiDAR Point Cloud Registration
Mar 13, 2025



In real-world environments, a LiDAR point cloud registration method with robust generalization capabilities (across varying distances and datasets) is crucial for ensuring safety in autonomous driving and other LiDAR-based applications. However, current methods fall short in achieving this level of generalization. To address these limitations, we propose UGP, a pruned framework designed to enhance generalization power for LiDAR point cloud registration. The core insight in UGP is the elimination of cross-attention mechanisms to improve generalization, allowing the network to concentrate on intra-frame feature extraction. Additionally, we introduce a progressive self-attention module to reduce ambiguity in large-scale scenes and integrate Bird's Eye View (BEV) features to incorporate semantic information about scene elements. Together, these enhancements significantly boost the network's generalization performance. We validated our approach through various generalization experiments in multiple outdoor scenes. In cross-distance generalization experiments on KITTI and nuScenes, UGP achieved state-of-the-art mean Registration Recall rates of 94.5% and 91.4%, respectively. In cross-dataset generalization from nuScenes to KITTI, UGP achieved a state-of-the-art mean Registration Recall of 90.9%. Code will be available at https://github.com/peakpang/UGP.
A Deep Semantic Segmentation Network with Semantic and Contextual Refinements
Dec 11, 2024



Semantic segmentation is a fundamental task in multimedia processing, which can be used for analyzing, understanding, editing contents of images and videos, among others. To accelerate the analysis of multimedia data, existing segmentation researches tend to extract semantic information by progressively reducing the spatial resolutions of feature maps. However, this approach introduces a misalignment problem when restoring the resolution of high-level feature maps. In this paper, we design a Semantic Refinement Module (SRM) to address this issue within the segmentation network. Specifically, SRM is designed to learn a transformation offset for each pixel in the upsampled feature maps, guided by high-resolution feature maps and neighboring offsets. By applying these offsets to the upsampled feature maps, SRM enhances the semantic representation of the segmentation network, particularly for pixels around object boundaries. Furthermore, a Contextual Refinement Module (CRM) is presented to capture global context information across both spatial and channel dimensions. To balance dimensions between channel and space, we aggregate the semantic maps from all four stages of the backbone to enrich channel context information. The efficacy of these proposed modules is validated on three widely used datasets-Cityscapes, Bdd100K, and ADE20K-demonstrating superior performance compared to state-of-the-art methods. Additionally, this paper extends these modules to a lightweight segmentation network, achieving an mIoU of 82.5% on the Cityscapes validation set with only 137.9 GFLOPs.
Pruning All-Rounder: Rethinking and Improving Inference Efficiency for Large Vision Language Models
Dec 09, 2024



Although Large Vision-Language Models (LVLMs) have achieved impressive results, their high computational cost poses a significant barrier to wider application. To enhance inference efficiency, most existing approaches depend on parameter-dependent or token-dependent strategies to reduce computational demands. However, these methods typically require complex training processes and struggle to consistently select the most relevant tokens. In this paper, we systematically analyze the above challenges and provide a series of valuable insights for inference acceleration. Based on these findings, we propose a novel framework, the Pruning All-Rounder (PAR). Different from previous works, PAR develops a meta-router to adaptively organize pruning flows across both tokens and layers. With a self-supervised learning manner, our method achieves a superior balance between performance and efficiency. Notably, PAR is highly flexible, offering multiple pruning versions to address a range of pruning scenarios. The code for this work will be made publicly available.
Blended Latent Diffusion under Attention Control for Real-World Video Editing
Sep 05, 2024


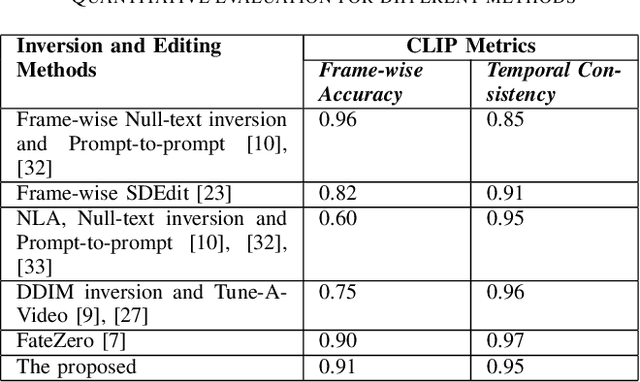
Due to lack of fully publicly available text-to-video models, current video editing methods tend to build on pre-trained text-to-image generation models, however, they still face grand challenges in dealing with the local editing of video with temporal information. First, although existing methods attempt to focus on local area editing by a pre-defined mask, the preservation of the outside-area background is non-ideal due to the spatially entire generation of each frame. In addition, specially providing a mask by user is an additional costly undertaking, so an autonomous masking strategy integrated into the editing process is desirable. Last but not least, image-level pretrained model hasn't learned temporal information across frames of a video which is vital for expressing the motion and dynamics. In this paper, we propose to adapt a image-level blended latent diffusion model to perform local video editing tasks. Specifically, we leverage DDIM inversion to acquire the latents as background latents instead of the randomly noised ones to better preserve the background information of the input video. We further introduce an autonomous mask manufacture mechanism derived from cross-attention maps in diffusion steps. Finally, we enhance the temporal consistency across video frames by transforming the self-attention blocks of U-Net into temporal-spatial blocks. Through extensive experiments, our proposed approach demonstrates effectiveness in different real-world video editing tasks.
Boosting Box-supervised Instance Segmentation with Pseudo Depth
Mar 02, 2024The realm of Weakly Supervised Instance Segmentation (WSIS) under box supervision has garnered substantial attention, showcasing remarkable advancements in recent years. However, the limitations of box supervision become apparent in its inability to furnish effective information for distinguishing foreground from background within the specified target box. This research addresses this challenge by introducing pseudo-depth maps into the training process of the instance segmentation network, thereby boosting its performance by capturing depth differences between instances. These pseudo-depth maps are generated using a readily available depth predictor and are not necessary during the inference stage. To enable the network to discern depth features when predicting masks, we integrate a depth prediction layer into the mask prediction head. This innovative approach empowers the network to simultaneously predict masks and depth, enhancing its ability to capture nuanced depth-related information during the instance segmentation process. We further utilize the mask generated in the training process as supervision to distinguish the foreground from the background. When selecting the best mask for each box through the Hungarian algorithm, we use depth consistency as one calculation cost item. The proposed method achieves significant improvements on Cityscapes and COCO dataset.
De novo protein design using geometric vector field networks
Oct 18, 2023



Innovations like protein diffusion have enabled significant progress in de novo protein design, which is a vital topic in life science. These methods typically depend on protein structure encoders to model residue backbone frames, where atoms do not exist. Most prior encoders rely on atom-wise features, such as angles and distances between atoms, which are not available in this context. Thus far, only several simple encoders, such as IPA, have been proposed for this scenario, exposing the frame modeling as a bottleneck. In this work, we proffer the Vector Field Network (VFN), which enables network layers to perform learnable vector computations between coordinates of frame-anchored virtual atoms, thus achieving a higher capability for modeling frames. The vector computation operates in a manner similar to a linear layer, with each input channel receiving 3D virtual atom coordinates instead of scalar values. The multiple feature vectors output by the vector computation are then used to update the residue representations and virtual atom coordinates via attention aggregation. Remarkably, VFN also excels in modeling both frames and atoms, as the real atoms can be treated as the virtual atoms for modeling, positioning VFN as a potential universal encoder. In protein diffusion (frame modeling), VFN exhibits an impressive performance advantage over IPA, excelling in terms of both designability (67.04% vs. 53.58%) and diversity (66.54% vs. 51.98%). In inverse folding (frame and atom modeling), VFN outperforms the previous SoTA model, PiFold (54.7% vs. 51.66%), on sequence recovery rate. We also propose a method of equipping VFN with the ESM model, which significantly surpasses the previous ESM-based SoTA (62.67% vs. 55.65%), LM-Design, by a substantial margin.
CTVIS: Consistent Training for Online Video Instance Segmentation
Jul 24, 2023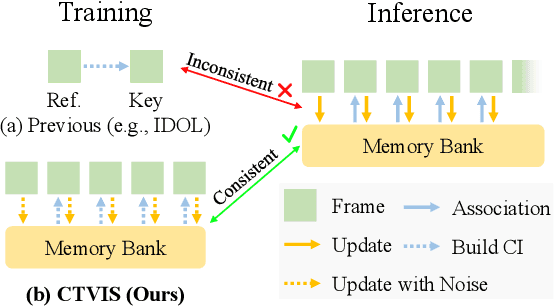
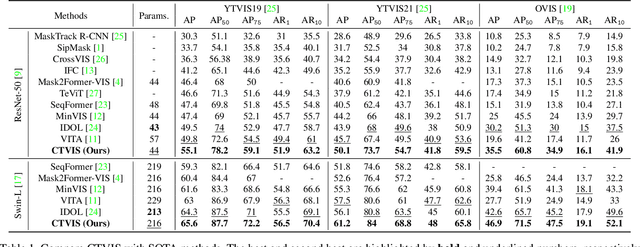
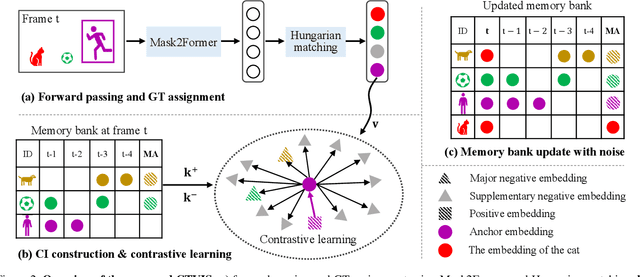
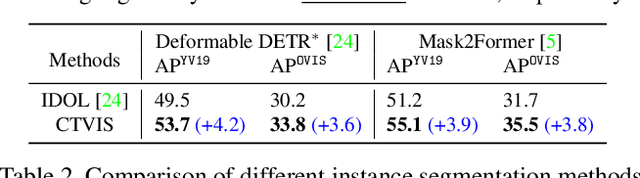
The discrimination of instance embeddings plays a vital role in associating instances across time for online video instance segmentation (VIS). Instance embedding learning is directly supervised by the contrastive loss computed upon the contrastive items (CIs), which are sets of anchor/positive/negative embeddings. Recent online VIS methods leverage CIs sourced from one reference frame only, which we argue is insufficient for learning highly discriminative embeddings. Intuitively, a possible strategy to enhance CIs is replicating the inference phase during training. To this end, we propose a simple yet effective training strategy, called Consistent Training for Online VIS (CTVIS), which devotes to aligning the training and inference pipelines in terms of building CIs. Specifically, CTVIS constructs CIs by referring inference the momentum-averaged embedding and the memory bank storage mechanisms, and adding noise to the relevant embeddings. Such an extension allows a reliable comparison between embeddings of current instances and the stable representations of historical instances, thereby conferring an advantage in modeling VIS challenges such as occlusion, re-identification, and deformation. Empirically, CTVIS outstrips the SOTA VIS models by up to +5.0 points on three VIS benchmarks, including YTVIS19 (55.1% AP), YTVIS21 (50.1% AP) and OVIS (35.5% AP). Furthermore, we find that pseudo-videos transformed from images can train robust models surpassing fully-supervised ones.
Asymmetric Cross-Scale Alignment for Text-Based Person Search
Nov 26, 2022



Text-based person search (TBPS) is of significant importance in intelligent surveillance, which aims to retrieve pedestrian images with high semantic relevance to a given text description. This retrieval task is characterized with both modal heterogeneity and fine-grained matching. To implement this task, one needs to extract multi-scale features from both image and text domains, and then perform the cross-modal alignment. However, most existing approaches only consider the alignment confined at their individual scales, e.g., an image-sentence or a region-phrase scale. Such a strategy adopts the presumable alignment in feature extraction, while overlooking the cross-scale alignment, e.g., image-phrase. In this paper, we present a transformer-based model to extract multi-scale representations, and perform Asymmetric Cross-Scale Alignment (ACSA) to precisely align the two modalities. Specifically, ACSA consists of a global-level alignment module and an asymmetric cross-attention module, where the former aligns an image and texts on a global scale, and the latter applies the cross-attention mechanism to dynamically align the cross-modal entities in region/image-phrase scales. Extensive experiments on two benchmark datasets CUHK-PEDES and RSTPReid demonstrate the effectiveness of our approach. Codes are available at \href{url}{https://github.com/mul-hjh/ACSA}.