 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHallucination-aware intermediate representation edit in large vision-language models
Mar 31, 2026Large Vision-Language Models have demonstrated exceptional performance in multimodal reasoning and complex scene understanding. However, these models still face significant hallucination issues, where outputs contradict visual facts. Recent research on hallucination mitigation has focused on retraining methods and Contrastive Decoding (CD) methods. While both methods perform well, retraining methods require substantial training resources, and CD methods introduce dual inference overhead. These factors hinder their practical applicability. To address the above issue, we propose a framework for dynamically detecting hallucination representations and performing hallucination-eliminating edits on these representations. With minimal additional computational cost, we achieve state-of-the-art performance on existing benchmarks. Extensive experiments demonstrate the effectiveness of our approach, highlighting its efficient and robust hallucination elimination capability and its powerful controllability over hallucinations. Code is available at https://github.com/ASGO-MM/HIRE
Understanding and Mitigating Hallucinations in Multimodal Chain-of-Thought Models
Mar 28, 2026Multimodal Chain-of-Thought (MCoT) models have demonstrated impressive capability in complex visual reasoning tasks. Unfortunately, recent studies reveal that they suffer from severe hallucination problems due to diminished visual attention during the generation process. However, visual attention decay is a well-studied problem in Large Vision-Language Models (LVLMs). Considering the fundamental differences in reasoning processes between MCoT models and traditional LVLMs, we raise a basic question: Whether MCoT models have unique causes of hallucinations? To answer this question, we systematically investigate the hallucination patterns of MCoT models and find that fabricated texts are primarily generated in associative reasoning steps, which we term divergent thinking. Leveraging these insights, we introduce a simple yet effective strategy that can effectively localize divergent thinking steps and intervene in the decoding process to mitigate hallucinations. Extensive experiments show that our method outperforms existing methods by a large margin. More importantly, our proposed method can be conveniently integrated with other hallucination mitigation methods and further boost their performance. The code is publicly available at https://github.com/ASGO-MM/MCoT-hallucination.
Pruning All-Rounder: Rethinking and Improving Inference Efficiency for Large Vision Language Models
Dec 09, 2024



Although Large Vision-Language Models (LVLMs) have achieved impressive results, their high computational cost poses a significant barrier to wider application. To enhance inference efficiency, most existing approaches depend on parameter-dependent or token-dependent strategies to reduce computational demands. However, these methods typically require complex training processes and struggle to consistently select the most relevant tokens. In this paper, we systematically analyze the above challenges and provide a series of valuable insights for inference acceleration. Based on these findings, we propose a novel framework, the Pruning All-Rounder (PAR). Different from previous works, PAR develops a meta-router to adaptively organize pruning flows across both tokens and layers. With a self-supervised learning manner, our method achieves a superior balance between performance and efficiency. Notably, PAR is highly flexible, offering multiple pruning versions to address a range of pruning scenarios. The code for this work will be made publicly available.
A Plug-and-Play Method for Rare Human-Object Interactions Detection by Bridging Domain Gap
Jul 31, 2024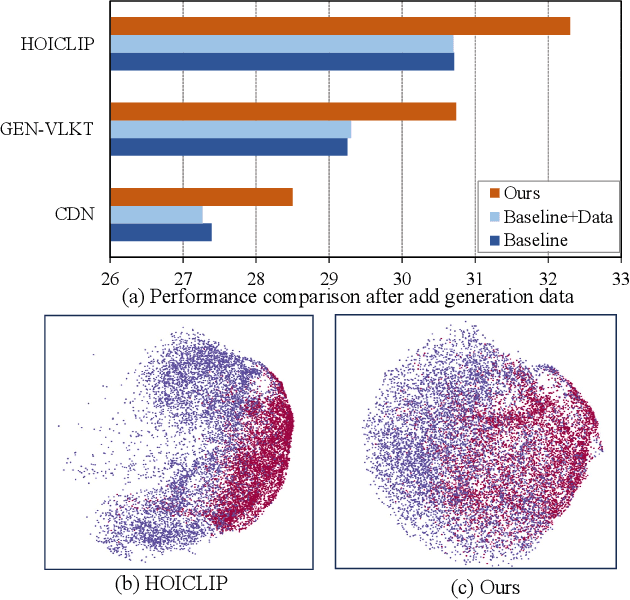
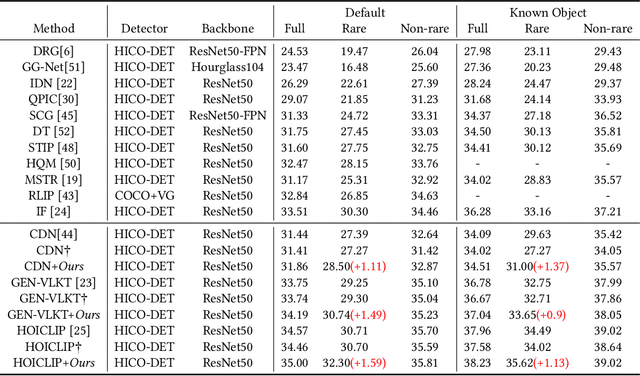
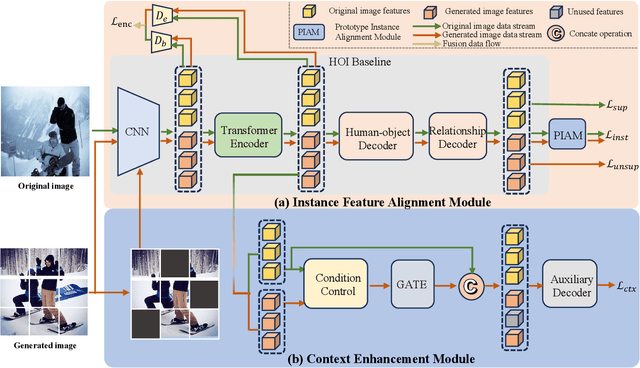
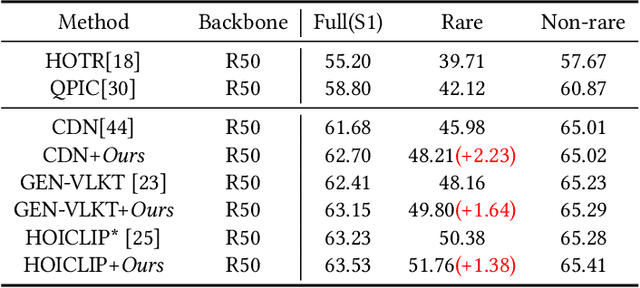
Human-object interactions (HOI) detection aims at capturing human-object pairs in images and corresponding actions. It is an important step toward high-level visual reasoning and scene understanding. However, due to the natural bias from the real world, existing methods mostly struggle with rare human-object pairs and lead to sub-optimal results. Recently, with the development of the generative model, a straightforward approach is to construct a more balanced dataset based on a group of supplementary samples. Unfortunately, there is a significant domain gap between the generated data and the original data, and simply merging the generated images into the original dataset cannot significantly boost the performance. To alleviate the above problem, we present a novel model-agnostic framework called \textbf{C}ontext-\textbf{E}nhanced \textbf{F}eature \textbf{A}lignment (CEFA) module, which can effectively align the generated data with the original data at the feature level and bridge the domain gap. Specifically, CEFA consists of a feature alignment module and a context enhancement module. On one hand, considering the crucial role of human-object pairs information in HOI tasks, the feature alignment module aligns the human-object pairs by aggregating instance information. On the other hand, to mitigate the issue of losing important context information caused by the traditional discriminator-style alignment method, we employ a context-enhanced image reconstruction module to improve the model's learning ability of contextual cues. Extensive experiments have shown that our method can serve as a plug-and-play module to improve the detection performance of HOI models on rare categories\footnote{https://github.com/LijunZhang01/CEFA}.
Visual Prompt Selection for In-Context Learning Segmentation
Jul 14, 2024As a fundamental and extensively studied task in computer vision, image segmentation aims to locate and identify different semantic concepts at the pixel level. Recently, inspired by In-Context Learning (ICL), several generalist segmentation frameworks have been proposed, providing a promising paradigm for segmenting specific objects. However, existing works mostly ignore the value of visual prompts or simply apply similarity sorting to select contextual examples. In this paper, we focus on rethinking and improving the example selection strategy. By comprehensive comparisons, we first demonstrate that ICL-based segmentation models are sensitive to different contexts. Furthermore, empirical evidence indicates that the diversity of contextual prompts plays a crucial role in guiding segmentation. Based on the above insights, we propose a new stepwise context search method. Different from previous works, we construct a small yet rich candidate pool and adaptively search the well-matched contexts. More importantly, this method effectively reduces the annotation cost by compacting the search space. Extensive experiments show that our method is an effective strategy for selecting examples and enhancing segmentation performance.
C3L: Content Correlated Vision-Language Instruction Tuning Data Generation via Contrastive Learning
May 21, 2024Vision-Language Instruction Tuning (VLIT) is a critical training phase for Large Vision-Language Models (LVLMs). With the improving capabilities of open-source LVLMs, researchers have increasingly turned to generate VLIT data by using open-source LVLMs and achieved significant progress. However, such data generation approaches are bottlenecked by the following challenges: 1) Since multi-modal models tend to be influenced by prior language knowledge, directly using LVLMs to generate VLIT data would inevitably lead to low content relevance between generated data and images. 2) To improve the ability of the models to generate VLIT data, previous methods have incorporated an additional training phase to boost the generative capacity. This process hurts the generalization of the models to unseen inputs (i.e., "exposure bias" problem). In this paper, we propose a new Content Correlated VLIT data generation via Contrastive Learning (C3L). Specifically, we design a new content relevance module which enhances the content relevance between VLIT data and images by computing Image Instruction Correspondence Scores S(I2C). Moreover, a contrastive learning module is introduced to further boost the VLIT data generation capability of the LVLMs. A large number of automatic measures on four benchmarks show the effectiveness of our method.
CoLeCLIP: Open-Domain Continual Learning via Joint Task Prompt and Vocabulary Learning
Mar 15, 2024



This paper explores the problem of continual learning (CL) of vision-language models (VLMs) in open domains, where the models need to perform continual updating and inference on a streaming of datasets from diverse seen and unseen domains with novel classes. Such a capability is crucial for various applications in open environments, e.g., AI assistants, autonomous driving systems, and robotics. Current CL studies mostly focus on closed-set scenarios in a single domain with known classes. Large pre-trained VLMs like CLIP have demonstrated superior zero-shot recognition ability, and a number of recent studies leverage this ability to mitigate catastrophic forgetting in CL, but they focus on closed-set CL in a single domain dataset. Open-domain CL of large VLMs is significantly more challenging due to 1) large class correlations and domain gaps across the datasets and 2) the forgetting of zero-shot knowledge in the pre-trained VLMs in addition to the knowledge learned from the newly adapted datasets. In this work we introduce a novel approach, termed CoLeCLIP, that learns an open-domain CL model based on CLIP. It addresses these challenges by a joint learning of a set of task prompts and a cross-domain class vocabulary. Extensive experiments on 11 domain datasets show that CoLeCLIP outperforms state-of-the-art methods for open-domain CL under both task- and class-incremental learning settings.
S3C: Semi-Supervised VQA Natural Language Explanation via Self-Critical Learning
Sep 05, 2023VQA Natural Language Explanation (VQA-NLE) task aims to explain the decision-making process of VQA models in natural language. Unlike traditional attention or gradient analysis, free-text rationales can be easier to understand and gain users' trust. Existing methods mostly use post-hoc or self-rationalization models to obtain a plausible explanation. However, these frameworks are bottlenecked by the following challenges: 1) the reasoning process cannot be faithfully responded to and suffer from the problem of logical inconsistency. 2) Human-annotated explanations are expensive and time-consuming to collect. In this paper, we propose a new Semi-Supervised VQA-NLE via Self-Critical Learning (S3C), which evaluates the candidate explanations by answering rewards to improve the logical consistency between answers and rationales. With a semi-supervised learning framework, the S3C can benefit from a tremendous amount of samples without human-annotated explanations. A large number of automatic measures and human evaluations all show the effectiveness of our method. Meanwhile, the framework achieves a new state-of-the-art performance on the two VQA-NLE datasets.
Dual-Level Decoupled Transformer for Video Captioning
May 06, 2022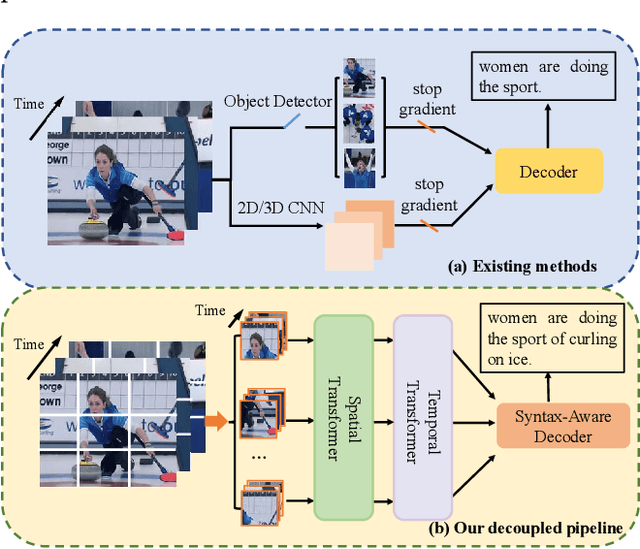
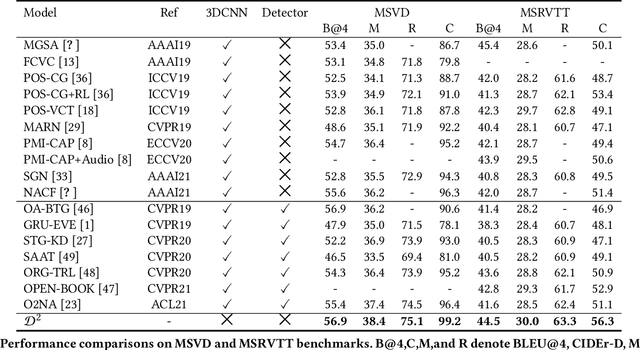
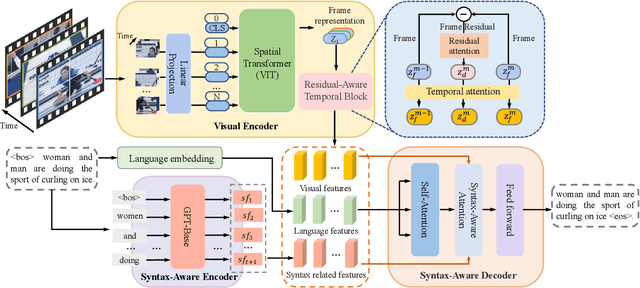
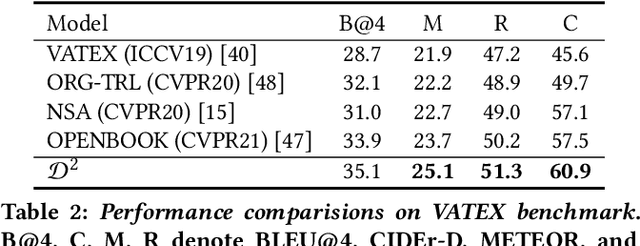
Video captioning aims to understand the spatio-temporal semantic concept of the video and generate descriptive sentences. The de-facto approach to this task dictates a text generator to learn from \textit{offline-extracted} motion or appearance features from \textit{pre-trained} vision models. However, these methods may suffer from the so-called \textbf{\textit{"couple"}} drawbacks on both \textit{video spatio-temporal representation} and \textit{sentence generation}. For the former, \textbf{\textit{"couple"}} means learning spatio-temporal representation in a single model(3DCNN), resulting the problems named \emph{disconnection in task/pre-train domain} and \emph{hard for end-to-end training}. As for the latter, \textbf{\textit{"couple"}} means treating the generation of visual semantic and syntax-related words equally. To this end, we present $\mathcal{D}^{2}$ - a dual-level decoupled transformer pipeline to solve the above drawbacks: \emph{(i)} for video spatio-temporal representation, we decouple the process of it into "first-spatial-then-temporal" paradigm, releasing the potential of using dedicated model(\textit{e.g.} image-text pre-training) to connect the pre-training and downstream tasks, and makes the entire model end-to-end trainable. \emph{(ii)} for sentence generation, we propose \emph{Syntax-Aware Decoder} to dynamically measure the contribution of visual semantic and syntax-related words. Extensive experiments on three widely-used benchmarks (MSVD, MSR-VTT and VATEX) have shown great potential of the proposed $\mathcal{D}^{2}$ and surpassed the previous methods by a large margin in the task of video captioning.
Proposal-free One-stage Referring Expression via Grid-Word Cross-Attention
May 05, 2021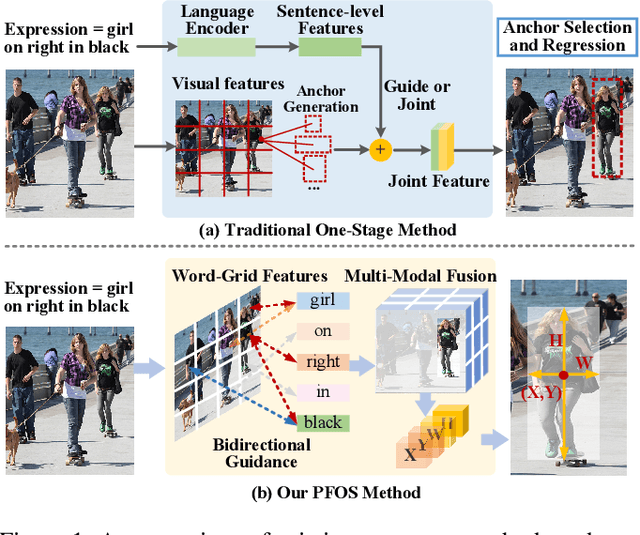
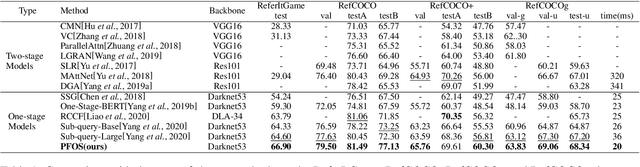
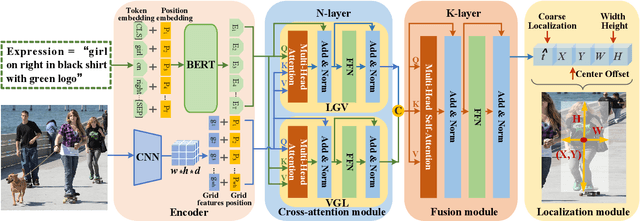
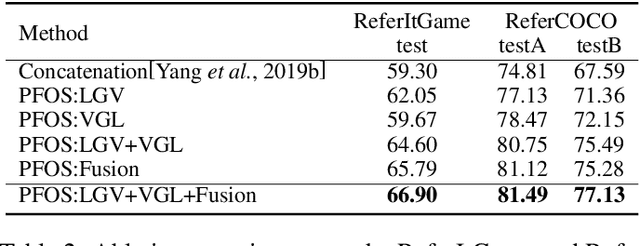
Referring Expression Comprehension (REC) has become one of the most important tasks in visual reasoning, since it is an essential step for many vision-and-language tasks such as visual question answering. However, it has not been widely used in many downstream tasks because it suffers 1) two-stage methods exist heavy computation cost and inevitable error accumulation, and 2) one-stage methods have to depend on lots of hyper-parameters (such as anchors) to generate bounding box. In this paper, we present a proposal-free one-stage (PFOS) model that is able to regress the region-of-interest from the image, based on a textual query, in an end-to-end manner. Instead of using the dominant anchor proposal fashion, we directly take the dense-grid of an image as input for a cross-attention transformer that learns grid-word correspondences. The final bounding box is predicted directly from the image without the time-consuming anchor selection process that previous methods suffer. Our model achieves the state-of-the-art performance on four referring expression datasets with higher efficiency, comparing to previous best one-stage and two-stage methods.