 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Efficient and Effective Text-to-Video Retrieval with Coarse-to-Fine Visual Representation Learning
Jan 01, 2024



In recent years, text-to-video retrieval methods based on CLIP have experienced rapid development. The primary direction of evolution is to exploit the much wider gamut of visual and textual cues to achieve alignment. Concretely, those methods with impressive performance often design a heavy fusion block for sentence (words)-video (frames) interaction, regardless of the prohibitive computation complexity. Nevertheless, these approaches are not optimal in terms of feature utilization and retrieval efficiency. To address this issue, we adopt multi-granularity visual feature learning, ensuring the model's comprehensiveness in capturing visual content features spanning from abstract to detailed levels during the training phase. To better leverage the multi-granularity features, we devise a two-stage retrieval architecture in the retrieval phase. This solution ingeniously balances the coarse and fine granularity of retrieval content. Moreover, it also strikes a harmonious equilibrium between retrieval effectiveness and efficiency. Specifically, in training phase, we design a parameter-free text-gated interaction block (TIB) for fine-grained video representation learning and embed an extra Pearson Constraint to optimize cross-modal representation learning. In retrieval phase, we use coarse-grained video representations for fast recall of top-k candidates, which are then reranked by fine-grained video representations. Extensive experiments on four benchmarks demonstrate the efficiency and effectiveness. Notably, our method achieves comparable performance with the current state-of-the-art methods while being nearly 50 times faster.
Visual Captioning at Will: Describing Images and Videos Guided by a Few Stylized Sentences
Jul 31, 2023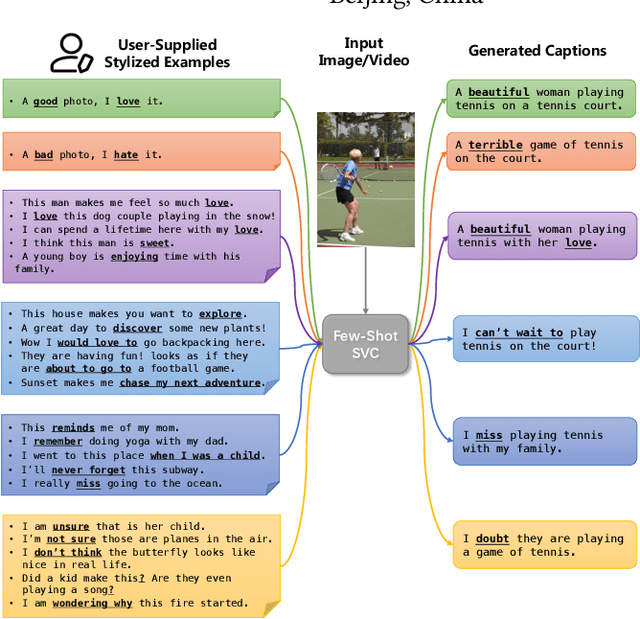
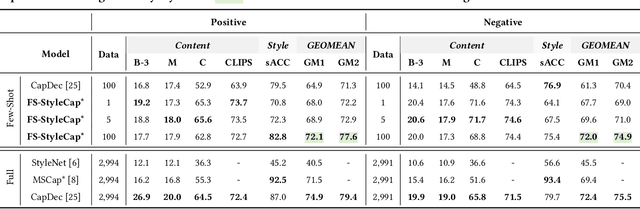
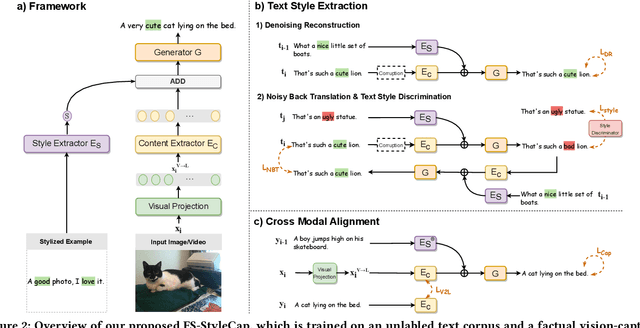
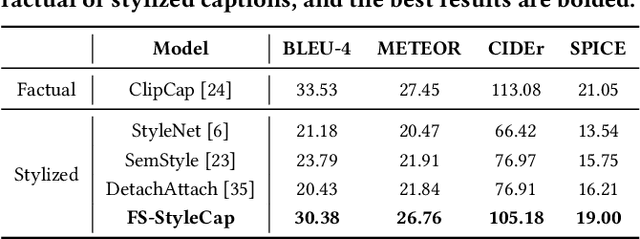
Stylized visual captioning aims to generate image or video descriptions with specific styles, making them more attractive and emotionally appropriate. One major challenge with this task is the lack of paired stylized captions for visual content, so most existing works focus on unsupervised methods that do not rely on parallel datasets. However, these approaches still require training with sufficient examples that have style labels, and the generated captions are limited to predefined styles. To address these limitations, we explore the problem of Few-Shot Stylized Visual Captioning, which aims to generate captions in any desired style, using only a few examples as guidance during inference, without requiring further training. We propose a framework called FS-StyleCap for this task, which utilizes a conditional encoder-decoder language model and a visual projection module. Our two-step training scheme proceeds as follows: first, we train a style extractor to generate style representations on an unlabeled text-only corpus. Then, we freeze the extractor and enable our decoder to generate stylized descriptions based on the extracted style vector and projected visual content vectors. During inference, our model can generate desired stylized captions by deriving the style representation from user-supplied examples. Our automatic evaluation results for few-shot sentimental visual captioning outperform state-of-the-art approaches and are comparable to models that are fully trained on labeled style corpora. Human evaluations further confirm our model s ability to handle multiple styles.
Edit As You Wish: Video Description Editing with Multi-grained Commands
May 15, 2023Automatically narrating a video with natural language can assist people in grasping and managing massive videos on the Internet. From the perspective of video uploaders, they may have varied preferences for writing the desired video description to attract more potential followers, e.g. catching customers' attention for product videos. The Controllable Video Captioning task is therefore proposed to generate a description conditioned on the user demand and video content. However, existing works suffer from two shortcomings: 1) the control signal is fixed and can only express single-grained control; 2) the video description can not be further edited to meet dynamic user demands. In this paper, we propose a novel Video Description Editing (VDEdit) task to automatically revise an existing video description guided by flexible user requests. Inspired by human writing-revision habits, we design the user command as a {operation, position, attribute} triplet to cover multi-grained use requirements, which can express coarse-grained control (e.g. expand the description) as well as fine-grained control (e.g. add specified details in specified position) in a unified format. To facilitate the VDEdit task, we first automatically construct a large-scale benchmark dataset namely VATEX-EDIT in the open domain describing diverse human activities. Considering the real-life application scenario, we further manually collect an e-commerce benchmark dataset called EMMAD-EDIT. We propose a unified framework to convert the {operation, position, attribute} triplet into a textual control sequence to handle multi-grained editing commands. For VDEdit evaluation, we adopt comprehensive metrics to measure three aspects of model performance, including caption quality, caption-command consistency, and caption-video alignment.
Attract me to Buy: Advertisement Copywriting Generation with Multimodal Multi-structured Information
May 07, 2022



Recently, online shopping has gradually become a common way of shopping for people all over the world. Wonderful merchandise advertisements often attract more people to buy. These advertisements properly integrate multimodal multi-structured information of commodities, such as visual spatial information and fine-grained structure information. However, traditional multimodal text generation focuses on the conventional description of what existed and happened, which does not match the requirement of advertisement copywriting in the real world. Because advertisement copywriting has a vivid language style and higher requirements of faithfulness. Unfortunately, there is a lack of reusable evaluation frameworks and a scarcity of datasets. Therefore, we present a dataset, E-MMAD (e-commercial multimodal multi-structured advertisement copywriting), which requires, and supports much more detailed information in text generation. Noticeably, it is one of the largest video captioning datasets in this field. Accordingly, we propose a baseline method and faithfulness evaluation metric on the strength of structured information reasoning to solve the demand in reality on this dataset. It surpasses the previous methods by a large margin on all metrics. The dataset and method are coming soon on \url{https://e-mmad.github.io/e-mmad.net/index.html}.
Dual-Level Decoupled Transformer for Video Captioning
May 06, 2022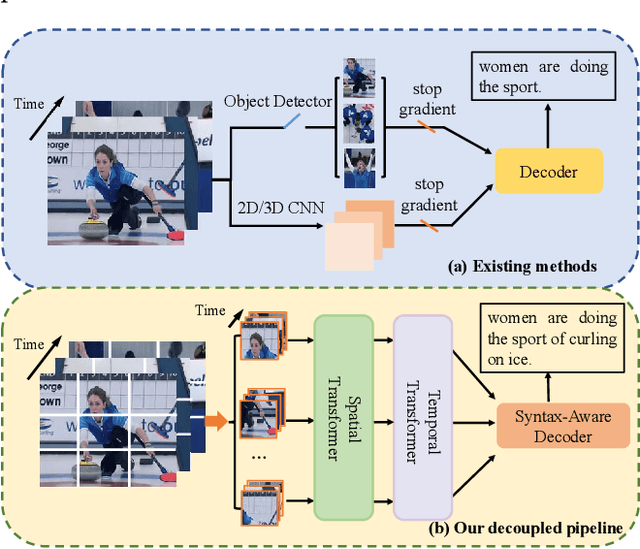
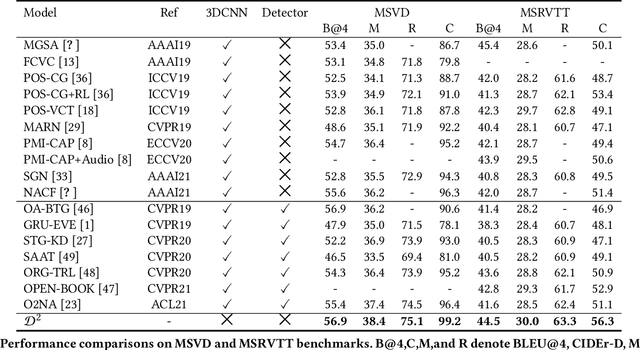
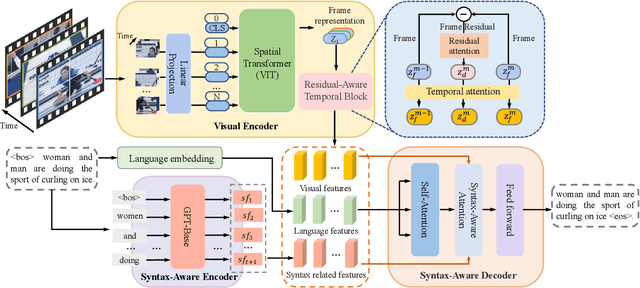
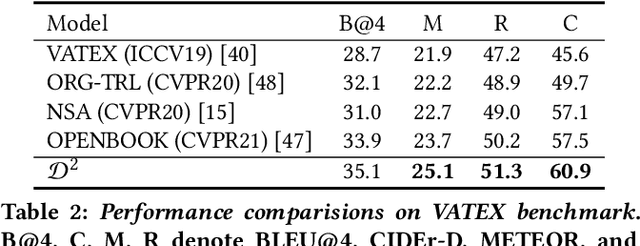
Video captioning aims to understand the spatio-temporal semantic concept of the video and generate descriptive sentences. The de-facto approach to this task dictates a text generator to learn from \textit{offline-extracted} motion or appearance features from \textit{pre-trained} vision models. However, these methods may suffer from the so-called \textbf{\textit{"couple"}} drawbacks on both \textit{video spatio-temporal representation} and \textit{sentence generation}. For the former, \textbf{\textit{"couple"}} means learning spatio-temporal representation in a single model(3DCNN), resulting the problems named \emph{disconnection in task/pre-train domain} and \emph{hard for end-to-end training}. As for the latter, \textbf{\textit{"couple"}} means treating the generation of visual semantic and syntax-related words equally. To this end, we present $\mathcal{D}^{2}$ - a dual-level decoupled transformer pipeline to solve the above drawbacks: \emph{(i)} for video spatio-temporal representation, we decouple the process of it into "first-spatial-then-temporal" paradigm, releasing the potential of using dedicated model(\textit{e.g.} image-text pre-training) to connect the pre-training and downstream tasks, and makes the entire model end-to-end trainable. \emph{(ii)} for sentence generation, we propose \emph{Syntax-Aware Decoder} to dynamically measure the contribution of visual semantic and syntax-related words. Extensive experiments on three widely-used benchmarks (MSVD, MSR-VTT and VATEX) have shown great potential of the proposed $\mathcal{D}^{2}$ and surpassed the previous methods by a large margin in the task of video captioning.
CapOnImage: Context-driven Dense-Captioning on Image
Apr 27, 2022
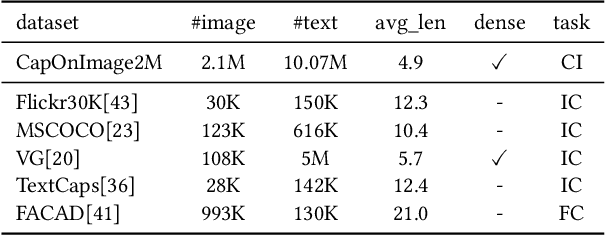
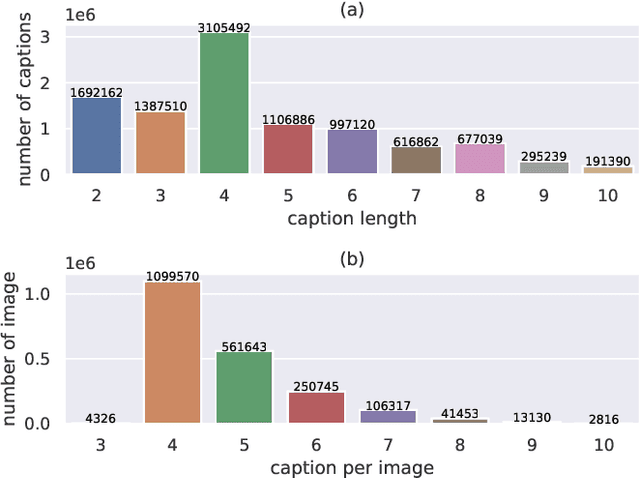
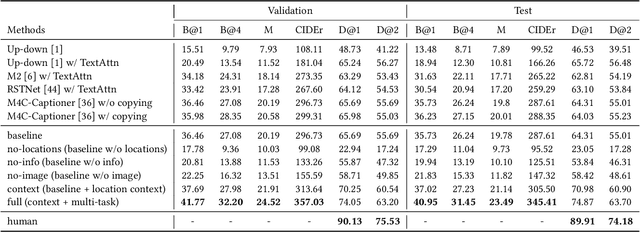
Existing image captioning systems are dedicated to generating narrative captions for images, which are spatially detached from the image in presentation. However, texts can also be used as decorations on the image to highlight the key points and increase the attractiveness of images. In this work, we introduce a new task called captioning on image (CapOnImage), which aims to generate dense captions at different locations of the image based on contextual information. To fully exploit the surrounding visual context to generate the most suitable caption for each location, we propose a multi-modal pre-training model with multi-level pre-training tasks that progressively learn the correspondence between texts and image locations from easy to difficult. Since the model may generate redundant captions for nearby locations, we further enhance the location embedding with neighbor locations as context. For this new task, we also introduce a large-scale benchmark called CapOnImage2M, which contains 2.1 million product images, each with an average of 4.8 spatially localized captions. Compared with other image captioning model variants, our model achieves the best results in both captioning accuracy and diversity aspects. We will make code and datasets public to facilitate future research.