 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre LLMs Smarter Than Chimpanzees? An Evaluation on Perspective Taking and Knowledge State Estimation
Jan 18, 2026Cognitive anthropology suggests that the distinction of human intelligence lies in the ability to infer other individuals' knowledge states and understand their intentions. In comparison, our closest animal relative, chimpanzees, lack the capacity to do so. With this paper, we aim to evaluate LLM performance in the area of knowledge state tracking and estimation. We design two tasks to test (1) if LLMs can detect when story characters, through their actions, demonstrate knowledge they should not possess, and (2) if LLMs can predict story characters' next actions based on their own knowledge vs. objective truths they do not know. Results reveal that most current state-of-the-art LLMs achieve near-random performance on both tasks, and are substantially inferior to humans. We argue future LLM research should place more weight on the abilities of knowledge estimation and intention understanding.
What Matters in Evaluating Book-Length Stories? A Systematic Study of Long Story Evaluation
Dec 14, 2025In this work, we conduct systematic research in a challenging area: the automatic evaluation of book-length stories (>100K tokens). Our study focuses on two key questions: (1) understanding which evaluation aspects matter most to readers, and (2) exploring effective methods for evaluating lengthy stories. We introduce the first large-scale benchmark, LongStoryEval, comprising 600 newly published books with an average length of 121K tokens (maximum 397K). Each book includes its average rating and multiple reader reviews, presented as critiques organized by evaluation aspects. By analyzing all user-mentioned aspects, we propose an evaluation criteria structure and conduct experiments to identify the most significant aspects among the 8 top-level criteria. For evaluation methods, we compare the effectiveness of three types: aggregation-based, incremental-updated, and summary-based evaluations. Our findings reveal that aggregation- and summary-based evaluations perform better, with the former excelling in detail assessment and the latter offering greater efficiency. Building on these insights, we further propose NovelCritique, an 8B model that leverages the efficient summary-based framework to review and score stories across specified aspects. NovelCritique outperforms commercial models like GPT-4o in aligning with human evaluations. Our datasets and codes are available at https://github.com/DingyiYang/LongStoryEval.
TimeZero: Temporal Video Grounding with Reasoning-Guided LVLM
Mar 17, 2025We introduce TimeZero, a reasoning-guided LVLM designed for the temporal video grounding (TVG) task. This task requires precisely localizing relevant video segments within long videos based on a given language query. TimeZero tackles this challenge by extending the inference process, enabling the model to reason about video-language relationships solely through reinforcement learning. To evaluate the effectiveness of TimeZero, we conduct experiments on two benchmarks, where TimeZero achieves state-of-the-art performance on Charades-STA. Code is available at https://github.com/www-Ye/TimeZero.
What Makes a Good Story and How Can We Measure It? A Comprehensive Survey of Story Evaluation
Aug 26, 2024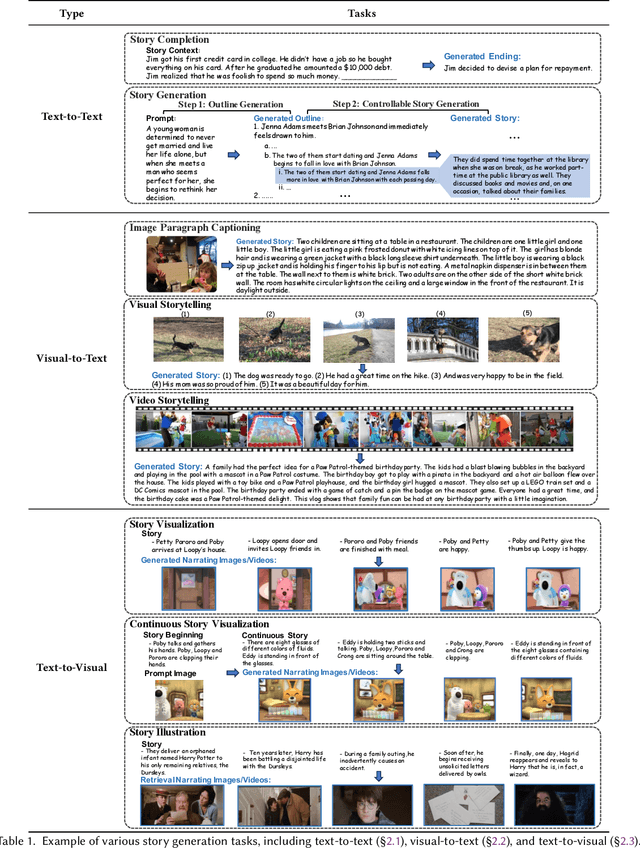
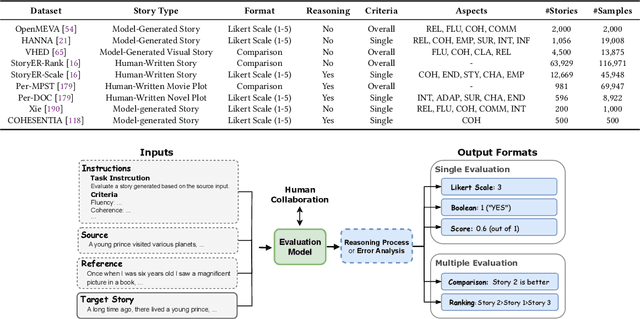
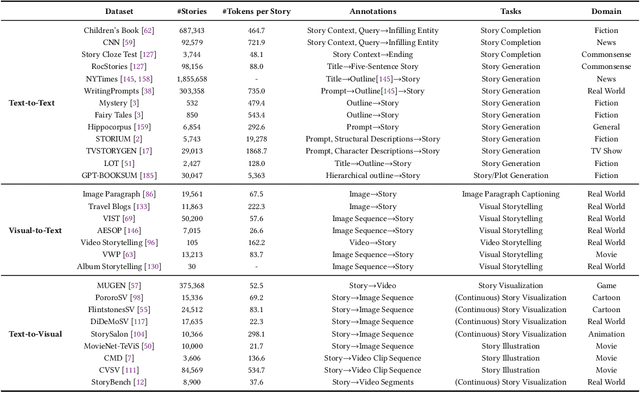
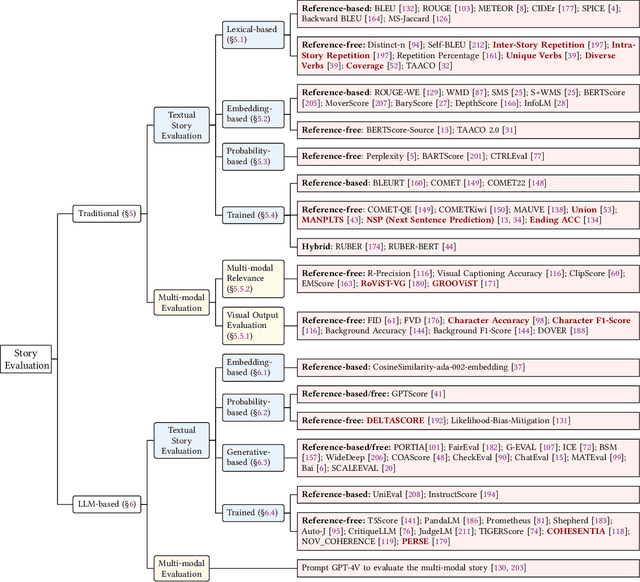
With the development of artificial intelligence, particularly the success of Large Language Models (LLMs), the quantity and quality of automatically generated stories have significantly increased. This has led to the need for automatic story evaluation to assess the generative capabilities of computing systems and analyze the quality of both automatic-generated and human-written stories. Evaluating a story can be more challenging than other generation evaluation tasks. While tasks like machine translation primarily focus on assessing the aspects of fluency and accuracy, story evaluation demands complex additional measures such as overall coherence, character development, interestingness, etc. This requires a thorough review of relevant research. In this survey, we first summarize existing storytelling tasks, including text-to-text, visual-to-text, and text-to-visual. We highlight their evaluation challenges, identify various human criteria to measure stories, and present existing benchmark datasets. Then, we propose a taxonomy to organize evaluation metrics that have been developed or can be adopted for story evaluation. We also provide descriptions of these metrics, along with the discussion of their merits and limitations. Later, we discuss the human-AI collaboration for story evaluation and generation. Finally, we suggest potential future research directions, extending from story evaluation to general evaluations.
Visual Captioning at Will: Describing Images and Videos Guided by a Few Stylized Sentences
Jul 31, 2023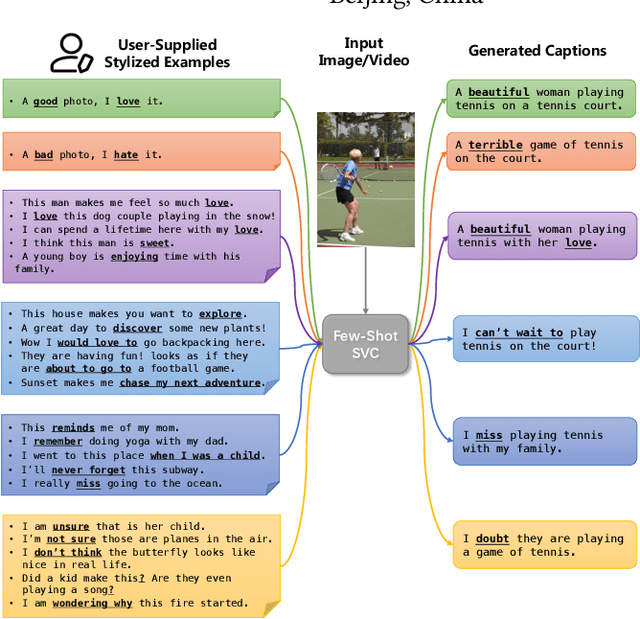
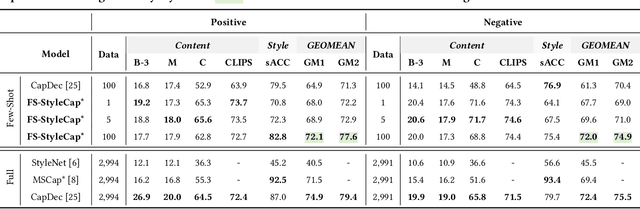
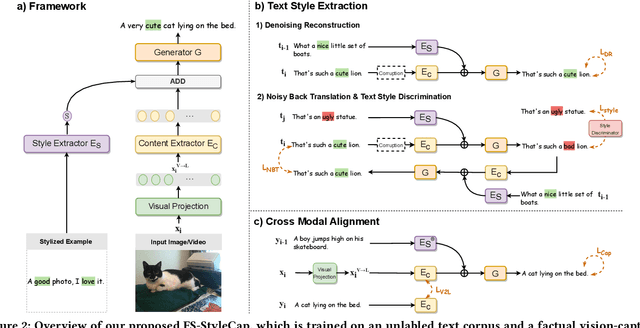
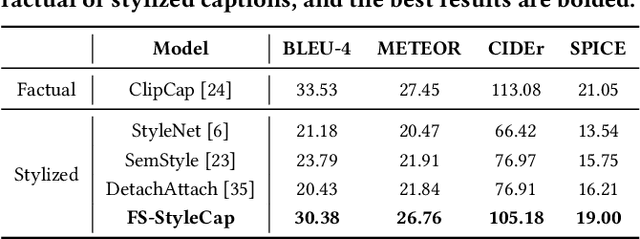
Stylized visual captioning aims to generate image or video descriptions with specific styles, making them more attractive and emotionally appropriate. One major challenge with this task is the lack of paired stylized captions for visual content, so most existing works focus on unsupervised methods that do not rely on parallel datasets. However, these approaches still require training with sufficient examples that have style labels, and the generated captions are limited to predefined styles. To address these limitations, we explore the problem of Few-Shot Stylized Visual Captioning, which aims to generate captions in any desired style, using only a few examples as guidance during inference, without requiring further training. We propose a framework called FS-StyleCap for this task, which utilizes a conditional encoder-decoder language model and a visual projection module. Our two-step training scheme proceeds as follows: first, we train a style extractor to generate style representations on an unlabeled text-only corpus. Then, we freeze the extractor and enable our decoder to generate stylized descriptions based on the extracted style vector and projected visual content vectors. During inference, our model can generate desired stylized captions by deriving the style representation from user-supplied examples. Our automatic evaluation results for few-shot sentimental visual captioning outperform state-of-the-art approaches and are comparable to models that are fully trained on labeled style corpora. Human evaluations further confirm our model s ability to handle multiple styles.