 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMiMo-V2-Flash Technical Report
Jan 08, 2026We present MiMo-V2-Flash, a Mixture-of-Experts (MoE) model with 309B total parameters and 15B active parameters, designed for fast, strong reasoning and agentic capabilities. MiMo-V2-Flash adopts a hybrid attention architecture that interleaves Sliding Window Attention (SWA) with global attention, with a 128-token sliding window under a 5:1 hybrid ratio. The model is pre-trained on 27 trillion tokens with Multi-Token Prediction (MTP), employing a native 32k context length and subsequently extended to 256k. To efficiently scale post-training compute, MiMo-V2-Flash introduces a novel Multi-Teacher On-Policy Distillation (MOPD) paradigm. In this framework, domain-specialized teachers (e.g., trained via large-scale reinforcement learning) provide dense and token-level reward, enabling the student model to perfectly master teacher expertise. MiMo-V2-Flash rivals top-tier open-weight models such as DeepSeek-V3.2 and Kimi-K2, despite using only 1/2 and 1/3 of their total parameters, respectively. During inference, by repurposing MTP as a draft model for speculative decoding, MiMo-V2-Flash achieves up to 3.6 acceptance length and 2.6x decoding speedup with three MTP layers. We open-source both the model weights and the three-layer MTP weights to foster open research and community collaboration.
MiMo-Audio: Audio Language Models are Few-Shot Learners
Dec 29, 2025Existing audio language models typically rely on task-specific fine-tuning to accomplish particular audio tasks. In contrast, humans are able to generalize to new audio tasks with only a few examples or simple instructions. GPT-3 has shown that scaling next-token prediction pretraining enables strong generalization capabilities in text, and we believe this paradigm is equally applicable to the audio domain. By scaling MiMo-Audio's pretraining data to over one hundred million of hours, we observe the emergence of few-shot learning capabilities across a diverse set of audio tasks. We develop a systematic evaluation of these capabilities and find that MiMo-Audio-7B-Base achieves SOTA performance on both speech intelligence and audio understanding benchmarks among open-source models. Beyond standard metrics, MiMo-Audio-7B-Base generalizes to tasks absent from its training data, such as voice conversion, style transfer, and speech editing. MiMo-Audio-7B-Base also demonstrates powerful speech continuation capabilities, capable of generating highly realistic talk shows, recitations, livestreaming and debates. At the post-training stage, we curate a diverse instruction-tuning corpus and introduce thinking mechanisms into both audio understanding and generation. MiMo-Audio-7B-Instruct achieves open-source SOTA on audio understanding benchmarks (MMSU, MMAU, MMAR, MMAU-Pro), spoken dialogue benchmarks (Big Bench Audio, MultiChallenge Audio) and instruct-TTS evaluations, approaching or surpassing closed-source models. Model checkpoints and full evaluation suite are available at https://github.com/XiaomiMiMo/MiMo-Audio.
GroundingME: Exposing the Visual Grounding Gap in MLLMs through Multi-Dimensional Evaluation
Dec 19, 2025Visual grounding, localizing objects from natural language descriptions, represents a critical bridge between language and vision understanding. While multimodal large language models (MLLMs) achieve impressive scores on existing benchmarks, a fundamental question remains: can MLLMs truly ground language in vision with human-like sophistication, or are they merely pattern-matching on simplified datasets? Current benchmarks fail to capture real-world complexity where humans effortlessly navigate ambiguous references and recognize when grounding is impossible. To rigorously assess MLLMs' true capabilities, we introduce GroundingME, a benchmark that systematically challenges models across four critical dimensions: (1) Discriminative, distinguishing highly similar objects, (2) Spatial, understanding complex relational descriptions, (3) Limited, handling occlusions or tiny objects, and (4) Rejection, recognizing ungroundable queries. Through careful curation combining automated generation with human verification, we create 1,005 challenging examples mirroring real-world complexity. Evaluating 25 state-of-the-art MLLMs reveals a profound capability gap: the best model achieves only 45.1% accuracy, while most score 0% on rejection tasks, reflexively hallucinating objects rather than acknowledging their absence, raising critical safety concerns for deployment. We explore two strategies for improvements: (1) test-time scaling selects optimal response by thinking trajectory to improve complex grounding by up to 2.9%, and (2) data-mixture training teaches models to recognize ungroundable queries, boosting rejection accuracy from 0% to 27.9%. GroundingME thus serves as both a diagnostic tool revealing current limitations in MLLMs and a roadmap toward human-level visual grounding.
MiMo: Unlocking the Reasoning Potential of Language Model -- From Pretraining to Posttraining
May 12, 2025We present MiMo-7B, a large language model born for reasoning tasks, with optimization across both pre-training and post-training stages. During pre-training, we enhance the data preprocessing pipeline and employ a three-stage data mixing strategy to strengthen the base model's reasoning potential. MiMo-7B-Base is pre-trained on 25 trillion tokens, with additional Multi-Token Prediction objective for enhanced performance and accelerated inference speed. During post-training, we curate a dataset of 130K verifiable mathematics and programming problems for reinforcement learning, integrating a test-difficulty-driven code-reward scheme to alleviate sparse-reward issues and employing strategic data resampling to stabilize training. Extensive evaluations show that MiMo-7B-Base possesses exceptional reasoning potential, outperforming even much larger 32B models. The final RL-tuned model, MiMo-7B-RL, achieves superior performance on mathematics, code and general reasoning tasks, surpassing the performance of OpenAI o1-mini. The model checkpoints are available at https://github.com/xiaomimimo/MiMo.
TimeZero: Temporal Video Grounding with Reasoning-Guided LVLM
Mar 17, 2025We introduce TimeZero, a reasoning-guided LVLM designed for the temporal video grounding (TVG) task. This task requires precisely localizing relevant video segments within long videos based on a given language query. TimeZero tackles this challenge by extending the inference process, enabling the model to reason about video-language relationships solely through reinforcement learning. To evaluate the effectiveness of TimeZero, we conduct experiments on two benchmarks, where TimeZero achieves state-of-the-art performance on Charades-STA. Code is available at https://github.com/www-Ye/TimeZero.
Seg-Zero: Reasoning-Chain Guided Segmentation via Cognitive Reinforcement
Mar 09, 2025Traditional methods for reasoning segmentation rely on supervised fine-tuning with categorical labels and simple descriptions, limiting its out-of-domain generalization and lacking explicit reasoning processes. To address these limitations, we propose Seg-Zero, a novel framework that demonstrates remarkable generalizability and derives explicit chain-of-thought reasoning through cognitive reinforcement. Seg-Zero introduces a decoupled architecture consisting of a reasoning model and a segmentation model. The reasoning model interprets user intentions, generates explicit reasoning chains, and produces positional prompts, which are subsequently used by the segmentation model to generate precious pixel-level masks. We design a sophisticated reward mechanism that integrates both format and accuracy rewards to effectively guide optimization directions. Trained exclusively via reinforcement learning with GRPO and without explicit reasoning data, Seg-Zero achieves robust zero-shot generalization and exhibits emergent test-time reasoning capabilities. Experiments show that Seg-Zero-7B achieves a zero-shot performance of 57.5 on the ReasonSeg benchmark, surpassing the prior LISA-7B by 18\%. This significant improvement highlights Seg-Zero's ability to generalize across domains while presenting an explicit reasoning process. Code is available at https://github.com/dvlab-research/Seg-Zero.
Movie101v2: Improved Movie Narration Benchmark
Apr 20, 2024



Automatic movie narration targets at creating video-aligned plot descriptions to assist visually impaired audiences. It differs from standard video captioning in that it requires not only describing key visual details but also inferring the plots developed across multiple movie shots, thus posing unique and ongoing challenges. To advance the development of automatic movie narrating systems, we first revisit the limitations of existing datasets and develop a large-scale, bilingual movie narration dataset, Movie101v2. Second, taking into account the essential difficulties in achieving applicable movie narration, we break the long-term goal into three progressive stages and tentatively focus on the initial stages featuring understanding within individual clips. We also introduce a new narration assessment to align with our staged task goals. Third, using our new dataset, we baseline several leading large vision-language models, including GPT-4V, and conduct in-depth investigations into the challenges current models face for movie narration generation. Our findings reveal that achieving applicable movie narration generation is a fascinating goal that requires thorough research.
Less is More: Mitigating Multimodal Hallucination from an EOS Decision Perspective
Feb 22, 2024Large Multimodal Models (LMMs) often suffer from multimodal hallucinations, wherein they may create content that is not present in the visual inputs. In this paper, we explore a new angle of this issue: overly detailed training data hinders the model's ability to timely terminate generation, leading to continued outputs beyond visual perception limits. By investigating how the model decides to terminate generation with EOS, the special end-of-sentence token, we find that the model assesses the completeness of the entire sequence by comparing the generated text with the image. This observation suggests that the model possesses an inherent potential of making proper EOS decisions based on its visual perception to avoid overly lengthy outputs. To take advantage of such potential, we explore two methods to mitigate multimodal hallucinations: a training objective that enables the model to reduce hallucinations by learning from regular instruction data, and a data filtering strategy to prevent harmful training data from exacerbating model hallucinations. Both methods significantly improve the hallucination performance of LMMs, without requiring any additional data or knowledge.
Learning Descriptive Image Captioning via Semipermeable Maximum Likelihood Estimation
Jun 27, 2023


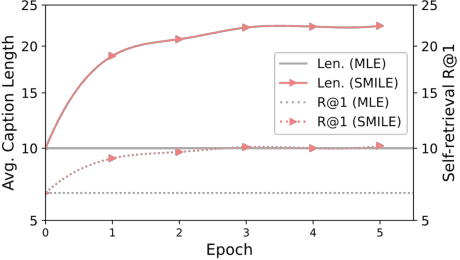
Image captioning aims to describe visual content in natural language. As 'a picture is worth a thousand words', there could be various correct descriptions for an image. However, with maximum likelihood estimation as the training objective, the captioning model is penalized whenever its prediction mismatches with the label. For instance, when the model predicts a word expressing richer semantics than the label, it will be penalized and optimized to prefer more concise expressions, referred to as conciseness optimization. In contrast, predictions that are more concise than labels lead to richness optimization. Such conflicting optimization directions could eventually result in the model generating general descriptions. In this work, we introduce Semipermeable MaxImum Likelihood Estimation (SMILE), which allows richness optimization while blocking conciseness optimization, thus encouraging the model to generate longer captions with more details. Extensive experiments on two mainstream image captioning datasets MSCOCO and Flickr30K demonstrate that SMILE significantly enhances the descriptiveness of generated captions. We further provide in-depth investigations to facilitate a better understanding of how SMILE works.
Movie101: A New Movie Understanding Benchmark
May 20, 2023



To help the visually impaired enjoy movies, automatic movie narrating systems are expected to narrate accurate, coherent, and role-aware plots when there are no speaking lines of actors. Existing works benchmark this challenge as a normal video captioning task via some simplifications, such as removing role names and evaluating narrations with ngram-based metrics, which makes it difficult for automatic systems to meet the needs of real application scenarios. To narrow this gap, we construct a large-scale Chinese movie benchmark, named Movie101. Closer to real scenarios, the Movie Clip Narrating (MCN) task in our benchmark asks models to generate role-aware narration paragraphs for complete movie clips where no actors are speaking. External knowledge, such as role information and movie genres, is also provided for better movie understanding. Besides, we propose a new metric called Movie Narration Score (MNScore) for movie narrating evaluation, which achieves the best correlation with human evaluation. Our benchmark also supports the Temporal Narration Grounding (TNG) task to investigate clip localization given text descriptions. For both two tasks, our proposed methods well leverage external knowledge and outperform carefully designed baselines. The dataset and codes are released at https://github.com/yuezih/Movie101.