 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARPO:End-to-End Policy Optimization for GUI Agents with Experience Replay
May 22, 2025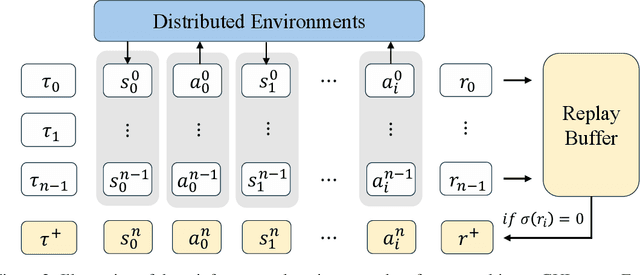
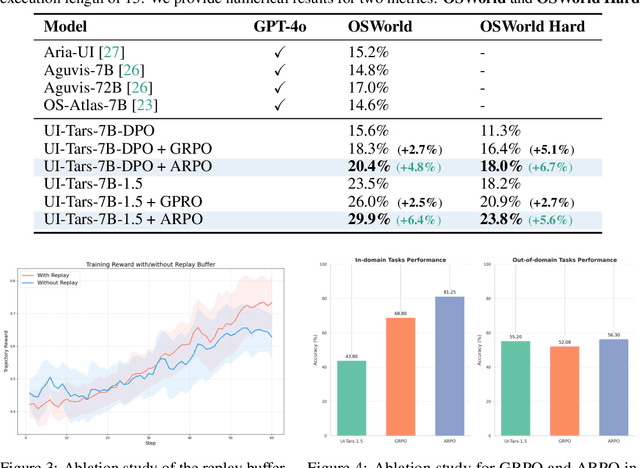
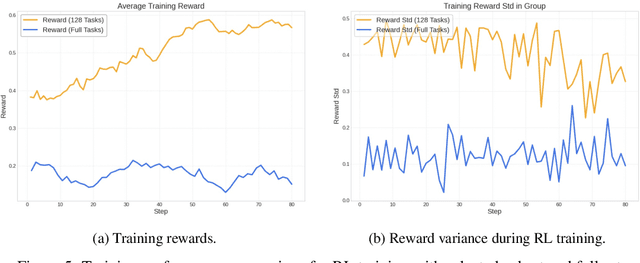
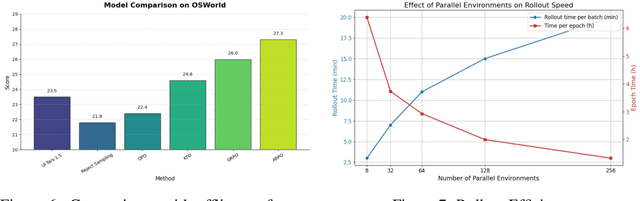
Training large language models (LLMs) as interactive agents for controlling graphical user interfaces (GUIs) presents a unique challenge to optimize long-horizon action sequences with multimodal feedback from complex environments. While recent works have advanced multi-turn reinforcement learning (RL) for reasoning and tool-using capabilities in LLMs, their application to GUI-based agents remains relatively underexplored due to the difficulty of sparse rewards, delayed feedback, and high rollout costs. In this paper, we investigate end-to-end policy optimization for vision-language-based GUI agents with the aim of improving performance on complex, long-horizon computer tasks. We propose Agentic Replay Policy Optimization (ARPO), an end-to-end RL approach that augments Group Relative Policy Optimization (GRPO) with a replay buffer to reuse the successful experience across training iterations. To further stabilize the training process, we propose a task selection strategy that filters tasks based on baseline agent performance, allowing the agent to focus on learning from informative interactions. Additionally, we compare ARPO with offline preference optimization approaches, highlighting the advantages of policy-based methods in GUI environments. Experiments on the OSWorld benchmark demonstrate that ARPO achieves competitive results, establishing a new performance baseline for LLM-based GUI agents trained via reinforcement learning. Our findings underscore the effectiveness of reinforcement learning for training multi-turn, vision-language GUI agents capable of managing complex real-world UI interactions. Codes and models:https://github.com/dvlab-research/ARPO.git.
VisionReasoner: Unified Visual Perception and Reasoning via Reinforcement Learning
May 17, 2025Large vision-language models exhibit inherent capabilities to handle diverse visual perception tasks. In this paper, we introduce VisionReasoner, a unified framework capable of reasoning and solving multiple visual perception tasks within a shared model. Specifically, by designing novel multi-object cognitive learning strategies and systematic task reformulation, VisionReasoner enhances its reasoning capabilities to analyze visual inputs, and addresses diverse perception tasks in a unified framework. The model generates a structured reasoning process before delivering the desired outputs responding to user queries. To rigorously assess unified visual perception capabilities, we evaluate VisionReasoner on ten diverse tasks spanning three critical domains: detection, segmentation, and counting. Experimental results show that VisionReasoner achieves superior performance as a unified model, outperforming Qwen2.5VL by relative margins of 29.1% on COCO (detection), 22.1% on ReasonSeg (segmentation), and 15.3% on CountBench (counting).
STEVE: AStep Verification Pipeline for Computer-use Agent Training
Mar 16, 2025Developing AI agents to autonomously manipulate graphical user interfaces is a long challenging task. Recent advances in data scaling law inspire us to train computer-use agents with a scaled instruction set, yet using behavior cloning to train agents still requires immense high-quality trajectories. To meet the scalability need, we designed STEVE, a step verification pipeline for computer-use agent training. First, we establish a large instruction set for computer-use agents and collect trajectory data with some suboptimal agents. GPT-4o is used to verify the correctness of each step in the trajectories based on the screens before and after the action execution, assigning each step with a binary label. Last, we adopt the Kahneman and Tversky Optimization to optimize the agent from the binary stepwise labels. Extensive experiments manifest that our agent outperforms supervised finetuning by leveraging both positive and negative actions within a trajectory. Also, STEVE enables us to train a 7B vision-language model as a computer-use agent, achieving leading performance in the challenging live desktop environment WinAgentArena with great efficiency at a reduced cost. Code and data: https://github.com/FanbinLu/STEVE.
Seg-Zero: Reasoning-Chain Guided Segmentation via Cognitive Reinforcement
Mar 09, 2025Traditional methods for reasoning segmentation rely on supervised fine-tuning with categorical labels and simple descriptions, limiting its out-of-domain generalization and lacking explicit reasoning processes. To address these limitations, we propose Seg-Zero, a novel framework that demonstrates remarkable generalizability and derives explicit chain-of-thought reasoning through cognitive reinforcement. Seg-Zero introduces a decoupled architecture consisting of a reasoning model and a segmentation model. The reasoning model interprets user intentions, generates explicit reasoning chains, and produces positional prompts, which are subsequently used by the segmentation model to generate precious pixel-level masks. We design a sophisticated reward mechanism that integrates both format and accuracy rewards to effectively guide optimization directions. Trained exclusively via reinforcement learning with GRPO and without explicit reasoning data, Seg-Zero achieves robust zero-shot generalization and exhibits emergent test-time reasoning capabilities. Experiments show that Seg-Zero-7B achieves a zero-shot performance of 57.5 on the ReasonSeg benchmark, surpassing the prior LISA-7B by 18\%. This significant improvement highlights Seg-Zero's ability to generalize across domains while presenting an explicit reasoning process. Code is available at https://github.com/dvlab-research/Seg-Zero.
Lyra: An Efficient and Speech-Centric Framework for Omni-Cognition
Dec 12, 2024



As Multi-modal Large Language Models (MLLMs) evolve, expanding beyond single-domain capabilities is essential to meet the demands for more versatile and efficient AI. However, previous omni-models have insufficiently explored speech, neglecting its integration with multi-modality. We introduce Lyra, an efficient MLLM that enhances multimodal abilities, including advanced long-speech comprehension, sound understanding, cross-modality efficiency, and seamless speech interaction. To achieve efficiency and speech-centric capabilities, Lyra employs three strategies: (1) leveraging existing open-source large models and a proposed multi-modality LoRA to reduce training costs and data requirements; (2) using a latent multi-modality regularizer and extractor to strengthen the relationship between speech and other modalities, thereby enhancing model performance; and (3) constructing a high-quality, extensive dataset that includes 1.5M multi-modal (language, vision, audio) data samples and 12K long speech samples, enabling Lyra to handle complex long speech inputs and achieve more robust omni-cognition. Compared to other omni-methods, Lyra achieves state-of-the-art performance on various vision-language, vision-speech, and speech-language benchmarks, while also using fewer computational resources and less training data.
Mini-Gemini: Mining the Potential of Multi-modality Vision Language Models
Mar 27, 2024



In this work, we introduce Mini-Gemini, a simple and effective framework enhancing multi-modality Vision Language Models (VLMs). Despite the advancements in VLMs facilitating basic visual dialog and reasoning, a performance gap persists compared to advanced models like GPT-4 and Gemini. We try to narrow the gap by mining the potential of VLMs for better performance and any-to-any workflow from three aspects, i.e., high-resolution visual tokens, high-quality data, and VLM-guided generation. To enhance visual tokens, we propose to utilize an additional visual encoder for high-resolution refinement without increasing the visual token count. We further construct a high-quality dataset that promotes precise image comprehension and reasoning-based generation, expanding the operational scope of current VLMs. In general, Mini-Gemini further mines the potential of VLMs and empowers current frameworks with image understanding, reasoning, and generation simultaneously. Mini-Gemini supports a series of dense and MoE Large Language Models (LLMs) from 2B to 34B. It is demonstrated to achieve leading performance in several zero-shot benchmarks and even surpasses the developed private models. Code and models are available at https://github.com/dvlab-research/MiniGemini.
Decoupled Kullback-Leibler Divergence Loss
May 23, 2023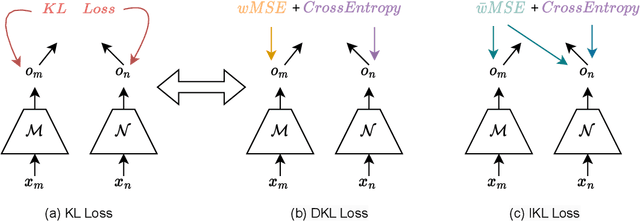
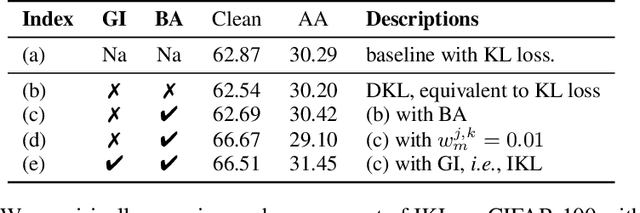
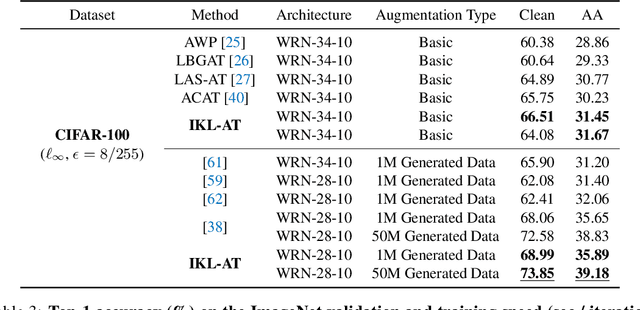
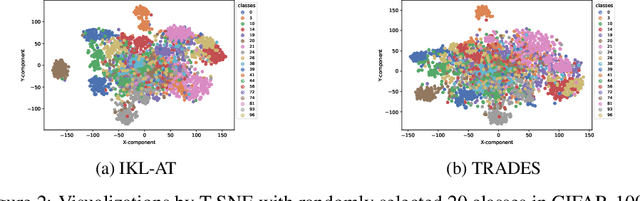
In this paper, we delve deeper into the Kullback-Leibler (KL) Divergence loss and observe that it is equivalent to the Doupled Kullback-Leibler (DKL) Divergence loss that consists of 1) a weighted Mean Square Error (wMSE) loss and 2) a Cross-Entropy loss incorporating soft labels. From our analysis of the DKL loss, we have identified two areas for improvement. Firstly, we address the limitation of DKL in scenarios like knowledge distillation by breaking its asymmetry property in training optimization. This modification ensures that the wMSE component is always effective during training, providing extra constructive cues. Secondly, we introduce global information into DKL for intra-class consistency regularization. With these two enhancements, we derive the Improved Kullback-Leibler (IKL) Divergence loss and evaluate its effectiveness by conducting experiments on CIFAR-10/100 and ImageNet datasets, focusing on adversarial training and knowledge distillation tasks. The proposed approach achieves new state-of-the-art performance on both tasks, demonstrating the substantial practical merits. Code and models will be available soon at https://github.com/jiequancui/DKL.
Understanding Imbalanced Semantic Segmentation Through Neural Collapse
Jan 03, 2023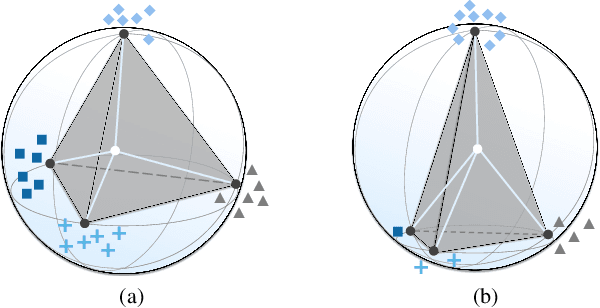
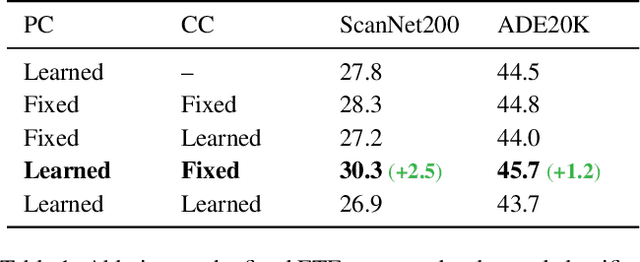
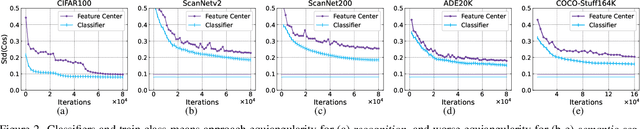
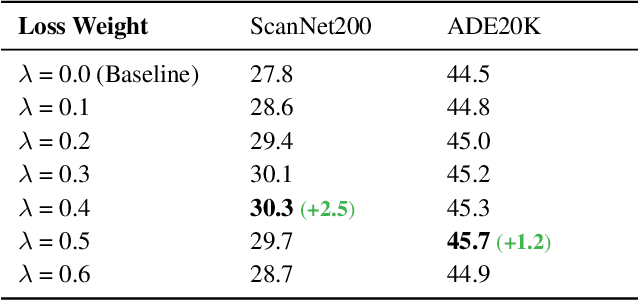
A recent study has shown a phenomenon called neural collapse in that the within-class means of features and the classifier weight vectors converge to the vertices of a simplex equiangular tight frame at the terminal phase of training for classification. In this paper, we explore the corresponding structures of the last-layer feature centers and classifiers in semantic segmentation. Based on our empirical and theoretical analysis, we point out that semantic segmentation naturally brings contextual correlation and imbalanced distribution among classes, which breaks the equiangular and maximally separated structure of neural collapse for both feature centers and classifiers. However, such a symmetric structure is beneficial to discrimination for the minor classes. To preserve these advantages, we introduce a regularizer on feature centers to encourage the network to learn features closer to the appealing structure in imbalanced semantic segmentation. Experimental results show that our method can bring significant improvements on both 2D and 3D semantic segmentation benchmarks. Moreover, our method ranks 1st and sets a new record (+6.8% mIoU) on the ScanNet200 test leaderboard. Code will be available at https://github.com/dvlab-research/Imbalanced-Learning.
Generalized Parametric Contrastive Learning
Sep 26, 2022
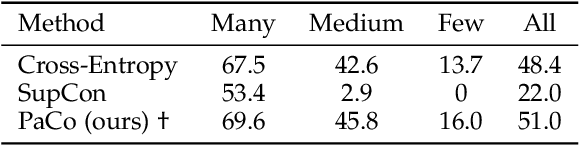
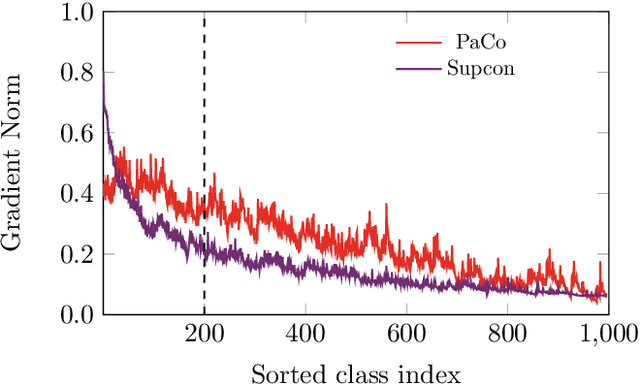
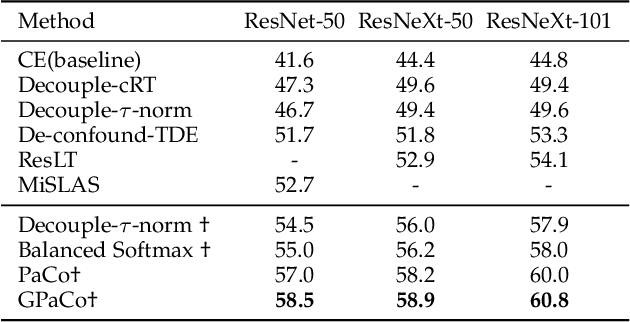
In this paper, we propose the Generalized Parametric Contrastive Learning (GPaCo/PaCo) which works well on both imbalanced and balanced data. Based on theoretical analysis, we observe that supervised contrastive loss tends to bias high-frequency classes and thus increases the difficulty of imbalanced learning. We introduce a set of parametric class-wise learnable centers to rebalance from an optimization perspective. Further, we analyze our GPaCo/PaCo loss under a balanced setting. Our analysis demonstrates that GPaCo/PaCo can adaptively enhance the intensity of pushing samples of the same class close as more samples are pulled together with their corresponding centers and benefit hard example learning. Experiments on long-tailed benchmarks manifest the new state-of-the-art for long-tailed recognition. On full ImageNet, models from CNNs to vision transformers trained with GPaCo loss show better generalization performance and stronger robustness compared with MAE models. Moreover, GPaCo can be applied to the semantic segmentation task and obvious improvements are observed on the 4 most popular benchmarks. Our code is available at https://github.com/dvlab-research/Parametric-Contrastive-Learning.
Region Rebalance for Long-Tailed Semantic Segmentation
Apr 05, 2022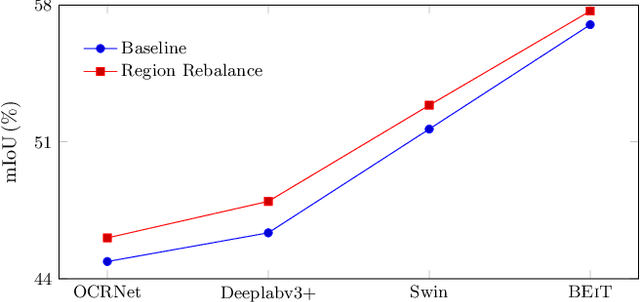

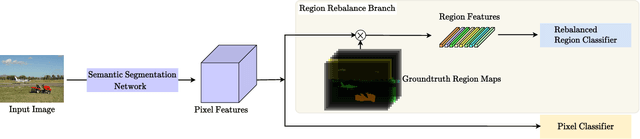

In this paper, we study the problem of class imbalance in semantic segmentation. We first investigate and identify the main challenges of addressing this issue through pixel rebalance. Then a simple and yet effective region rebalance scheme is derived based on our analysis. In our solution, pixel features belonging to the same class are grouped into region features, and a rebalanced region classifier is applied via an auxiliary region rebalance branch during training. To verify the flexibility and effectiveness of our method, we apply the region rebalance module into various semantic segmentation methods, such as Deeplabv3+, OCRNet, and Swin. Our strategy achieves consistent improvement on the challenging ADE20K and COCO-Stuff benchmark. In particular, with the proposed region rebalance scheme, state-of-the-art BEiT receives +0.7% gain in terms of mIoU on the ADE20K val set.