 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARPO:End-to-End Policy Optimization for GUI Agents with Experience Replay
May 22, 2025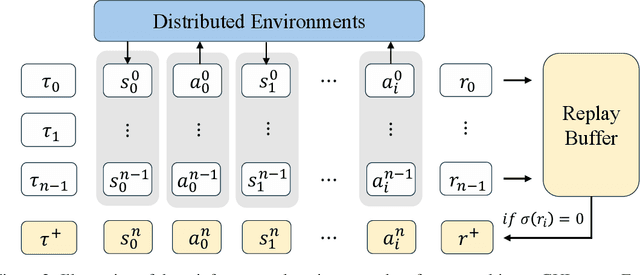
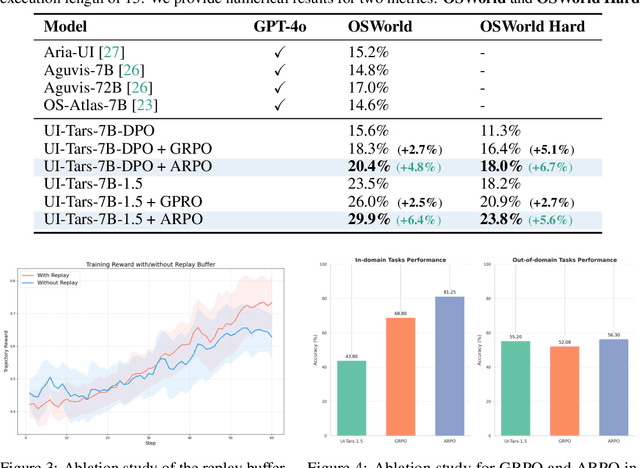
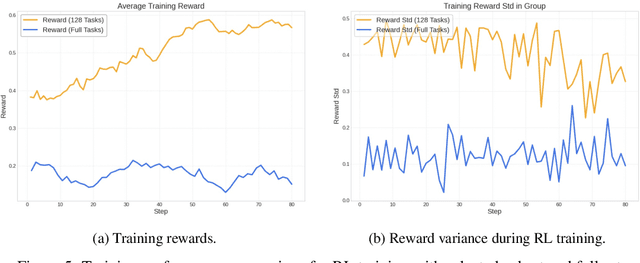
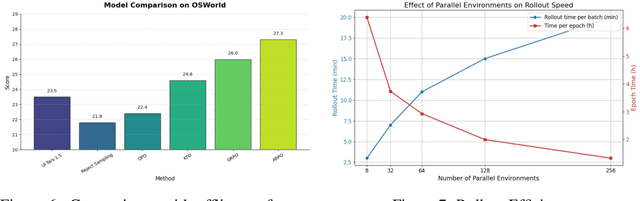
Training large language models (LLMs) as interactive agents for controlling graphical user interfaces (GUIs) presents a unique challenge to optimize long-horizon action sequences with multimodal feedback from complex environments. While recent works have advanced multi-turn reinforcement learning (RL) for reasoning and tool-using capabilities in LLMs, their application to GUI-based agents remains relatively underexplored due to the difficulty of sparse rewards, delayed feedback, and high rollout costs. In this paper, we investigate end-to-end policy optimization for vision-language-based GUI agents with the aim of improving performance on complex, long-horizon computer tasks. We propose Agentic Replay Policy Optimization (ARPO), an end-to-end RL approach that augments Group Relative Policy Optimization (GRPO) with a replay buffer to reuse the successful experience across training iterations. To further stabilize the training process, we propose a task selection strategy that filters tasks based on baseline agent performance, allowing the agent to focus on learning from informative interactions. Additionally, we compare ARPO with offline preference optimization approaches, highlighting the advantages of policy-based methods in GUI environments. Experiments on the OSWorld benchmark demonstrate that ARPO achieves competitive results, establishing a new performance baseline for LLM-based GUI agents trained via reinforcement learning. Our findings underscore the effectiveness of reinforcement learning for training multi-turn, vision-language GUI agents capable of managing complex real-world UI interactions. Codes and models:https://github.com/dvlab-research/ARPO.git.
STEVE: AStep Verification Pipeline for Computer-use Agent Training
Mar 16, 2025Developing AI agents to autonomously manipulate graphical user interfaces is a long challenging task. Recent advances in data scaling law inspire us to train computer-use agents with a scaled instruction set, yet using behavior cloning to train agents still requires immense high-quality trajectories. To meet the scalability need, we designed STEVE, a step verification pipeline for computer-use agent training. First, we establish a large instruction set for computer-use agents and collect trajectory data with some suboptimal agents. GPT-4o is used to verify the correctness of each step in the trajectories based on the screens before and after the action execution, assigning each step with a binary label. Last, we adopt the Kahneman and Tversky Optimization to optimize the agent from the binary stepwise labels. Extensive experiments manifest that our agent outperforms supervised finetuning by leveraging both positive and negative actions within a trajectory. Also, STEVE enables us to train a 7B vision-language model as a computer-use agent, achieving leading performance in the challenging live desktop environment WinAgentArena with great efficiency at a reduced cost. Code and data: https://github.com/FanbinLu/STEVE.
Seg-Zero: Reasoning-Chain Guided Segmentation via Cognitive Reinforcement
Mar 09, 2025Traditional methods for reasoning segmentation rely on supervised fine-tuning with categorical labels and simple descriptions, limiting its out-of-domain generalization and lacking explicit reasoning processes. To address these limitations, we propose Seg-Zero, a novel framework that demonstrates remarkable generalizability and derives explicit chain-of-thought reasoning through cognitive reinforcement. Seg-Zero introduces a decoupled architecture consisting of a reasoning model and a segmentation model. The reasoning model interprets user intentions, generates explicit reasoning chains, and produces positional prompts, which are subsequently used by the segmentation model to generate precious pixel-level masks. We design a sophisticated reward mechanism that integrates both format and accuracy rewards to effectively guide optimization directions. Trained exclusively via reinforcement learning with GRPO and without explicit reasoning data, Seg-Zero achieves robust zero-shot generalization and exhibits emergent test-time reasoning capabilities. Experiments show that Seg-Zero-7B achieves a zero-shot performance of 57.5 on the ReasonSeg benchmark, surpassing the prior LISA-7B by 18\%. This significant improvement highlights Seg-Zero's ability to generalize across domains while presenting an explicit reasoning process. Code is available at https://github.com/dvlab-research/Seg-Zero.
Spherical Transformer for LiDAR-based 3D Recognition
Mar 22, 2023



LiDAR-based 3D point cloud recognition has benefited various applications. Without specially considering the LiDAR point distribution, most current methods suffer from information disconnection and limited receptive field, especially for the sparse distant points. In this work, we study the varying-sparsity distribution of LiDAR points and present SphereFormer to directly aggregate information from dense close points to the sparse distant ones. We design radial window self-attention that partitions the space into multiple non-overlapping narrow and long windows. It overcomes the disconnection issue and enlarges the receptive field smoothly and dramatically, which significantly boosts the performance of sparse distant points. Moreover, to fit the narrow and long windows, we propose exponential splitting to yield fine-grained position encoding and dynamic feature selection to increase model representation ability. Notably, our method ranks 1st on both nuScenes and SemanticKITTI semantic segmentation benchmarks with 81.9% and 74.8% mIoU, respectively. Also, we achieve the 3rd place on nuScenes object detection benchmark with 72.8% NDS and 68.5% mAP. Code is available at https://github.com/dvlab-research/SphereFormer.git.
Boosting Single-Frame 3D Object Detection by Simulating Multi-Frame Point Clouds
Jul 12, 2022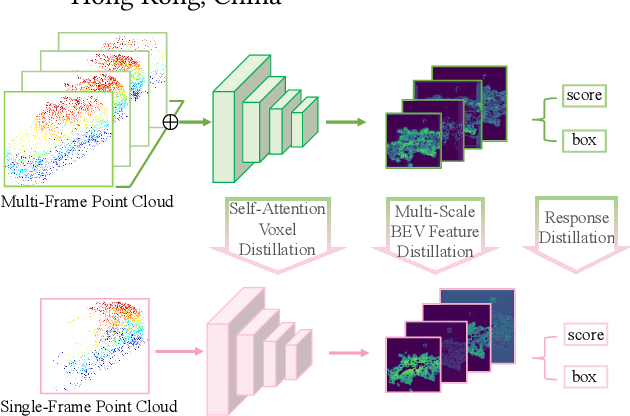
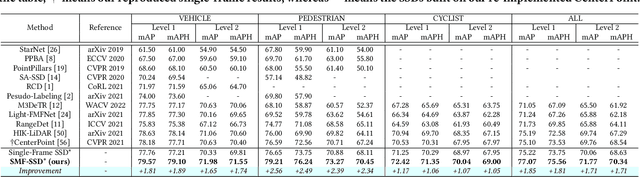
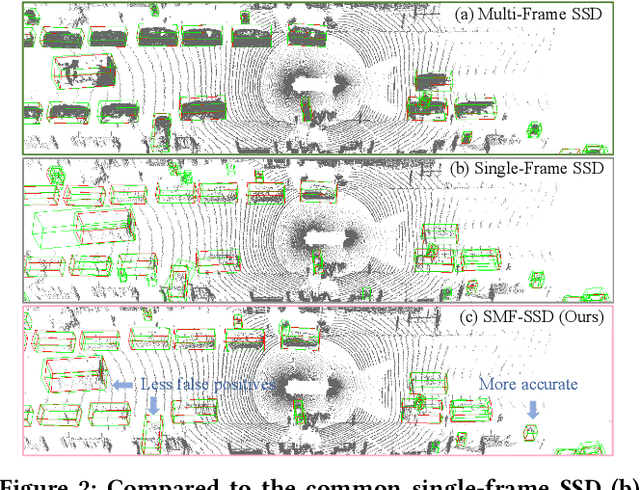

To boost a detector for single-frame 3D object detection, we present a new approach to train it to simulate features and responses following a detector trained on multi-frame point clouds. Our approach needs multi-frame point clouds only when training the single-frame detector, and once trained, it can detect objects with only single-frame point clouds as inputs during the inference. We design a novel Simulated Multi-Frame Single-Stage object Detector (SMF-SSD) framework to realize the approach: multi-view dense object fusion to densify ground-truth objects to generate a multi-frame point cloud; self-attention voxel distillation to facilitate one-to-many knowledge transfer from multi- to single-frame voxels; multi-scale BEV feature distillation to transfer knowledge in low-level spatial and high-level semantic BEV features; and adaptive response distillation to activate single-frame responses of high confidence and accurate localization. Experimental results on the Waymo test set show that our SMF-SSD consistently outperforms all state-of-the-art single-frame 3D object detectors for all object classes of difficulty levels 1 and 2 in terms of both mAP and mAPH.