 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting Single-Frame 3D Object Detection by Simulating Multi-Frame Point Clouds
Jul 12, 2022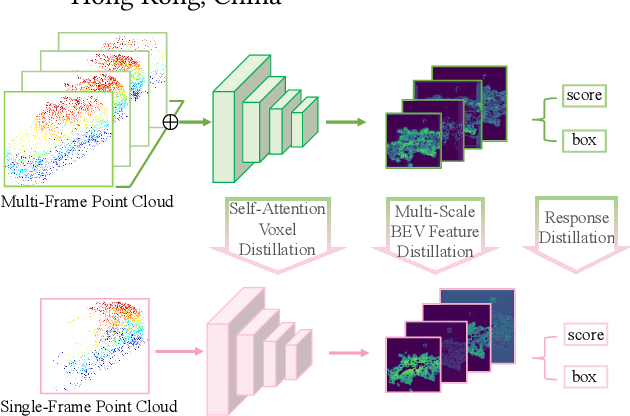
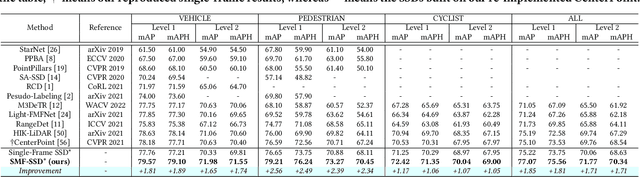
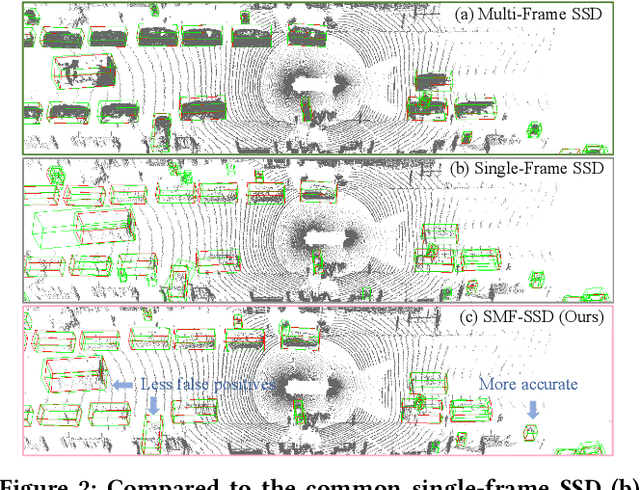

To boost a detector for single-frame 3D object detection, we present a new approach to train it to simulate features and responses following a detector trained on multi-frame point clouds. Our approach needs multi-frame point clouds only when training the single-frame detector, and once trained, it can detect objects with only single-frame point clouds as inputs during the inference. We design a novel Simulated Multi-Frame Single-Stage object Detector (SMF-SSD) framework to realize the approach: multi-view dense object fusion to densify ground-truth objects to generate a multi-frame point cloud; self-attention voxel distillation to facilitate one-to-many knowledge transfer from multi- to single-frame voxels; multi-scale BEV feature distillation to transfer knowledge in low-level spatial and high-level semantic BEV features; and adaptive response distillation to activate single-frame responses of high confidence and accurate localization. Experimental results on the Waymo test set show that our SMF-SSD consistently outperforms all state-of-the-art single-frame 3D object detectors for all object classes of difficulty levels 1 and 2 in terms of both mAP and mAPH.
Boosting 3D Object Detection by Simulating Multimodality on Point Clouds
Jun 30, 2022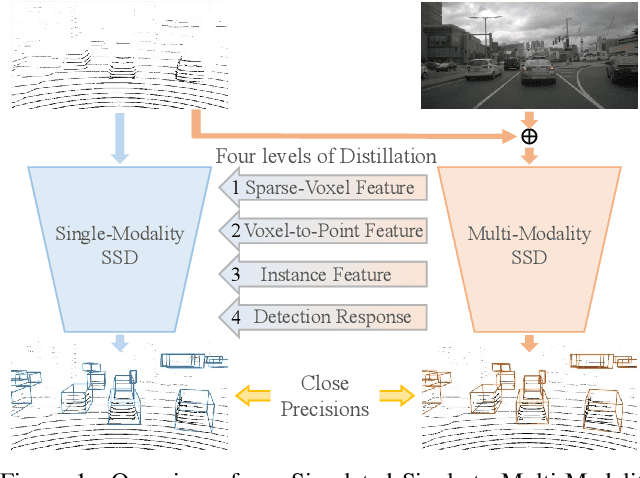
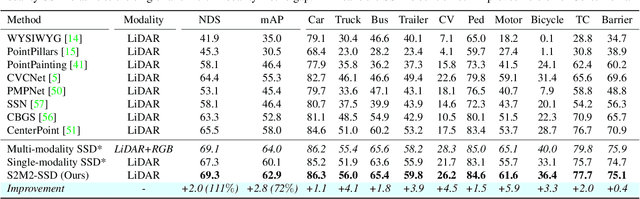

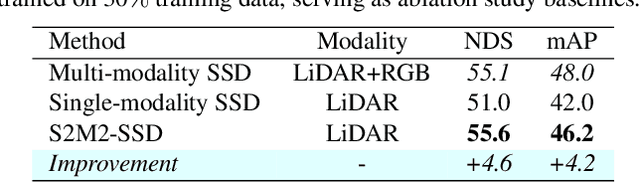
This paper presents a new approach to boost a single-modality (LiDAR) 3D object detector by teaching it to simulate features and responses that follow a multi-modality (LiDAR-image) detector. The approach needs LiDAR-image data only when training the single-modality detector, and once well-trained, it only needs LiDAR data at inference. We design a novel framework to realize the approach: response distillation to focus on the crucial response samples and avoid the background samples; sparse-voxel distillation to learn voxel semantics and relations from the estimated crucial voxels; a fine-grained voxel-to-point distillation to better attend to features of small and distant objects; and instance distillation to further enhance the deep-feature consistency. Experimental results on the nuScenes dataset show that our approach outperforms all SOTA LiDAR-only 3D detectors and even surpasses the baseline LiDAR-image detector on the key NDS metric, filling 72% mAP gap between the single- and multi-modality detectors.
SE-SSD: Self-Ensembling Single-Stage Object Detector From Point Cloud
Apr 20, 2021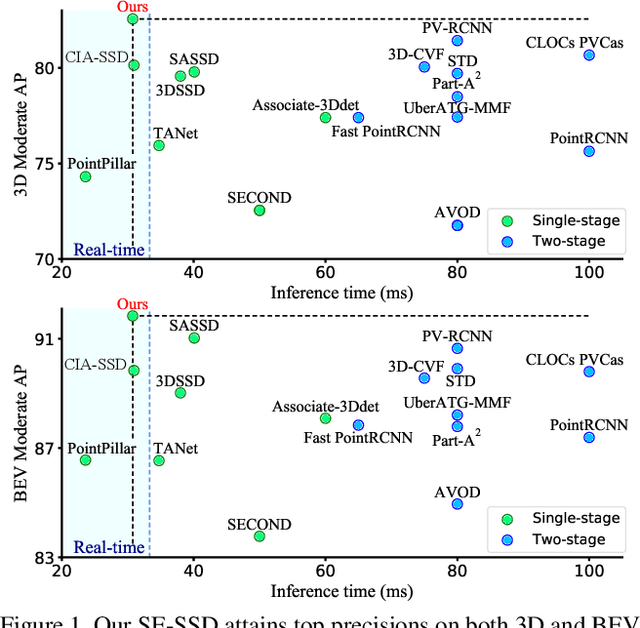
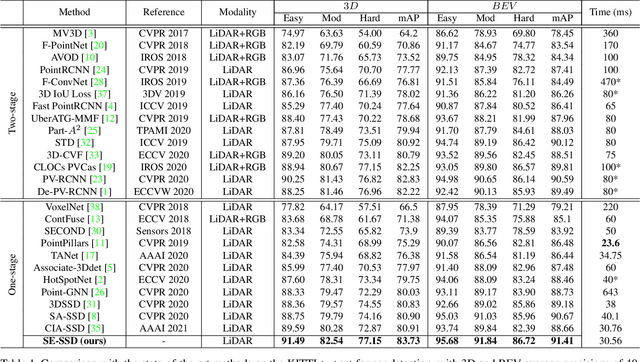
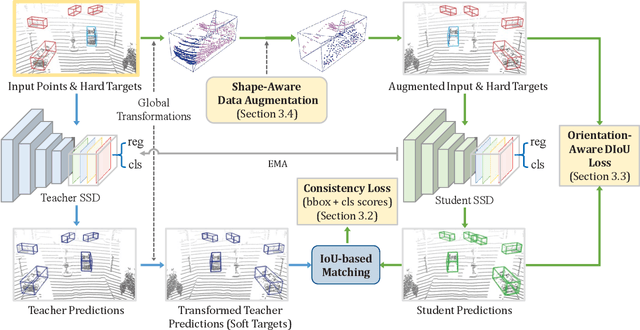
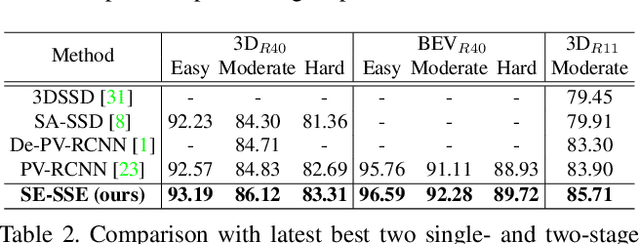
We present Self-Ensembling Single-Stage object Detector (SE-SSD) for accurate and efficient 3D object detection in outdoor point clouds. Our key focus is on exploiting both soft and hard targets with our formulated constraints to jointly optimize the model, without introducing extra computation in the inference. Specifically, SE-SSD contains a pair of teacher and student SSDs, in which we design an effective IoU-based matching strategy to filter soft targets from the teacher and formulate a consistency loss to align student predictions with them. Also, to maximize the distilled knowledge for ensembling the teacher, we design a new augmentation scheme to produce shape-aware augmented samples to train the student, aiming to encourage it to infer complete object shapes. Lastly, to better exploit hard targets, we design an ODIoU loss to supervise the student with constraints on the predicted box centers and orientations. Our SE-SSD attains top performance compared with all prior published works. Also, it attains top precisions for car detection in the KITTI benchmark (ranked 1st and 2nd on the BEV and 3D leaderboards, respectively) with an ultra-high inference speed. The code is available at https://github.com/Vegeta2020/SE-SSD.
CIA-SSD: Confident IoU-Aware Single-Stage Object Detector From Point Cloud
Dec 05, 2020
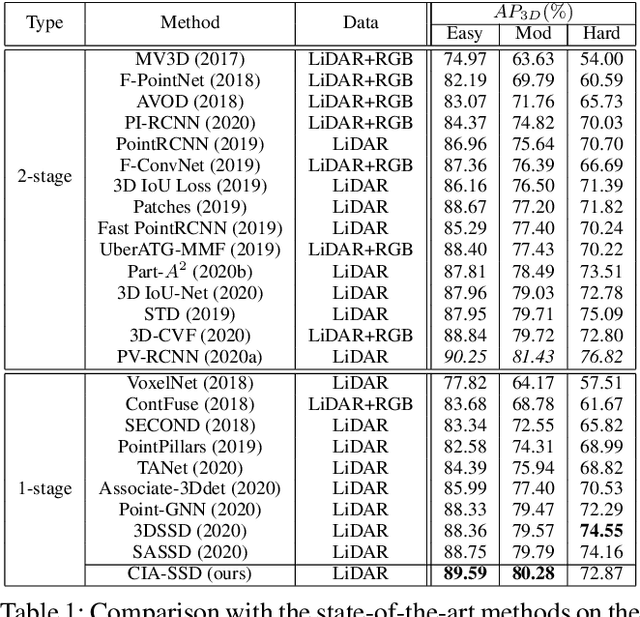
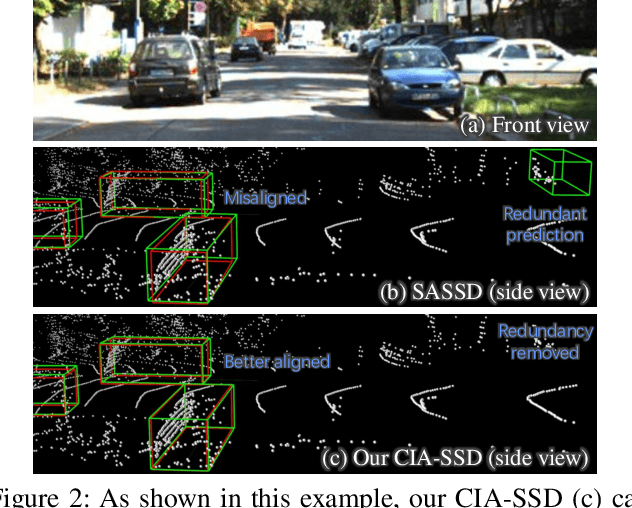
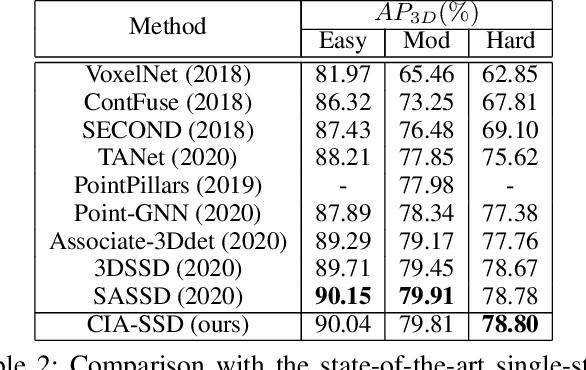
Existing single-stage detectors for locating objects in point clouds often treat object localization and category classification as separate tasks, so the localization accuracy and classification confidence may not well align. To address this issue, we present a new single-stage detector named the Confident IoU-Aware Single-Stage object Detector (CIA-SSD). First, we design the lightweight Spatial-Semantic Feature Aggregation module to adaptively fuse high-level abstract semantic features and low-level spatial features for accurate predictions of bounding boxes and classification confidence. Also, the predicted confidence is further rectified with our designed IoU-aware confidence rectification module to make the confidence more consistent with the localization accuracy. Based on the rectified confidence, we further formulate the Distance-variant IoU-weighted NMS to obtain smoother regressions and avoid redundant predictions. We experiment CIA-SSD on 3D car detection in the KITTI test set and show that it attains top performance in terms of the official ranking metric (moderate AP 80.28%) and above 32 FPS inference speed, outperforming all prior single-stage detectors. The code is available at https://github.com/Vegeta2020/CIA-SSD.
Skeleton-Based Relational Modeling for Action Recognition
Jul 13, 2018
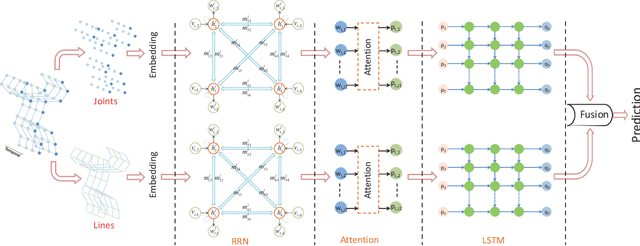
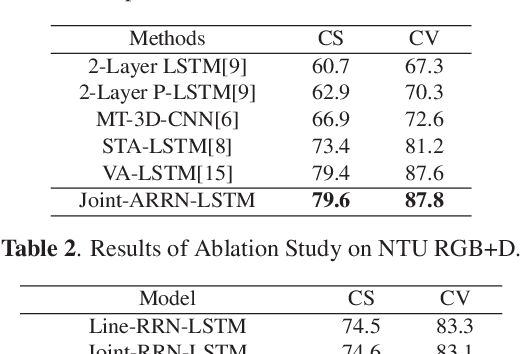

With the fast development of effective and low-cost human skeleton capture systems, skeleton-based action recognition has attracted much attention recently. Most existing methods use Convolutional Neural Network(CNN) and Recurrent Neural Network(RNN) to extract spatio-temporal information embedded in the skeleton sequences for action recognition. However, these approaches are limited in the ability of relational modeling in a single skeleton, due to the loss of important structural information when converting the raw skeleton data to adapt to the CNN or RNN input. In this paper, we propose an Attentional Recurrent Relational Network-LSTM(ARRN-LSTM) to simultaneously model spatial configurations and temporal dynamics in skeletons for action recognition. The spatial patterns embedded in a single skeleton are learned by a Recurrent Relational Network, followed by a multi-layer LSTM to extract temporal features in the skeleton sequences. To exploit the complementarity between different geometries in the skeleton for sufficient relational modeling, we design a two-stream architecture to learn the relationship among joints and explore the underlying patterns among lines simultaneously. We also introduce an adaptive attentional module for focusing on potential discriminative parts of the skeleton towards a certain action. Extensive experiments are performed on several popular action recognition datasets and the results show that the proposed approach achieves competitive results with the state-of-the-art methods.