 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkeleton-Based Relational Modeling for Action Recognition
Paper and Code
Jul 13, 2018
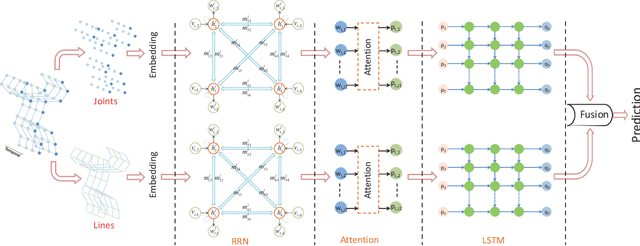
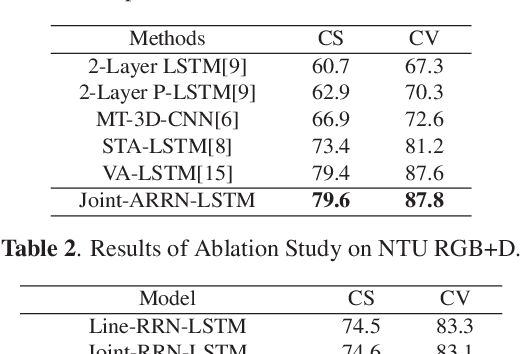

With the fast development of effective and low-cost human skeleton capture systems, skeleton-based action recognition has attracted much attention recently. Most existing methods use Convolutional Neural Network(CNN) and Recurrent Neural Network(RNN) to extract spatio-temporal information embedded in the skeleton sequences for action recognition. However, these approaches are limited in the ability of relational modeling in a single skeleton, due to the loss of important structural information when converting the raw skeleton data to adapt to the CNN or RNN input. In this paper, we propose an Attentional Recurrent Relational Network-LSTM(ARRN-LSTM) to simultaneously model spatial configurations and temporal dynamics in skeletons for action recognition. The spatial patterns embedded in a single skeleton are learned by a Recurrent Relational Network, followed by a multi-layer LSTM to extract temporal features in the skeleton sequences. To exploit the complementarity between different geometries in the skeleton for sufficient relational modeling, we design a two-stream architecture to learn the relationship among joints and explore the underlying patterns among lines simultaneously. We also introduce an adaptive attentional module for focusing on potential discriminative parts of the skeleton towards a certain action. Extensive experiments are performed on several popular action recognition datasets and the results show that the proposed approach achieves competitive results with the state-of-the-art methods.