 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo-OPD: Efficient Post-Training of Multimodal Large Language Models for Temporal Video Grounding via On-Policy Distillation
Feb 03, 2026Reinforcement learning has emerged as a principled post-training paradigm for Temporal Video Grounding (TVG) due to its on-policy optimization, yet existing GRPO-based methods remain fundamentally constrained by sparse reward signals and substantial computational overhead. We propose Video-OPD, an efficient post-training framework for TVG inspired by recent advances in on-policy distillation. Video-OPD optimizes trajectories sampled directly from the current policy, thereby preserving alignment between training and inference distributions, while a frontier teacher supplies dense, token-level supervision via a reverse KL divergence objective. This formulation preserves the on-policy property critical for mitigating distributional shift, while converting sparse, episode-level feedback into fine-grained, step-wise learning signals. Building on Video-OPD, we introduce Teacher-Validated Disagreement Focusing (TVDF), a lightweight training curriculum that iteratively prioritizes trajectories that are both teacher-reliable and maximally informative for the student, thereby improving training efficiency. Empirical results demonstrate that Video-OPD consistently outperforms GRPO while achieving substantially faster convergence and lower computational cost, establishing on-policy distillation as an effective alternative to conventional reinforcement learning for TVG.
Xiaomi MiMo-VL-Miloco Technical Report
Dec 22, 2025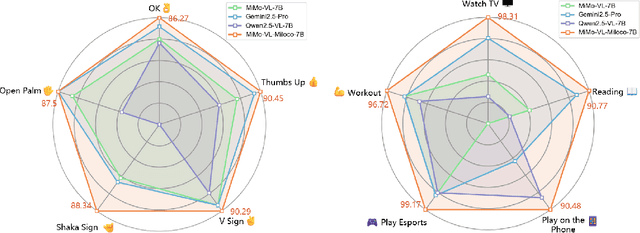
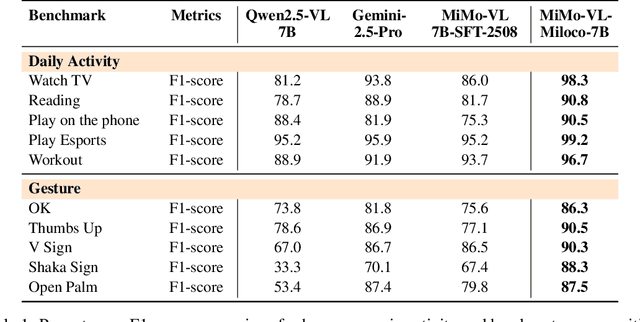

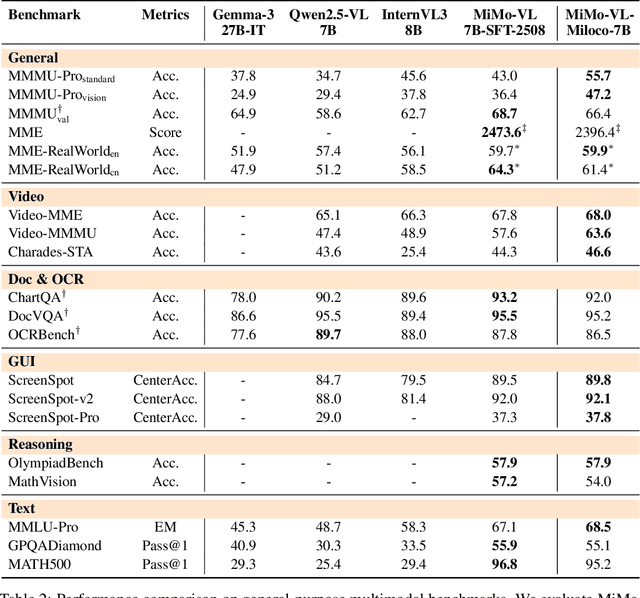
We open-source MiMo-VL-Miloco-7B and its quantized variant MiMo-VL-Miloco-7B-GGUF, a pair of home-centric vision-language models that achieve strong performance on both home-scenario understanding and general multimodal reasoning. Built on the MiMo-VL-7B backbone, MiMo-VL-Miloco-7B is specialized for smart-home environments, attaining leading F1 scores on gesture recognition and common home-scenario understanding, while also delivering consistent gains across video benchmarks such as Video-MME, Video-MMMU, and Charades-STA, as well as language understanding benchmarks including MMMU-Pro and MMLU-Pro. In our experiments, MiMo-VL-Miloco-7B outperforms strong closed-source and open-source baselines on home-scenario understanding and several multimodal reasoning benchmarks. To balance specialization and generality, we design a two-stage training pipeline that combines supervised fine-tuning with reinforcement learning based on Group Relative Policy Optimization, leveraging efficient multi-domain data. We further incorporate chain-of-thought supervision and token-budget-aware reasoning, enabling the model to learn knowledge in a data-efficient manner while also performing reasoning efficiently. Our analysis shows that targeted home-scenario training not only enhances activity and gesture understanding, but also improves text-only reasoning with only modest trade-offs on document-centric tasks. Model checkpoints, quantized GGUF weights, and our home-scenario evaluation toolkit are publicly available at https://github.com/XiaoMi/xiaomi-mimo-vl-miloco to support research and deployment in real-world smart-home applications.
REVISOR: Beyond Textual Reflection, Towards Multimodal Introspective Reasoning in Long-Form Video Understanding
Nov 17, 2025Self-reflection mechanisms that rely on purely text-based rethinking processes perform well in most multimodal tasks. However, when directly applied to long-form video understanding scenarios, they exhibit clear limitations. The fundamental reasons for this lie in two points: (1)long-form video understanding involves richer and more dynamic visual input, meaning rethinking only the text information is insufficient and necessitates a further rethinking process specifically targeting visual information; (2) purely text-based reflection mechanisms lack cross-modal interaction capabilities, preventing them from fully integrating visual information during reflection. Motivated by these insights, we propose REVISOR (REflective VIsual Segment Oriented Reasoning), a novel framework for tool-augmented multimodal reflection. REVISOR enables MLLMs to collaboratively construct introspective reflection processes across textual and visual modalities, significantly enhancing their reasoning capability for long-form video understanding. To ensure that REVISOR can learn to accurately review video segments highly relevant to the question during reinforcement learning, we designed the Dual Attribution Decoupled Reward (DADR) mechanism. Integrated into the GRPO training strategy, this mechanism enforces causal alignment between the model's reasoning and the selected video evidence. Notably, the REVISOR framework significantly enhances long-form video understanding capability of MLLMs without requiring supplementary supervised fine-tuning or external models, achieving impressive results on four benchmarks including VideoMME, LongVideoBench, MLVU, and LVBench.
EgoDTM: Towards 3D-Aware Egocentric Video-Language Pretraining
Mar 19, 2025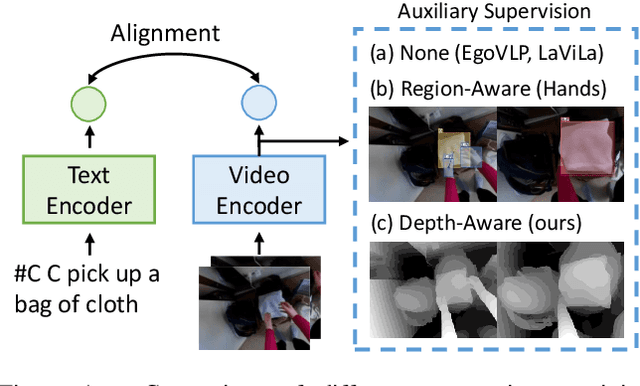
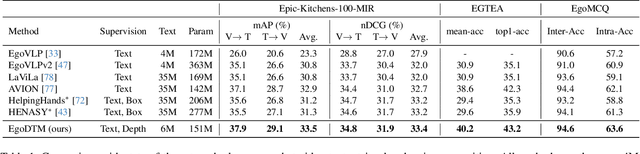
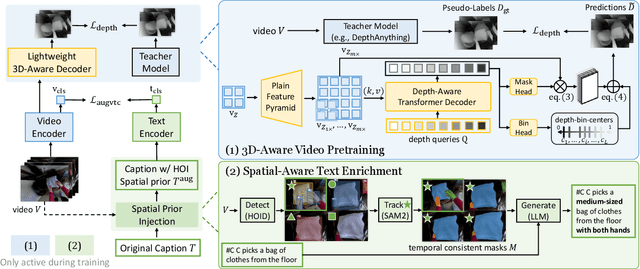

Egocentric video-language pretraining has significantly advanced video representation learning. Humans perceive and interact with a fully 3D world, developing spatial awareness that extends beyond text-based understanding. However, most previous works learn from 1D text or 2D visual cues, such as bounding boxes, which inherently lack 3D understanding. To bridge this gap, we introduce EgoDTM, an Egocentric Depth- and Text-aware Model, jointly trained through large-scale 3D-aware video pretraining and video-text contrastive learning. EgoDTM incorporates a lightweight 3D-aware decoder to efficiently learn 3D-awareness from pseudo depth maps generated by depth estimation models. To further facilitate 3D-aware video pretraining, we enrich the original brief captions with hand-object visual cues by organically combining several foundation models. Extensive experiments demonstrate EgoDTM's superior performance across diverse downstream tasks, highlighting its superior 3D-aware visual understanding. Our code will be released at https://github.com/xuboshen/EgoDTM.
TimeZero: Temporal Video Grounding with Reasoning-Guided LVLM
Mar 17, 2025We introduce TimeZero, a reasoning-guided LVLM designed for the temporal video grounding (TVG) task. This task requires precisely localizing relevant video segments within long videos based on a given language query. TimeZero tackles this challenge by extending the inference process, enabling the model to reason about video-language relationships solely through reinforcement learning. To evaluate the effectiveness of TimeZero, we conduct experiments on two benchmarks, where TimeZero achieves state-of-the-art performance on Charades-STA. Code is available at https://github.com/www-Ye/TimeZero.
EgoNCE++: Do Egocentric Video-Language Models Really Understand Hand-Object Interactions?
May 28, 2024Egocentric video-language pretraining is a crucial paradigm to advance the learning of egocentric hand-object interactions (EgoHOI). Despite the great success on existing testbeds, these benchmarks focus more on closed-set visual concepts or limited scenarios. Due to the occurrence of diverse EgoHOIs in the real world, we propose an open-vocabulary benchmark named EgoHOIBench to reveal the diminished performance of current egocentric video-language models (EgoVLM) on fined-grained concepts, indicating that these models still lack a full spectrum of egocentric understanding. We attribute this performance gap to insufficient fine-grained supervision and strong bias towards understanding objects rather than temporal dynamics in current methods. To tackle these issues, we introduce a novel asymmetric contrastive objective for EgoHOI named EgoNCE++. For video-to-text loss, we enhance text supervision through the generation of negative captions by leveraging the in-context learning of large language models to perform HOI-related word substitution. For text-to-video loss, we propose an object-centric positive video sampling strategy that aggregates video representations by the same nouns. Our extensive experiments demonstrate that EgoNCE++ significantly boosts open-vocabulary HOI recognition, multi-instance retrieval, and action recognition tasks across various egocentric models, with improvements of up to +26.55%. Our code is available at https://github.com/xuboshen/EgoNCEpp.
POV: Prompt-Oriented View-Agnostic Learning for Egocentric Hand-Object Interaction in the Multi-View World
Mar 09, 2024We humans are good at translating third-person observations of hand-object interactions (HOI) into an egocentric view. However, current methods struggle to replicate this ability of view adaptation from third-person to first-person. Although some approaches attempt to learn view-agnostic representation from large-scale video datasets, they ignore the relationships among multiple third-person views. To this end, we propose a Prompt-Oriented View-agnostic learning (POV) framework in this paper, which enables this view adaptation with few egocentric videos. Specifically, We introduce interactive masking prompts at the frame level to capture fine-grained action information, and view-aware prompts at the token level to learn view-agnostic representation. To verify our method, we establish two benchmarks for transferring from multiple third-person views to the egocentric view. Our extensive experiments on these benchmarks demonstrate the efficiency and effectiveness of our POV framework and prompt tuning techniques in terms of view adaptation and view generalization. Our code is available at \url{https://github.com/xuboshen/pov_acmmm2023}.
* Accepted by ACM MM 2023. Project page: https://xuboshen.github.io/
SPAFormer: Sequential 3D Part Assembly with Transformers
Mar 09, 2024



We introduce SPAFormer, an innovative model designed to overcome the combinatorial explosion challenge in the 3D Part Assembly (3D-PA) task. This task requires accurate prediction of each part's pose and shape in sequential steps, and as the number of parts increases, the possible assembly combinations increase exponentially, leading to a combinatorial explosion that severely hinders the efficacy of 3D-PA. SPAFormer addresses this problem by leveraging weak constraints from assembly sequences, effectively reducing the solution space's complexity. Since assembly part sequences convey construction rules similar to sentences being structured through words, our model explores both parallel and autoregressive generation. It further enhances assembly through knowledge enhancement strategies that utilize the attributes of parts and their sequence information, enabling it to capture the inherent assembly pattern and relationships among sequentially ordered parts. We also construct a more challenging benchmark named PartNet-Assembly covering 21 varied categories to more comprehensively validate the effectiveness of SPAFormer. Extensive experiments demonstrate the superior generalization capabilities of SPAFormer, particularly with multi-tasking and in scenarios requiring long-horizon assembly. Codes and model weights will be released at \url{https://github.com/xuboshen/SPAFormer}.
Real-Time Video Super-Resolution on Smartphones with Deep Learning, Mobile AI 2021 Challenge: Report
May 17, 2021

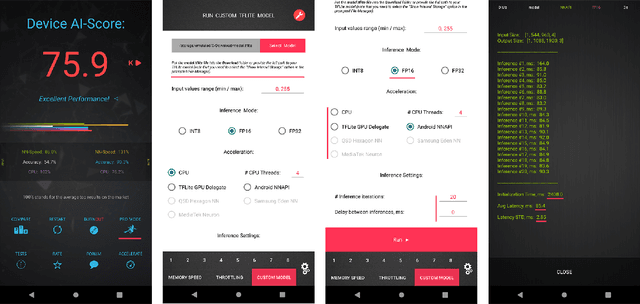
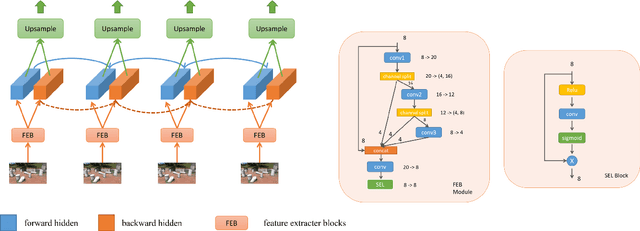
Video super-resolution has recently become one of the most important mobile-related problems due to the rise of video communication and streaming services. While many solutions have been proposed for this task, the majority of them are too computationally expensive to run on portable devices with limited hardware resources. To address this problem, we introduce the first Mobile AI challenge, where the target is to develop an end-to-end deep learning-based video super-resolution solutions that can achieve a real-time performance on mobile GPUs. The participants were provided with the REDS dataset and trained their models to do an efficient 4X video upscaling. The runtime of all models was evaluated on the OPPO Find X2 smartphone with the Snapdragon 865 SoC capable of accelerating floating-point networks on its Adreno GPU. The proposed solutions are fully compatible with any mobile GPU and can upscale videos to HD resolution at up to 80 FPS while demonstrating high fidelity results. A detailed description of all models developed in the challenge is provided in this paper.