 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Foundational Skills Influence VLM-based Embodied Agents:A Native Perspective
Feb 24, 2026Recent advances in vision-language models (VLMs) have shown promise for human-level embodied intelligence. However, existing benchmarks for VLM-driven embodied agents often rely on high-level commands or discretized action spaces, which are non-native settings that differ markedly from real-world control. In addition, current benchmarks focus primarily on high-level tasks and lack joint evaluation and analysis at both low and high levels. To address these limitations, we present NativeEmbodied, a challenging benchmark for VLM-driven embodied agents that uses a unified, native low-level action space. Built on diverse simulated scenes, NativeEmbodied includes three representative high-level tasks in complex scenarios to evaluate overall performance. For more detailed analysis, we further decouple the skills required by complex tasks and construct four types of low-level tasks, each targeting a fundamental embodied skill. This joint evaluation across task and skill granularities enables fine-grained assessment of embodied agents. Experiments with state-of-the-art VLMs reveal clear deficiencies in several fundamental embodied skills, and further analysis shows that these bottlenecks significantly limit performance on high-level tasks. NativeEmbodied highlights key challenges for current VLM-driven embodied agents and provides insights to guide future research.
Deep Models, Shallow Alignment: Uncovering the Granularity Mismatch in Neural Decoding
Jan 29, 2026Neural visual decoding is a central problem in brain computer interface research, aiming to reconstruct human visual perception and to elucidate the structure of neural representations. However, existing approaches overlook a fundamental granularity mismatch between human and machine vision, where deep vision models emphasize semantic invariance by suppressing local texture information, whereas neural signals preserve an intricate mixture of low-level visual attributes and high-level semantic content. To address this mismatch, we propose Shallow Alignment, a novel contrastive learning strategy that aligns neural signals with intermediate representations of visual encoders rather than their final outputs, thereby striking a better balance between low-level texture details and high-level semantic features. Extensive experiments across multiple benchmarks demonstrate that Shallow Alignment significantly outperforms standard final-layer alignment, with performance gains ranging from 22% to 58% across diverse vision backbones. Notably, our approach effectively unlocks the scaling law in neural visual decoding, enabling decoding performance to scale predictably with the capacity of pre-trained vision backbones. We further conduct systematic empirical analyses to shed light on the mechanisms underlying the observed performance gains.
Position-Prior-Guided Network for System Matrix Super-Resolution in Magnetic Particle Imaging
Nov 08, 2025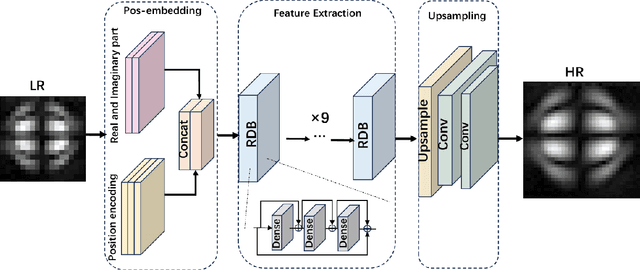
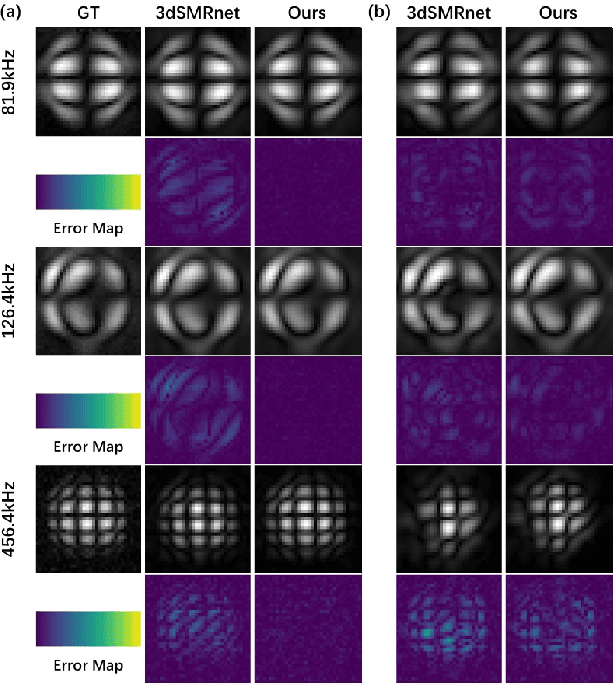
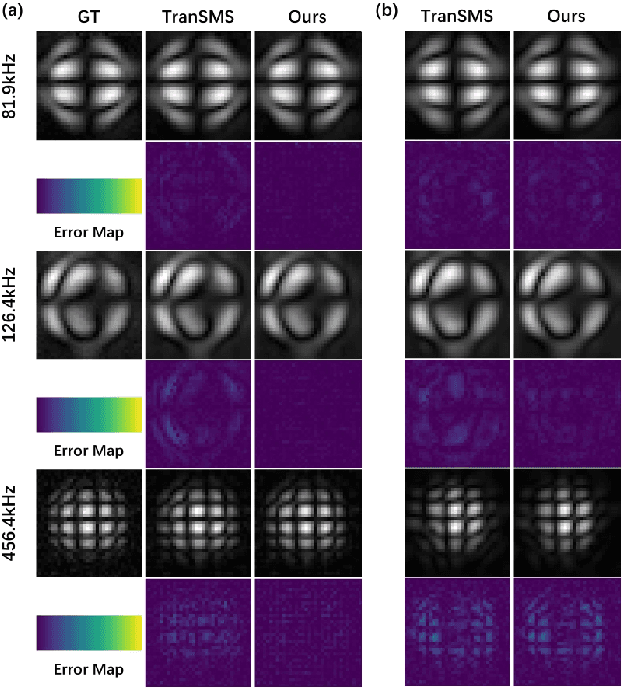
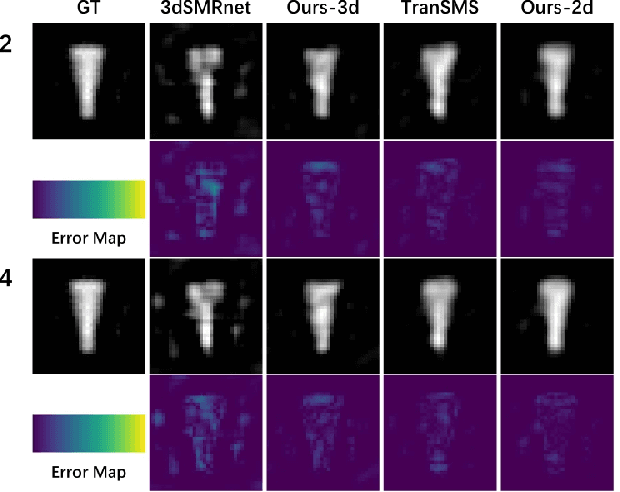
Magnetic Particle Imaging (MPI) is a novel medical imaging modality. One of the established methods for MPI reconstruction is based on the System Matrix (SM). However, the calibration of the SM is often time-consuming and requires repeated measurements whenever the system parameters change. Current methodologies utilize deep learning-based super-resolution (SR) techniques to expedite SM calibration; nevertheless, these strategies do not fully exploit physical prior knowledge associated with the SM, such as symmetric positional priors. Consequently, we integrated positional priors into existing frameworks for SM calibration. Underpinned by theoretical justification, we empirically validated the efficacy of incorporating positional priors through experiments involving both 2D and 3D SM SR methods.
Hunyuan-MT Technical Report
Sep 05, 2025



In this report, we introduce Hunyuan-MT-7B, our first open-source multilingual translation model, which supports bidirectional translation across 33 major languages and places a special emphasis on translation between Mandarin and several ethnic minority languages as well as dialects. Furthermore, to serve and address diverse translation scenarios and enhance model performance at test time, we introduce Hunyuan-MT-Chimera-7B, a translation model inspired by the slow thinking mode. This model integrates multiple outputs generated by the Hunyuan-MT-7B model under varying parameter settings, thereby achieving performance superior to that of conventional slow-thinking models based on Chain-of-Thought (CoT). The development of our models follows a holistic training process specifically engineered for multilingual translation, which begins with general and MT-oriented pre-training to build foundational capabilities, proceeds to Supervised Fine-Tuning (SFT) for task-specific adaptation, and culminates in advanced alignment through Reinforcement Learning (RL) and weak-to-strong RL. Through comprehensive experimentation, we demonstrate that both Hunyuan-MT-7B and Hunyuan-MT-Chimera-7B significantly outperform all translation-specific models of comparable parameter size and most of the SOTA large models, particularly on the task of translation between Mandarin and minority languages as well as dialects. In the WMT2025 shared task (General Machine Translation), our models demonstrate state-of-the-art performance, ranking first in 30 out of 31 language pairs. This result highlights the robustness of our models across a diverse linguistic spectrum, encompassing high-resource languages such as Chinese, English, and Japanese, as well as low-resource languages including Czech, Marathi, Estonian, and Icelandic.
RTime-QA: A Benchmark for Atomic Temporal Event Understanding in Large Multi-modal Models
May 25, 2025Understanding accurate atomic temporal event is essential for video comprehension. However, current video-language benchmarks often fall short to evaluate Large Multi-modal Models' (LMMs) temporal event understanding capabilities, as they can be effectively addressed using image-language models. In this paper, we introduce RTime-QA, a novel benchmark specifically designed to assess the atomic temporal event understanding ability of LMMs. RTime-QA comprises 822 high-quality, carefully-curated video-text questions, each meticulously annotated by human experts. Each question features a video depicting an atomic temporal event, paired with both correct answers and temporal negative descriptions, specifically designed to evaluate temporal understanding. To advance LMMs' temporal event understanding ability, we further introduce RTime-IT, a 14k instruction-tuning dataset that employs a similar annotation process as RTime-QA. Extensive experimental analysis demonstrates that RTime-QA presents a significant challenge for LMMs: the state-of-the-art model Qwen2-VL achieves only 34.6 on strict-ACC metric, substantially lagging behind human performance. Furthermore, our experiments reveal that RTime-IT effectively enhance LMMs' capacity in temporal understanding. By fine-tuning on RTime-IT, our Qwen2-VL achieves 65.9 on RTime-QA.
Hunyuan-TurboS: Advancing Large Language Models through Mamba-Transformer Synergy and Adaptive Chain-of-Thought
May 21, 2025As Large Language Models (LLMs) rapidly advance, we introduce Hunyuan-TurboS, a novel large hybrid Transformer-Mamba Mixture of Experts (MoE) model. It synergistically combines Mamba's long-sequence processing efficiency with Transformer's superior contextual understanding. Hunyuan-TurboS features an adaptive long-short chain-of-thought (CoT) mechanism, dynamically switching between rapid responses for simple queries and deep "thinking" modes for complex problems, optimizing computational resources. Architecturally, this 56B activated (560B total) parameter model employs 128 layers (Mamba2, Attention, FFN) with an innovative AMF/MF block pattern. Faster Mamba2 ensures linear complexity, Grouped-Query Attention minimizes KV cache, and FFNs use an MoE structure. Pre-trained on 16T high-quality tokens, it supports a 256K context length and is the first industry-deployed large-scale Mamba model. Our comprehensive post-training strategy enhances capabilities via Supervised Fine-Tuning (3M instructions), a novel Adaptive Long-short CoT Fusion method, Multi-round Deliberation Learning for iterative improvement, and a two-stage Large-scale Reinforcement Learning process targeting STEM and general instruction-following. Evaluations show strong performance: overall top 7 rank on LMSYS Chatbot Arena with a score of 1356, outperforming leading models like Gemini-2.0-Flash-001 (1352) and o4-mini-2025-04-16 (1345). TurboS also achieves an average of 77.9% across 23 automated benchmarks. Hunyuan-TurboS balances high performance and efficiency, offering substantial capabilities at lower inference costs than many reasoning models, establishing a new paradigm for efficient large-scale pre-trained models.
FiLA-Video: Spatio-Temporal Compression for Fine-Grained Long Video Understanding
Apr 29, 2025Recent advancements in video understanding within visual large language models (VLLMs) have led to notable progress. However, the complexity of video data and contextual processing limitations still hinder long-video comprehension. A common approach is video feature compression to reduce token input to large language models, yet many methods either fail to prioritize essential features, leading to redundant inter-frame information, or introduce computationally expensive modules.To address these issues, we propose FiLA(Fine-grained Vision Language Model)-Video, a novel framework that leverages a lightweight dynamic-weight multi-frame fusion strategy, which adaptively integrates multiple frames into a single representation while preserving key video information and reducing computational costs. To enhance frame selection for fusion, we introduce a keyframe selection strategy, effectively identifying informative frames from a larger pool for improved summarization. Additionally, we present a simple yet effective long-video training data generation strategy, boosting model performance without extensive manual annotation. Experimental results demonstrate that FiLA-Video achieves superior efficiency and accuracy in long-video comprehension compared to existing methods.
Reversed in Time: A Novel Temporal-Emphasized Benchmark for Cross-Modal Video-Text Retrieval
Dec 26, 2024
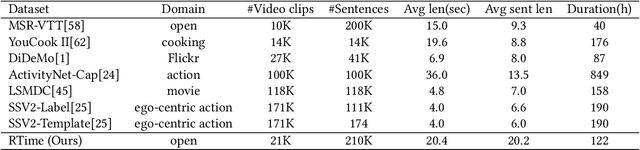
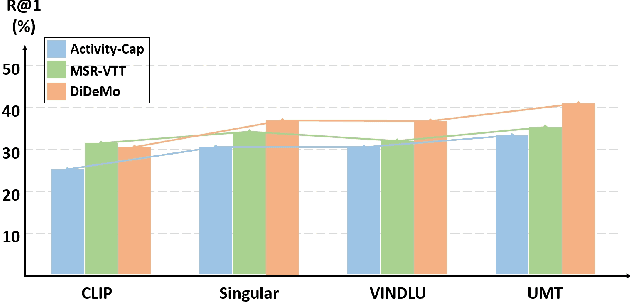
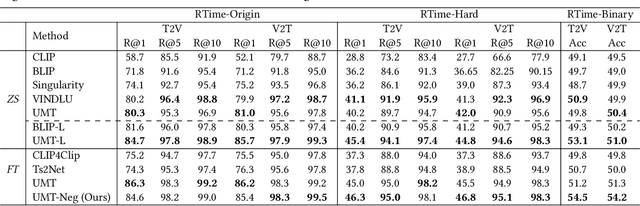
Cross-modal (e.g. image-text, video-text) retrieval is an important task in information retrieval and multimodal vision-language understanding field. Temporal understanding makes video-text retrieval more challenging than image-text retrieval. However, we find that the widely used video-text benchmarks have shortcomings in comprehensively assessing abilities of models, especially in temporal understanding, causing large-scale image-text pre-trained models can already achieve comparable zero-shot performance with video-text pre-trained models. In this paper, we introduce RTime, a novel temporal-emphasized video-text retrieval dataset. We first obtain videos of actions or events with significant temporality, and then reverse these videos to create harder negative samples. We then recruit annotators to judge the significance and reversibility of candidate videos, and write captions for qualified videos. We further adopt GPT-4 to extend more captions based on human-written captions. Our RTime dataset currently consists of 21k videos with 10 captions per video, totalling about 122 hours. Based on RTime, we propose three retrieval benchmark tasks: RTime-Origin, RTime-Hard, and RTime-Binary. We further enhance the use of harder-negatives in model training, and benchmark a variety of video-text models on RTime. Extensive experiment analysis proves that RTime indeed poses new and higher challenges to video-text retrieval. We release our RTime dataset\footnote{\url{https://github.com/qyr0403/Reversed-in-Time}} to further advance video-text retrieval and multimodal understanding research.
MiMoTable: A Multi-scale Spreadsheet Benchmark with Meta Operations for Table Reasoning
Dec 16, 2024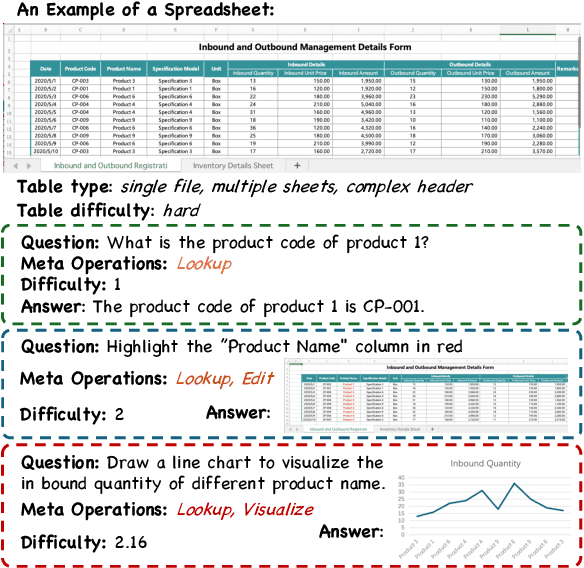
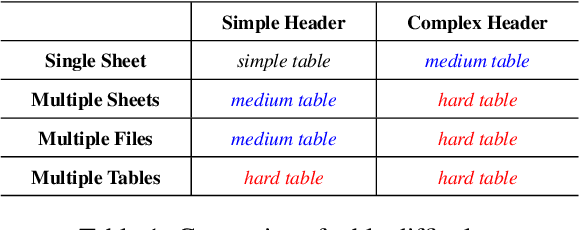

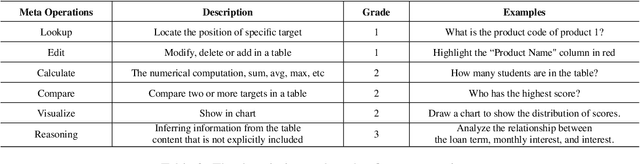
Extensive research has been conducted to explore the capability of Large Language Models (LLMs) for table reasoning and has significantly improved the performance on existing benchmarks. However, tables and user questions in real-world applications are more complex and diverse, presenting an unignorable gap compared to the existing benchmarks. To fill the gap, we propose a \textbf{M}ult\textbf{i}-scale spreadsheet benchmark with \textbf{M}eta \textbf{o}perations for \textbf{Table} reasoning, named as MiMoTable. Specifically, MiMoTable incorporates two key features. First, the tables in MiMoTable are all spreadsheets used in real-world scenarios, which cover seven domains and contain different types. Second, we define a new criterion with six categories of meta operations for measuring the difficulty of each question in MiMoTable, simultaneously as a new perspective for measuring the difficulty of the existing benchmarks. Experimental results show that Claude-3.5-Sonnet achieves the best performance with 77.4\% accuracy, indicating that there is still significant room to improve for LLMs on MiMoTable. Furthermore, we grade the difficulty of existing benchmarks according to our new criteria. Experiments have shown that the performance of LLMs decreases as the difficulty of benchmarks increases, thereby proving the effectiveness of our proposed new criterion.
GCUNet: A GNN-Based Contextual Learning Network for Tertiary Lymphoid Structure Semantic Segmentation in Whole Slide Image
Dec 09, 2024We focus on tertiary lymphoid structure (TLS) semantic segmentation in whole slide image (WSI). Unlike TLS binary segmentation, TLS semantic segmentation identifies boundaries and maturity, which requires integrating contextual information to discover discriminative features. Due to the extensive scale of WSI (e.g., 100,000 \times 100,000 pixels), the segmentation of TLS is usually carried out through a patch-based strategy. However, this prevents the model from accessing information outside of the patches, limiting the performance. To address this issue, we propose GCUNet, a GNN-based contextual learning network for TLS semantic segmentation. Given an image patch (target) to be segmented, GCUNet first progressively aggregates long-range and fine-grained context outside the target. Then, a Detail and Context Fusion block (DCFusion) is designed to integrate the context and detail of the target to predict the segmentation mask. We build four TLS semantic segmentation datasets, called TCGA-COAD, TCGA-LUSC, TCGA-BLCA and INHOUSE-PAAD, and make the former three datasets (comprising 826 WSIs and 15,276 TLSs) publicly available to promote the TLS semantic segmentation. Experiments on these datasets demonstrate the superiority of GCUNet, achieving at least 7.41% improvement in mF1 compared with SOTA.