 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContribution-aware Token Compression for Efficient Video Understanding via Reinforcement Learning
Feb 02, 2026Video large language models have demonstrated remarkable capabilities in video understanding tasks. However, the redundancy of video tokens introduces significant computational overhead during inference, limiting their practical deployment. Many compression algorithms are proposed to prioritize retaining features with the highest attention scores to minimize perturbations in attention computations. However, the correlation between attention scores and their actual contribution to correct answers remains ambiguous. To address the above limitation, we propose a novel \textbf{C}ontribution-\textbf{a}ware token \textbf{Co}mpression algorithm for \textbf{VID}eo understanding (\textbf{CaCoVID}) that explicitly optimizes the token selection policy based on the contribution of tokens to correct predictions. First, we introduce a reinforcement learning-based framework that optimizes a policy network to select video token combinations with the greatest contribution to correct predictions. This paradigm shifts the focus from passive token preservation to active discovery of optimal compressed token combinations. Secondly, we propose a combinatorial policy optimization algorithm with online combination space sampling, which dramatically reduces the exploration space for video token combinations and accelerates the convergence speed of policy optimization. Extensive experiments on diverse video understanding benchmarks demonstrate the effectiveness of CaCoVID. Codes will be released.
Single Domain Generalization for Few-Shot Counting via Universal Representation Matching
May 22, 2025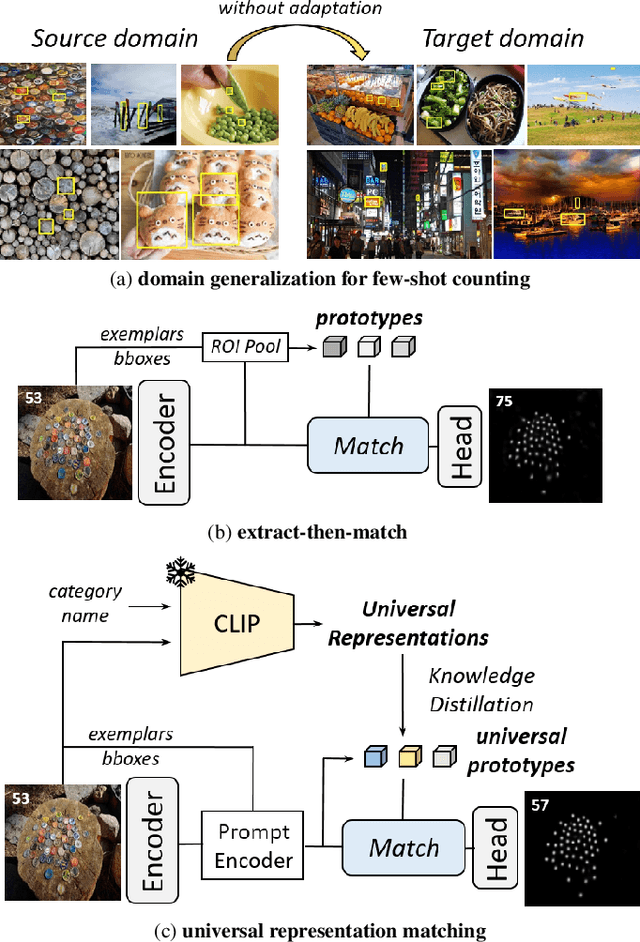
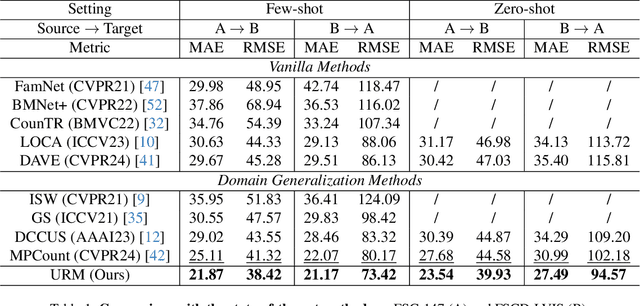

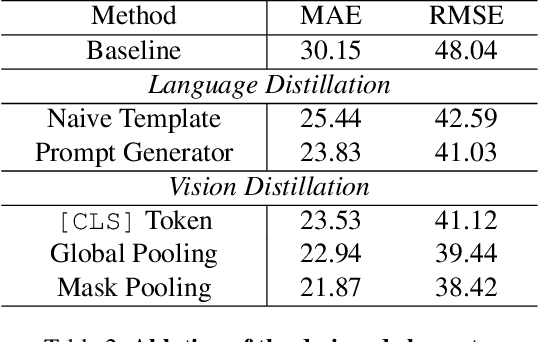
Few-shot counting estimates the number of target objects in an image using only a few annotated exemplars. However, domain shift severely hinders existing methods to generalize to unseen scenarios. This falls into the realm of single domain generalization that remains unexplored in few-shot counting. To solve this problem, we begin by analyzing the main limitations of current methods, which typically follow a standard pipeline that extract the object prototypes from exemplars and then match them with image feature to construct the correlation map. We argue that existing methods overlook the significance of learning highly generalized prototypes. Building on this insight, we propose the first single domain generalization few-shot counting model, Universal Representation Matching, termed URM. Our primary contribution is the discovery that incorporating universal vision-language representations distilled from a large scale pretrained vision-language model into the correlation construction process substantially improves robustness to domain shifts without compromising in domain performance. As a result, URM achieves state-of-the-art performance on both in domain and the newly introduced domain generalization setting.
FiLA-Video: Spatio-Temporal Compression for Fine-Grained Long Video Understanding
Apr 29, 2025Recent advancements in video understanding within visual large language models (VLLMs) have led to notable progress. However, the complexity of video data and contextual processing limitations still hinder long-video comprehension. A common approach is video feature compression to reduce token input to large language models, yet many methods either fail to prioritize essential features, leading to redundant inter-frame information, or introduce computationally expensive modules.To address these issues, we propose FiLA(Fine-grained Vision Language Model)-Video, a novel framework that leverages a lightweight dynamic-weight multi-frame fusion strategy, which adaptively integrates multiple frames into a single representation while preserving key video information and reducing computational costs. To enhance frame selection for fusion, we introduce a keyframe selection strategy, effectively identifying informative frames from a larger pool for improved summarization. Additionally, we present a simple yet effective long-video training data generation strategy, boosting model performance without extensive manual annotation. Experimental results demonstrate that FiLA-Video achieves superior efficiency and accuracy in long-video comprehension compared to existing methods.
DearKD: Data-Efficient Early Knowledge Distillation for Vision Transformers
Apr 28, 2022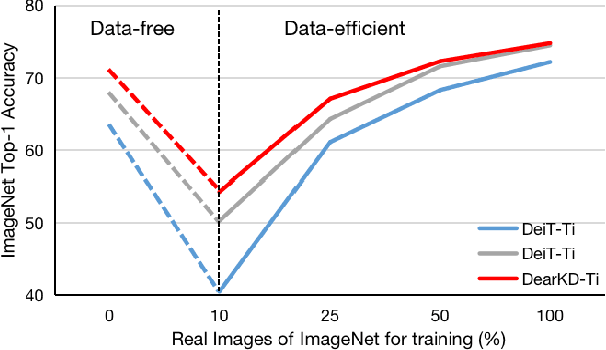
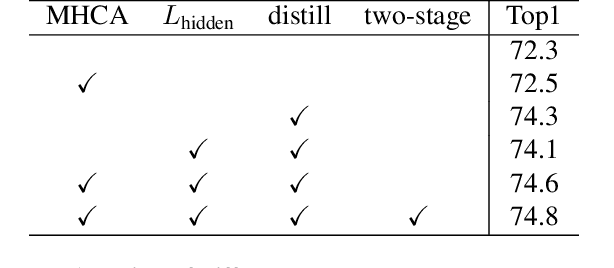
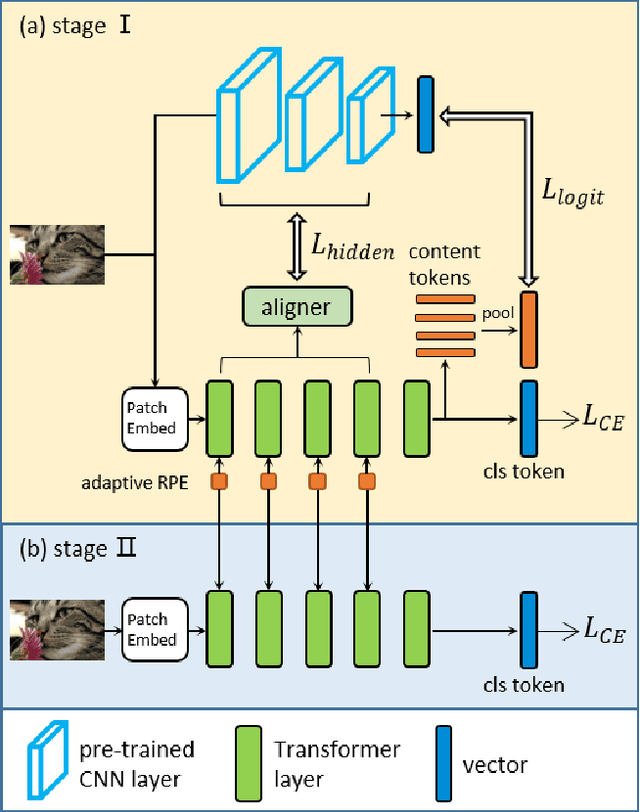
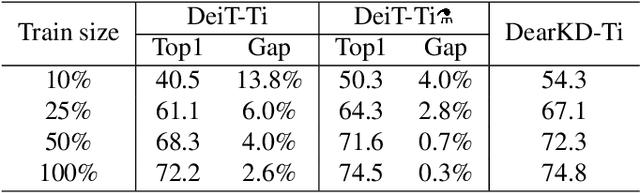
Transformers are successfully applied to computer vision due to their powerful modeling capacity with self-attention. However, the excellent performance of transformers heavily depends on enormous training images. Thus, a data-efficient transformer solution is urgently needed. In this work, we propose an early knowledge distillation framework, which is termed as DearKD, to improve the data efficiency required by transformers. Our DearKD is a two-stage framework that first distills the inductive biases from the early intermediate layers of a CNN and then gives the transformer full play by training without distillation. Further, our DearKD can be readily applied to the extreme data-free case where no real images are available. In this case, we propose a boundary-preserving intra-divergence loss based on DeepInversion to further close the performance gap against the full-data counterpart. Extensive experiments on ImageNet, partial ImageNet, data-free setting and other downstream tasks prove the superiority of DearKD over its baselines and state-of-the-art methods.
OH-Former: Omni-Relational High-Order Transformer for Person Re-Identification
Sep 23, 2021
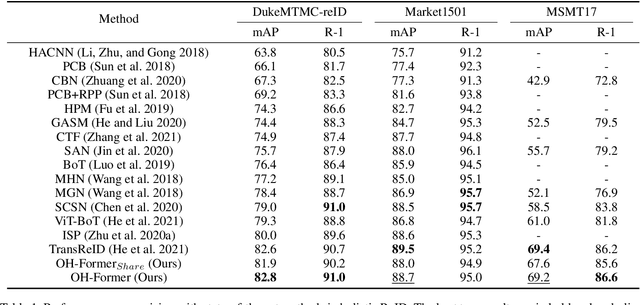
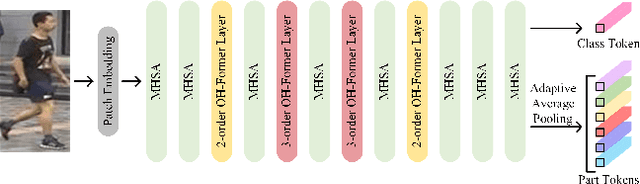
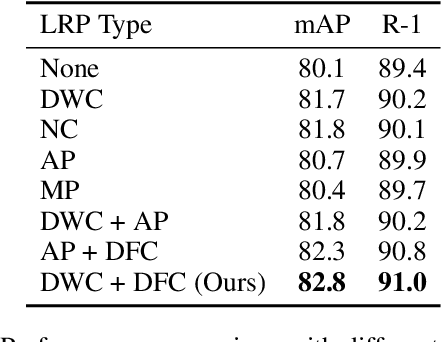
Transformers have shown preferable performance on many vision tasks. However, for the task of person re-identification (ReID), vanilla transformers leave the rich contexts on high-order feature relations under-exploited and deteriorate local feature details, which are insufficient due to the dramatic variations of pedestrians. In this work, we propose an Omni-Relational High-Order Transformer (OH-Former) to model omni-relational features for ReID. First, to strengthen the capacity of visual representation, instead of obtaining the attention matrix based on pairs of queries and isolated keys at each spatial location, we take a step further to model high-order statistics information for the non-local mechanism. We share the attention weights in the corresponding layer of each order with a prior mixing mechanism to reduce the computation cost. Then, a convolution-based local relation perception module is proposed to extract the local relations and 2D position information. The experimental results of our model are superior promising, which show state-of-the-art performance on Market-1501, DukeMTMC, MSMT17 and Occluded-Duke datasets.